 Python之王
Python之王




我们可以用更好的Python运行环境或运行时优化来提升Python的速度,其中最成熟、使用最简单的当属。用PyPy,可以在不改变源代码的情况下,获得平均3-4倍的性能提升。本文将带大家学习如何用PyPy加速Python程序。

什么是PyPy
Python解释器有多种实现,比如
- C语言实现的CPython;- Java实现的Jython ;- .NET实现的IronPython ;- Python实现的PyPy; CPython是Python最原始的实现,也是迄今为止最流行和维护最多的实现。当我们说Python时,通常指的是CPython。你现在使用的Python大概率就是CPython。
然而,因为Python是高级解释型语言,CPython有其局限性,无法获得速度上的优势。而这恰恰是PyPy发挥优势的地方。由于PyPy遵循Python语言规范,不需要更改代码库,并且可以通过JIT显著提高速度。
这里您可能会问,既然CPython和PyPy实现的是相同的语法,为什么CPython不可以实现PyPy的强大功能?原因是,实现这些功能需要对源代码进行巨大的更改,这将是一项庞大到近乎不可能完成的任务。
作为Python的使用者(非维护者),这里我们不过多的深入到Python的底层和源代码,我们先看一下PyPy怎么用。
安装PyPy
有2种方法可以安装PyPy:
用包管理器安装
很多操作系统和Linux发行版都带有PyPy包。
如果是Ubuntu,可以用apt安装
$ sudo add-apt-repository ppa:pypy/ppa
$ sudo apt update
$ sudo apt install pypy3
如果是CentOS,可以用yum安装,以CentOS 7.4为例
$ rpm -ivh http://dl.fedoraproject.org/pub/epel/7/x86_64/Packages/e/epel-release-7-11.noarch.rpm
$ yum -y install pypy-libs pypy pypy-devel
如果是MacOS,可以通过 安装
$ brew install pypy3
用预编译好的安装包安装
预编译好的安装包可以通过下载,你可以根据你的环境下载对应的安装包。

如果是Windows系统,下载好安装包后解压安装就可以了。
如果是Linux,直接解压安装包,
$ tar xf pypy3.9-v7.3.9-linux64.tar.bz2
$ ./pypy3.9-v7.3.9-linux64/bin/pypy3
Python 3.9.10 (?, Mar 16 2022, 16:03:21)
[PyPy 7.3.9 with GCC 4.2.1]
Type "help", "copyright", "credits" or "license" for more information.
然后在/usr/local/bin中创建一个pypy的链接。
使用PyPy
PyPy安装好后,我们实际测试一下PyPy对Python程序运行速度的提升。我们的测试脚本test.py如下:
total = 0
for i in range(1, 10000):
for j in range(1, 10000):
total += i + j
print(f"The result is {total}")
上面的代码用了双重循环,每重循环从[1, 9999],然后输出累加结果。我们用cProfile看一下执行效率:
用CPython执行
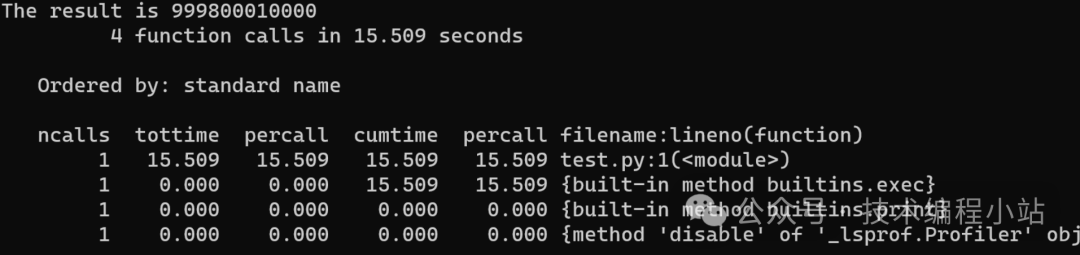
$ python -m cProfile test.py
用PyPy执行
$ pypy3 -m cProfile test.py
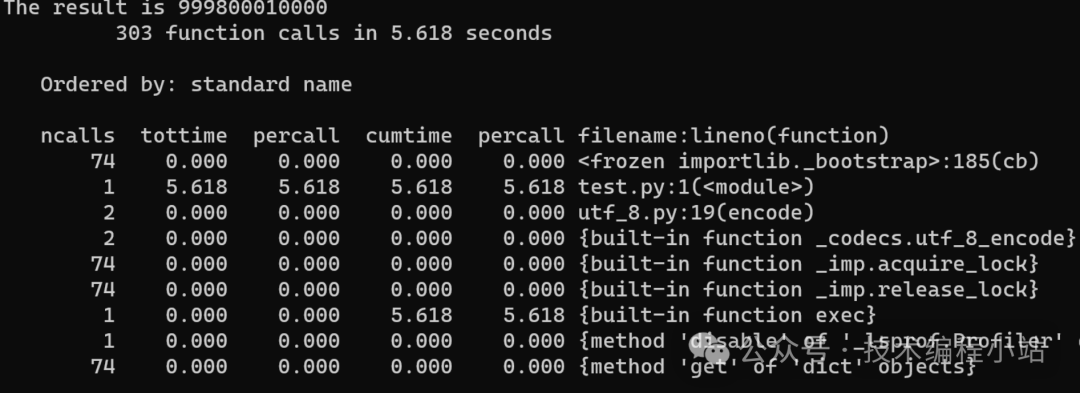
通过上面的简单测试我们能看到,CPython虽然运行时栈很简单,只有4个函数调用,但是总共用时15.509秒;而PyPy调用了303个函数,但总共用时5.618秒。PyPy比CPython快3倍!
