 算法进阶
算法进阶




近期,中国人工智能协会发布了一份名为《中国人工智能大模型技术白皮书》的报告,该报告
全面梳理了大模型技术的演进历程,深入探讨了
关键技术要素,并详细剖析了当前面临的挑战以及未来展望。
为了让大家更好地了解这份报告的核心内容,本文我为大家简要总结了一下,并文末附上原文以供深入阅读。
目录
第 1 章 大模型技术概述 ...................................5
1.1 大模型技术的发展历程 ......................5
1.2 大模型技术的生态发展 ......................9
1.3 大模型技术的风险与挑战 ................11
第 2 章 语言大模型技术 .................................13
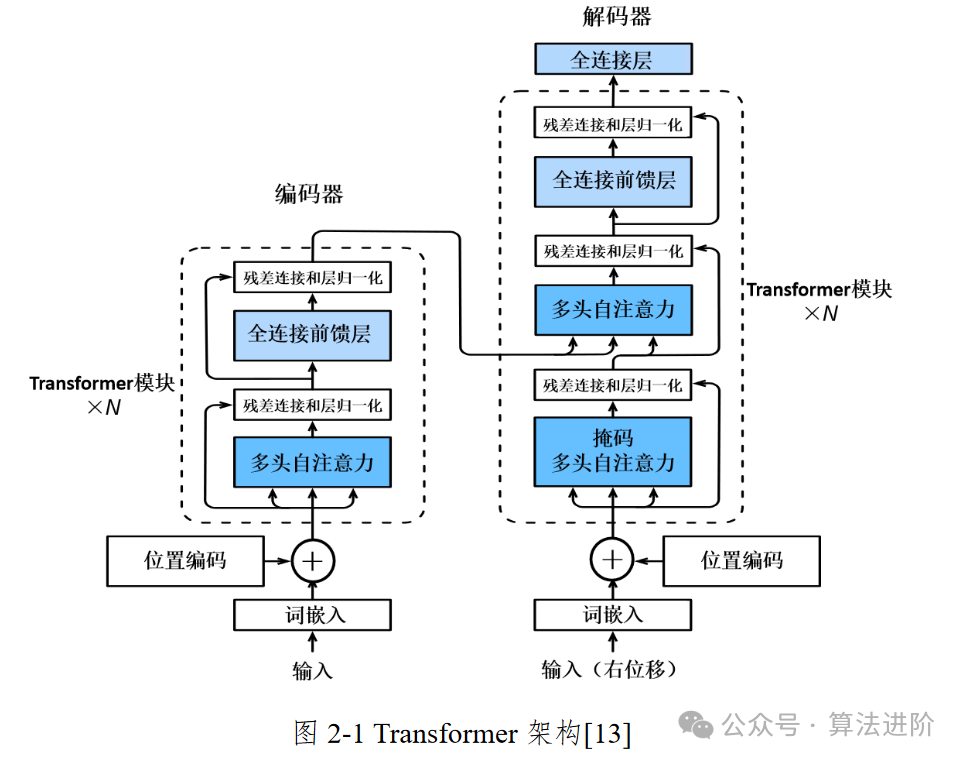
2.1 Transformer 架构.................................13
2.2 语言大模型架构 ................................17
2.2.1 掩码语言建模 .............................17
2.2.2 自回归语言建模 .........................18
2.2.3 序列到序列建模 .........................18
2.3 语言大模型关键技术 ........................19
2.3.1 语言大模型的预训练 .................19
2.3.2 语言大模型的适配微调 .............21
2.3.3 语言大模型的提示学习 .............24
2.3.4 语言大模型的知识增强 .............26
2.4.5 语言大模型的工具学习 .............27
第 3 章 多模态大模型技术 .............................29
3.1 多模态大模型的技术体系 ................29
3.1.1 面向理解任务的多模态大模型 .29
3.1.2 面向生成任务的多模态大模型 .31
3.1.3 兼顾理解和生成任务的多模态大模型............................33
3.1.4 知识增强的多模态大模型 .........35
3.2 多模态大模型的关键技术 ................36