更多性能对比可以参看PyPy的,这里有大量性能对比数据。
这里需要注意的是,PyPy对代码速度的提升不是稳定一成不变的,而是跟代码的功能有密切关系。某些情况下PyPy的速度反而更慢。但是平均来讲PyPy比CPython快4.3倍。
PyPy的构建
我们习惯说PyPy是用Python写的,于是很多人以为PyPy是Python语言自举的产物。这个观点是不对的。这里我专门为大家纠正一下这个错误观念。
PyPy在建立之初有两个目标:
- 创建一个能够为动态语言生成解析器的动态语言框架;1. 其次才是用这个框架实现一个Python解析器。 第二点目标的产物就是PyPy,上一节我们已经体验了PyPy的性能威力。第一点目标中的动态语言框架叫,PyPy就是用RPython写的。
开篇提到的PyPy是用Python写的其实不准确,这只是习惯性的简略说法。我们习惯说PyPy是用Python写的是因为RPython跟Python有着相同的语法,PyPy实际是用RPython写的。为了解除大家这里的迷惑,这里简单介绍一下PyPy是怎样开发出来的:
- 首先用RPython写PyPy的源代码;1. 然后用 翻译转换源代码,让代码更高效。这个过程会将源代码编译成机器码。这就是为什么Windows, Mac,Linux要分别下载对应操作系统的安装包;1. 生成二进制可执行文件,这就是pypy3。 为了避免混淆,这里梳理一下几个易混淆的名词:
- PyPy指的Python解释执行器,是Python的一个具体实现。- RPython是一门语言,语法跟Python一样。- RPython翻译工具是生成动态语言解释执行器的框架。PyPy是用RPython写的,用RPython翻译工具生成的一个Python实现。
PyPy性能优化关键技术
JIT(Just-In-Time)编译
你可能之前听说过JIT技术,他是一种介于编译型语言(比如C)和解释型语言(比如Python)之间的中间语言技术。编译型语言编译器会预先将源代码编译成二进制机器码,CPU可以直接执行,因此执行速度快,但缺点是可以执行差;而解释型语言可移植性好,但执行速度慢,需要解释器一行一行解释执行。
编译型语言和解释型语言是天平的两端,一个的优势就是另外一个的劣势。有没有办法能将兼得二者的优势呢?于是就出现了中间解决方案。Python就结合了编译型语言和解释型语言,先将源代码编译成中间字节码,然后再由CPython解释执行。这样即能兼顾可以执行,同时性能比纯解释型语言好很多。
然而,即便这样,中间字节码的执行效率依然无法与编译成机器码同日而语。其中一个原因是编译器可以对编译的机器码做很多优化,而自己码能做的就很有限。