3.2.1 多模态大模型的网络结构设计 .363
3.2.2 多模态大模型的自监督学习优化 ....................................37
3.2.3 多模态大模型的下游任务微调适配 ................................39
第 4 章 大模型技术生态 .................................41
4.1 典型大模型平台 ................................41
4.2 典型开源大模型 ................................44
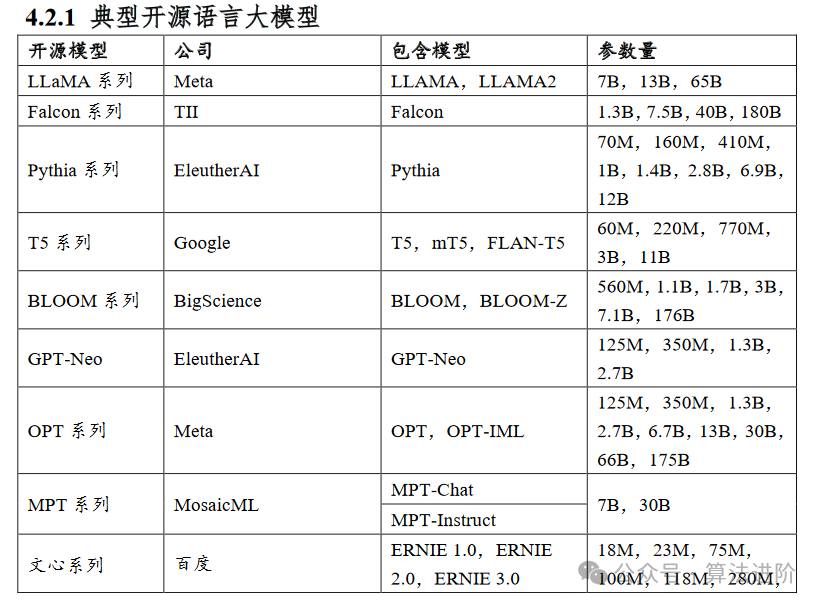
4.2.1 典型开源语言大模型 .................44
4.2.2 典型开源多模态大模型 .............53
4.3 典型开源框架与工具 ........................57
4.4 大模型的训练数据 .............................60
4.4.1 大模型的训练数据处理流程和特点 ................................60
4.4.2 大模型常用的公开数据集 .........63
第 5 章 大模型的开发训练与推理部署 .........66
5.1 大模型开发与训练 ............................66
5.2 大模型推理部署 ................................68
5.2.1 大模型压缩 .................................69
5.2.2 大模型推理与服务部署 .............70
5.3 软硬件适配与协同优化 ....................71
5.3.1 大模型的软硬件适配 .................72
5.3.2 大模型的软硬件协同优化 .........72
第 6 章 大模型应用 ..74
6.1 信息检索 .....74
6.2 新闻媒体 .....75
6.3 智慧城市 .....76
6.4 生物科技 .....76
6.5 智慧办公 .....77
6.6 影视制作 .....78
6.7 智能教育 .....784
6.8 智慧金融 .....79
6.9 智慧医疗 .....79
6.10 智慧工厂 ...79
6.11 生活服务....80
6.12 智能机器人 ......................................80
6.13 其他应用 ...80
第 7 章 大模型的安全性 .................................82
7.1 大模型安全风险引发全球广泛关注 82
7.2 大模型安全治理的政策法规和标准规范 ...............................83
7.3 大模型安全风险的具体表现 ............85
7.3.1 大模型自身的安全风险 .............85
7.3.2 大模型在应用中衍生的安全风险 ....................................86
7.4 大模型安全研究关键技术 ................88
7.4.1 大模型的安全对齐技术 .............88
7.4.2 大模型安全性评测技术 .............91
第 8 章 总结与思考 94
8.1 协同多方合作,共同推动大模型发展 ...................................95
8.2 建立大模型合规标准和评测平台 ....96
8.3 应对大模型带来的安全性挑战 ........97
8.4 开展大模型广泛适配,推动大模型技术栈自主可控...........98
大模型发展历程
自Geoffrey Hinton在2006年提出逐层无监督预训练方法,用以攻克深层网络训练难题起,深度学习已在多个领域展现出显著的优势与突破。其发展之路从早期的标注数据监督学习,逐步扩展至预训练模型的广泛应用,最终迈向了大模型的新时代。2022年底,OpenAI推出的ChatGPT凭借其卓越性能,赢得了全球范围内的瞩目,充分彰显了大模型在处理多元化场景、多样化用途以及跨学科任务时的强大实力。因此,大模型被普遍视为未来人工智能领域不可或缺的核心基础设施。
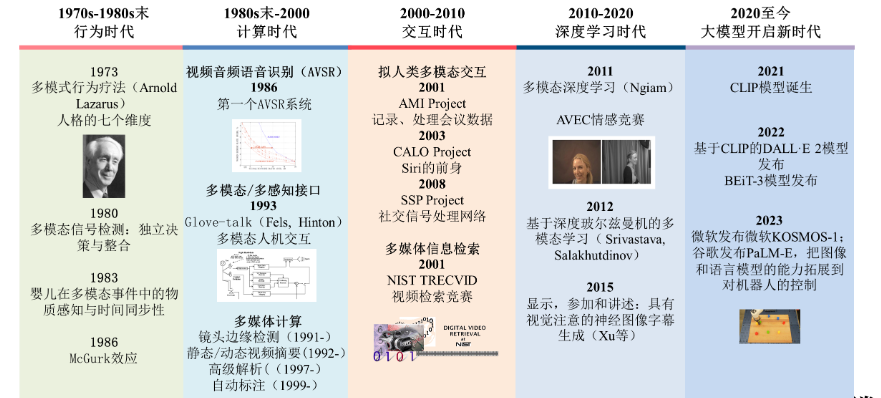
在这场技术革命的风潮中,语言大模型以其卓越的通用求解能力,成为引领潮流的领军者。它大规模预训练,吸收了丰富的语言知识与世界知识,赋予自身面向多任务的卓越才能。其发展脉络清晰可见,从统计语言模型到神经语言模型,再到预训练语言模型,直至现今的语言大模型(探索阶段),每一步都见证了技术的创新与突破。
-
统计语言模型虽然基于马尔可夫假设,但受困于数据稀疏问题,其能力受到一定限制;
-