此时JIT技术就应运而生,它试图整合机器码和解释器二者的优势。简而言之,JIT通过如下步骤提升程序性能:
- 识别代码中最常用的部分,例如循环中的函数;1. 在运行时将这些部分转换为机器码;1. 优化生成的机器码;1. 用优化过的机器码替换原来的实现。 下图是编译型语言、解释型语言和JIT编译的开发、执行流程对比图
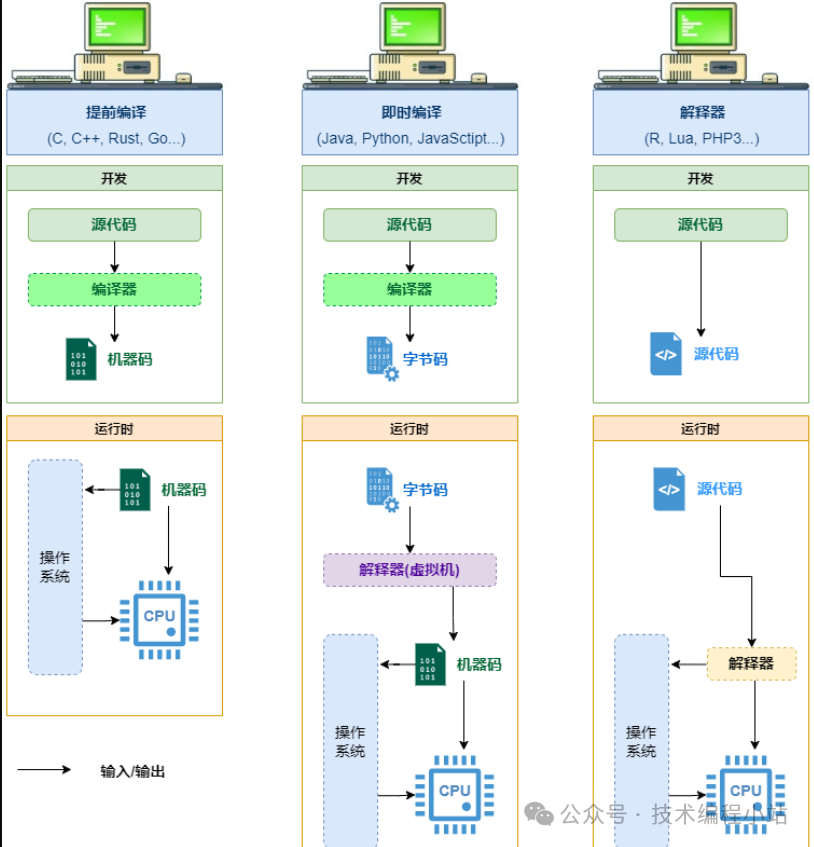
我们前面给出的示例程序中使用了双重循环,PyPy检测到相同的操作正在反复执行,于是将其编译成机器代码并加以优化,然后用优化后的机器码替换原来的Python实现,从而后面的执行全部执行的是速度更快的机器码。这就是为什么用PyPy执行速度有如此大的提高。
垃圾回收
我们都知道,在程序中创建变量、方法以及一切对象都需要分配内存。C和C++需要我们手动管理内存的分配和释放,而Python提供了垃圾回收(GC)机制自动帮我们管理内存。
垃圾回收有多种实现方法和策略。
CPython用的技术叫“引用计数”。简单的说就是,当对象被引用时引用计数增加,对象被取消引用时引用计数减少。当引用计数为0时,CPython会自动调用该对象的内存释放函数释放内存。这是一种简单有效的技术,很多编程语言(如Objective-C,Swift, Rust中的Rc/Arc)都采用这种方法管理内存。但它存在一个缺点,那就是“全局暂停” 。
想象一下,当一个大型对象树的根节点引用计数变为0时,此时需要释放树上所有相关对象。此时程序需要大量执行内存释放函数,无法执行任何其他功能,从而导致程序像暂停了一样。这个现象就叫“全局暂停”。
除了大量释放内存会带来全局暂停外,“循环引用”会带来更严重的全局暂停。
循环引用顾名思义就是A引用了B,B又引用了A,他们构成了一个环。此时要释放A需要解除B对它的引用,而要释放B需要解除A对它的引用,这样就构成了无限循环。
为了解决循环引用问题,CPython引入了。循环垃圾回收器会从已知的根开始遍历内存中的所有对象,然后识别所有可到达的对象,并释放无法到达的对象,因为这些不可达的对象已经不在树上,说明他们不会再被用到。这样就解决了循环引用的问题。然而,当内存中存在大量对象时,循环垃圾回收会产生更明显的暂停。
而PyPy在内存管理上没有采用“引用计数”技术,而是采用了“循环查找器”技术。循环查找器会周期性地从根开始遍历活动对象,不依赖对象的引用计数,从而降低了内存管理上的花销。
此外,PyPy没有像CPython那样在一个主任务中完成所有工作,而是将工作拆分为数量可变的子任务,然后运行每个子任务,直到所有子任务都运行完成。在每个子任务完成后都会执行一次垃圾回收,这样做可以避免内存中出现大型对象树,从而减少垃圾回收带来得全局暂停。