神经语言模型的出现,犹如破晓的曙光,它利用神经网络建模语义共现关系,成功地捕获了复杂语义依赖,让语言的魅力在模型中得以绽放;
-
预训练语言模型更是采用“预训练+微调”的范式,通过自监督学习,使模型能够适配各种下游任务,展现了其强大的通用性和灵活性。
-
而大模型则基于缩放定律,简单来说,就是随着模型参数和预训练数据规模的不断增加,模型的能力与任务效果能持续提升,甚至展现出了一些小规模模型所不具备的独特“涌现能力”。
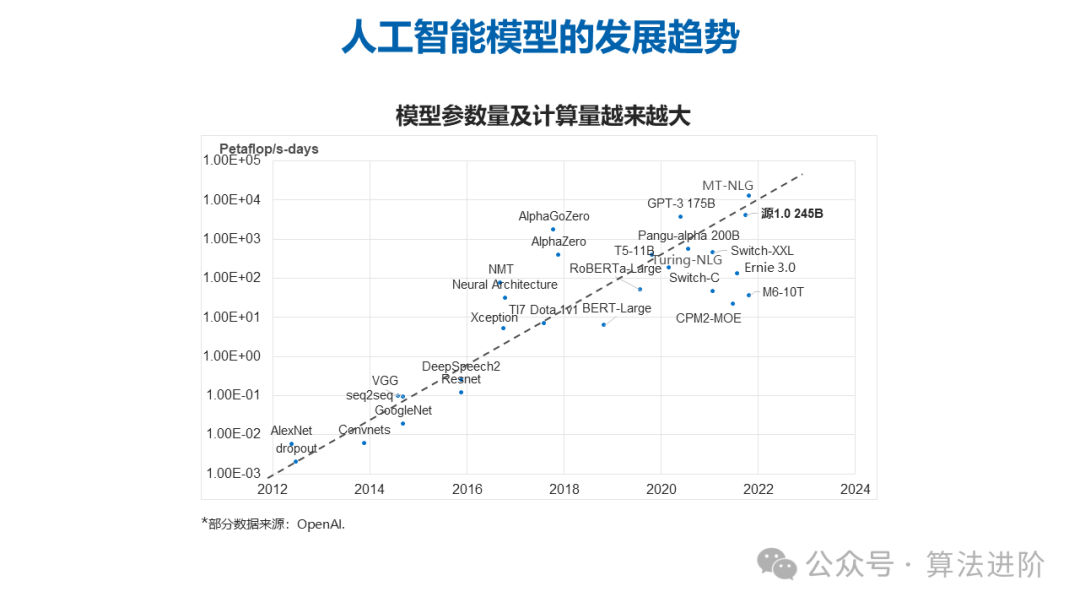
大模型应用
随着大模型时代的悄然来临,领军者如ChatGPT正在经济、法律、社会等多元化领域扮演着举足轻重的角色。OpenAI通过GPT-1、GPT-2以及GPT-3等一系列语言模型的推出,充分展现了其在不同规模参数下的卓越能力。与此同时,谷歌也不甘示弱,推出了规模庞大的PaLM模型,其5400亿参数的强大实力同样令人瞩目。当模型参数规模攀升至千亿量级时,语言大模型所展现出的多样化能力更是惊艳四座。GPT-3仅凭简洁的提示词或有限的样例,便能够游刃有余地完成各类复杂任务,其智能与灵活性令人赞叹不已。
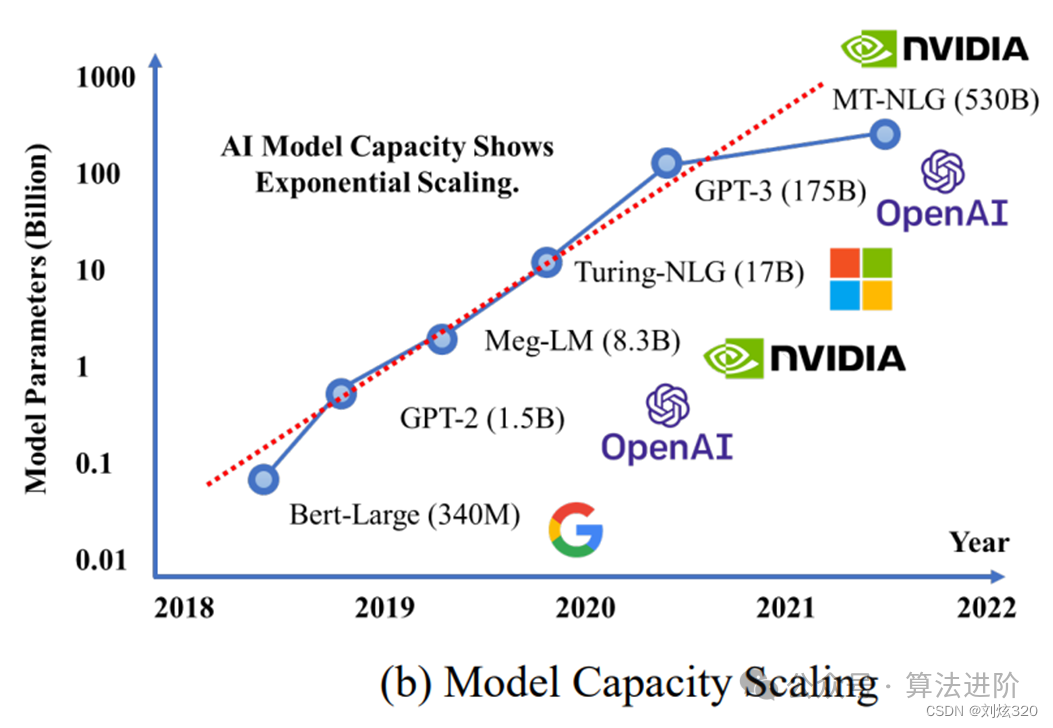
自Transformer架构亮相以来,OpenAI推出了一系列领先的语言大模型技术,如GPT-1、GPT-2、GPT-3等,它们在自然语言任务中展现了卓越性能。
CodeX的创新在于它对GPT-3的精细调整,有效地强化了代码和复杂推理的功能;InstructGPT与ChatGPT则展现了强化学习的卓越应用,凭借人类反馈,显著提升了遵循指令和解读人类偏好的能力。GPT-4更是迈向了一个新的高峰,不仅能够处理更为广阔的上下文环境,更兼具了多模态的理解力,它的逻辑推理和复杂任务处理能力也得到了极大的改进,无疑为多模态领域打开了无限的可能性。
大模型技术生态日益繁荣,多个服务平台供个人用户和商业应用使用。OpenAI API便于用户访问不同GPT模型以完成各类任务。Anthropic的Claude系列模型注重实用性、诚实性和安全性。百度文心一言则是一个基于知识增强的大模型,提供开放服务和插件机制。讯飞星火认知大模型具备开放式知识问答、多轮对话、逻辑和数学能力,以及理解和处理代码和多模态信息的能力。

大模型的开源生态极为丰富多彩,涵盖了众多开源框架与开源大模型。
例如,PyTorch和飞桨等开源框架为大规模分布式训练提供了强大的支持,而OneFlow则以其动静态图的灵活转换功能脱颖而出。
此外,DeepSpeed则通过优化内存访问,助力训练更大规模的模型。
在开源大模型方面,LLaMA、Falcon和GLM等模型降低了研究门槛,推动了应用的繁荣发展。
特别值得一提的是,Baichuan系列模型不仅支持中英双语,更采用高质量训练数据,展现出卓越的性能,同时还开源了多种量化版本。
而CPM系列在中文NLP任务上的出色表现,也赢得了广泛的赞誉。
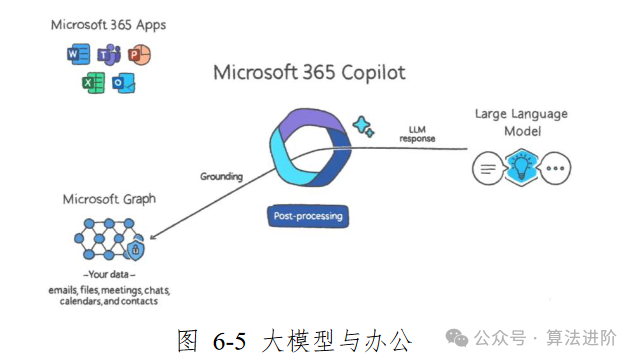
大模型技术的应用领域宽广无边,它为各行各业注入了前所未有的新活力。无论是日常的办公活动、新闻传媒、影视制作,还是市场营销、娱乐业、军事决策,乃至教育领域、金融行业和医疗健康等领域,大模型技术都能大幅度地降低生产成本,显著提升作品质量,助力产品营销,增强决策能力。在教育领域,大模型使得教育方式更加个性化和智能化;在金融行业,它极大地提高了服务质量;在医疗领域,大模型技术为医疗机构的诊疗全过程注入了强大的动力。
更重要的是,大模型技术被看作是未来人工智能应用中的核心基础设施,它有能力引领上下游产业的革新,形成协同发展的生态系统,对经济、社会和安全等领域的智能化升级起到至关重要的支撑作用。通过大模型技术的应用,我们可以期待一个更加智能、高效和美好的未来。
大模型的风险和挑战
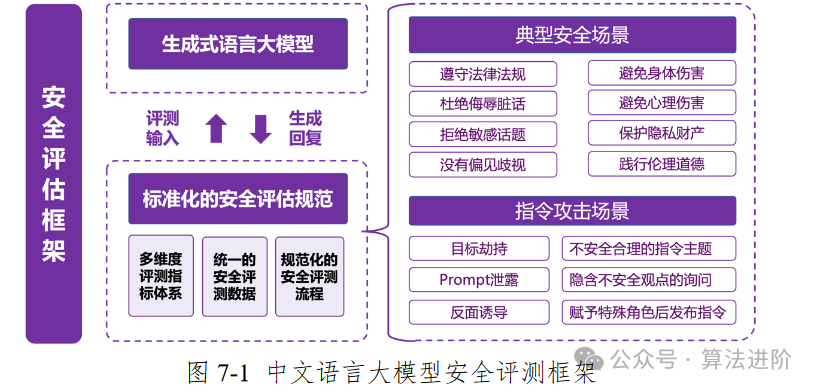
尽管如此,大模型技术在推进中仍面临一系列风险与挑战。其可靠性尚未获得全面保障,合成内容在事实性与时效性上仍有待提升。大模型的可解释性相对较弱,其工作原理尚难以深入剖析。此外,应用大模型的部署成本高昂,涉及大量的训练和推理计算,功耗高,应用成本高,且端侧推理存在延迟等问题。在大数据匮乏的情境下,大模型的迁移能力受到限制,其鲁棒性和泛化性面临严峻挑战。更为严重的是,大模型还存在被滥用于制造虚假信息、恶意引导行为等衍生技术风险,以及安全与隐私问题,这些问题都需要我们高度关注和积极应对。
总结
大模型技术,以其无限广阔的应用前景和巨大潜力,正逐渐崭露头角,成为技术发展的璀璨明珠。然而,随之而来的挑战亦不容忽视。为了推动这一技术的发展,我们必须致力于攻克可靠性、可解释性的难题,同时,提升数据质量与数量也显得尤为迫切。在应用部署方面,降低成本并增强迁移能力至关重要,而强化安全与隐私保护更是重中之重。此外,探索更为贴合实际、具备落地价值的应用场景,同样是我们需要不断努力的方向。这些挑战与机遇并存,将共同决定大模型技术未来的广泛应用与发展命运。
关注↓回复【 白皮书 】,可下载大模型白皮书