PyPy的局限
PyPy性能这么好为什么不像CPython那么普及?这是因为PyPy存在一些局限。这些局限导致有些任务场景下PyPy并不适用。
C语言扩展支持不佳
PyPy非常适合运行纯Python程序,如果程序中用到了C语言扩展,PyPy的运行速度比CPython慢很多。这是因为PyPy对C语言扩展的支持不完整,也缺乏相应的优化。并且,对C语言扩展的支持需要PyPy执行引用计数,这进一步减缓了PyPy的速度。
对于这一点,PyPy团队的建议是移除C语言扩展,用纯Python代码来实现,这样就可以使用JIT优化。否则,就乖乖用CPython。
尽管如此,PyPy核心团队正在研究C语言扩展的移植。一些包已经移植到PyPy,工作速度一样很快。
不适合短时间运行场景
举个例子,假如你要去家旁边的超时购物,你会步行去还是开车去?开车速度肯定比不行速度快,但开车要去停车场、发动车子,到了目的地要找停车位停车;回程还要缴费、重新将车停好。这些开车带来的附加工作所消耗的时间可能比步行过去还要多。
PyPy也是如此。当我们用PyPy运行Python脚本时,PyPy会做大量工作让程序能跑得快一点。但如果程序运行时间很短,那么PyPy为速度优化而做出的开销反而会让它的总运行时间比CPython更长。我们可以用之前的例子,将10000改为100,在对比一下CPython和PyPy的运行时间:
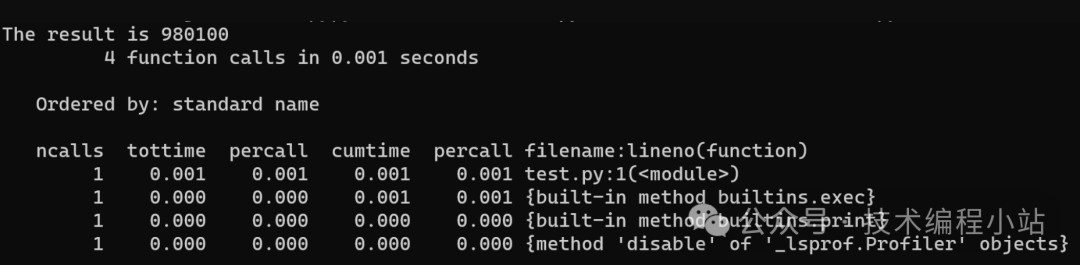
用CPython执行
用PyPy执行
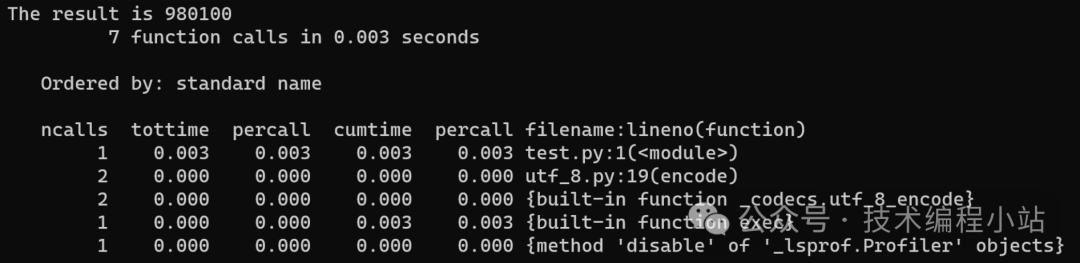
从上面的输出可以看出,CPython用时0.001秒,而PyPy用时0.003秒。这次变成CPython比PyPy快三倍!
但如果我们的程序需要长时间运行,那么PyPy为速度优化做出的开销就很值得,能换来更短的总运行时间。
无法实现提前编译
如前面所讲,PyPy不是一个完全编译的Python实现。它会在运行时编译Python代码,但不是Python代码的编译器。由于Python固有的动态性,不可能将Python编译成独立的二进制文件并重用它。
这就导致PyPy作为一种运行时解释器,他的性能比纯解释器(比如CPython)要快,但跟编译型语言(比如C语言)比还是慢很多。
总结
PyPy是CPython的一个快速而强大的替代品。用PyPy,你可以在不改动源代码的情况下获得约3倍左右的速度提升。然而,PyPy不是银弹,它有其局限性,实际项目中用PyPy是否能获得实质性的提升要看具体代码功能的情况,建议可以用PyPy做一下测试,可能会收获显著的性能提升。

