
pplei
后端
· 1月前
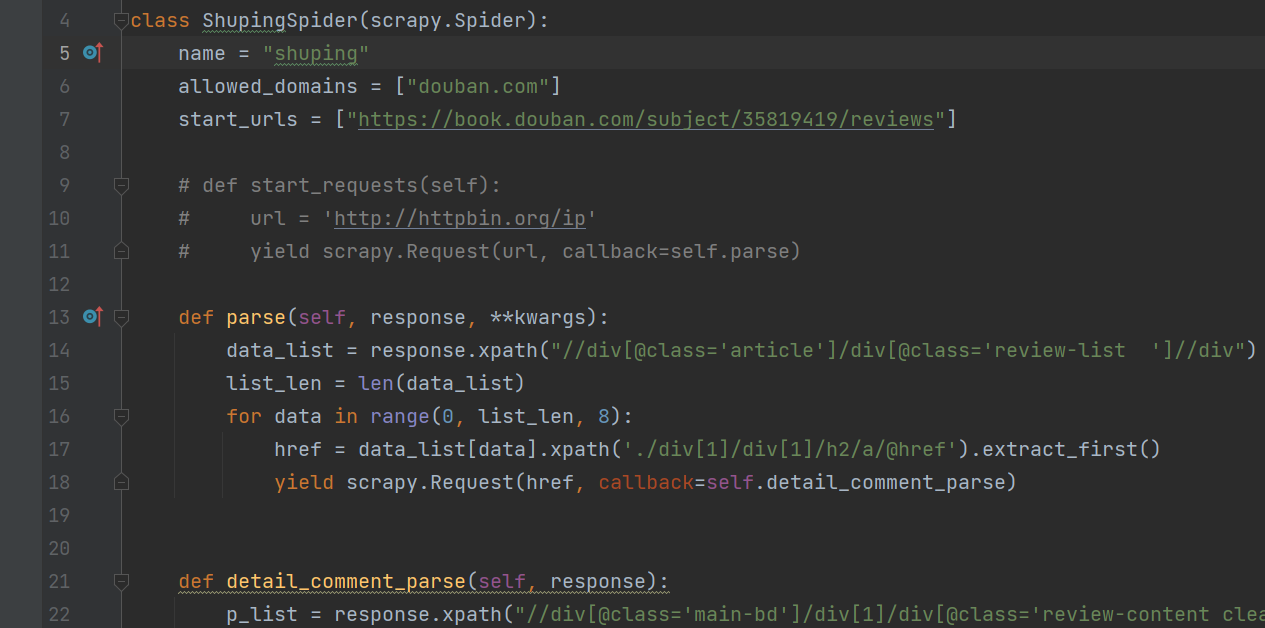
1利用python scrapy爬虫框架进行数据获取,豆瓣书评需要完善的伪装才可以获取到数据,...
豆瓣书评爬虫
https://www.proginn.com/w/1465190
资源下载
 分享
分享
 点赞
点赞
 评论
评论
pplei
后端
· 1月前
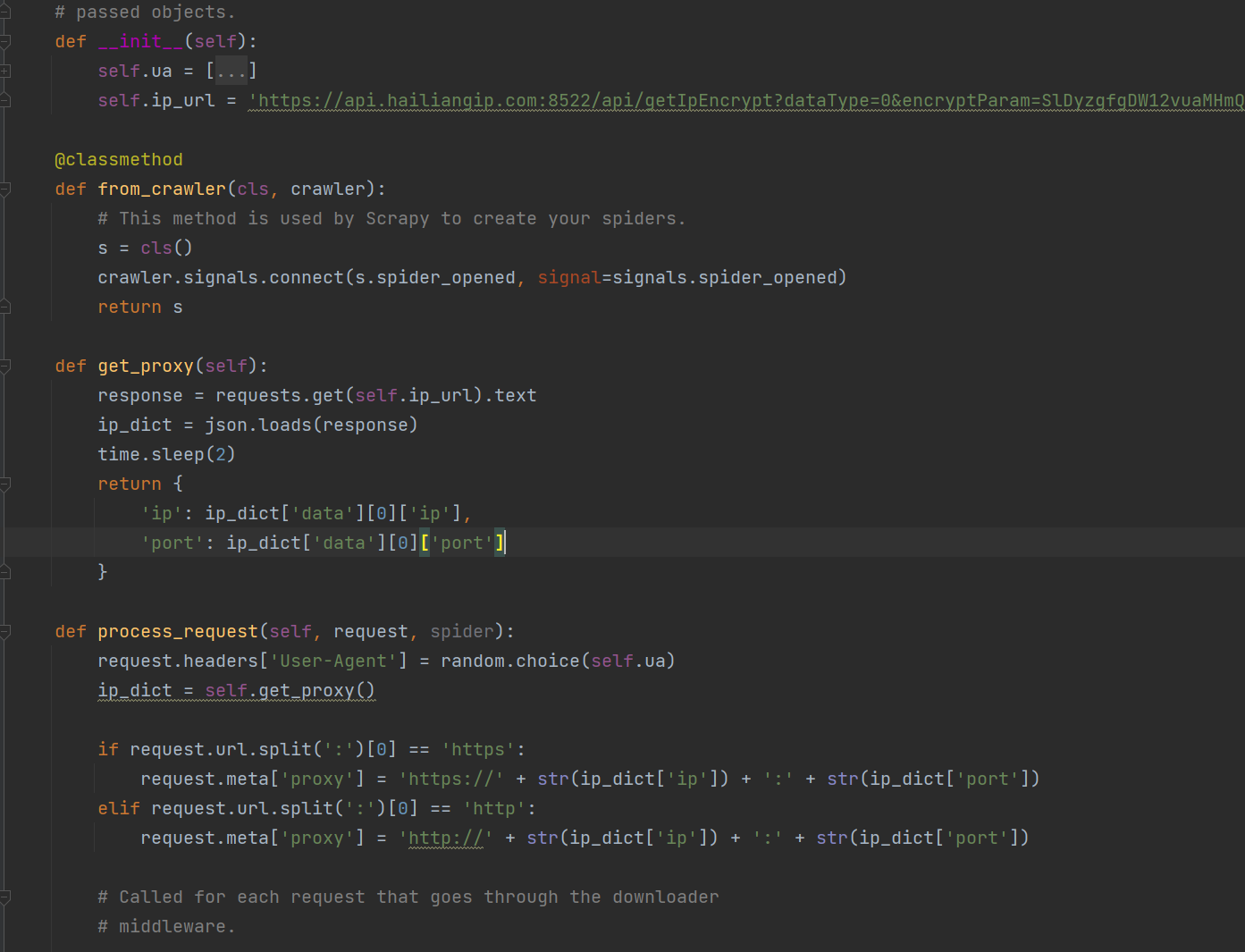
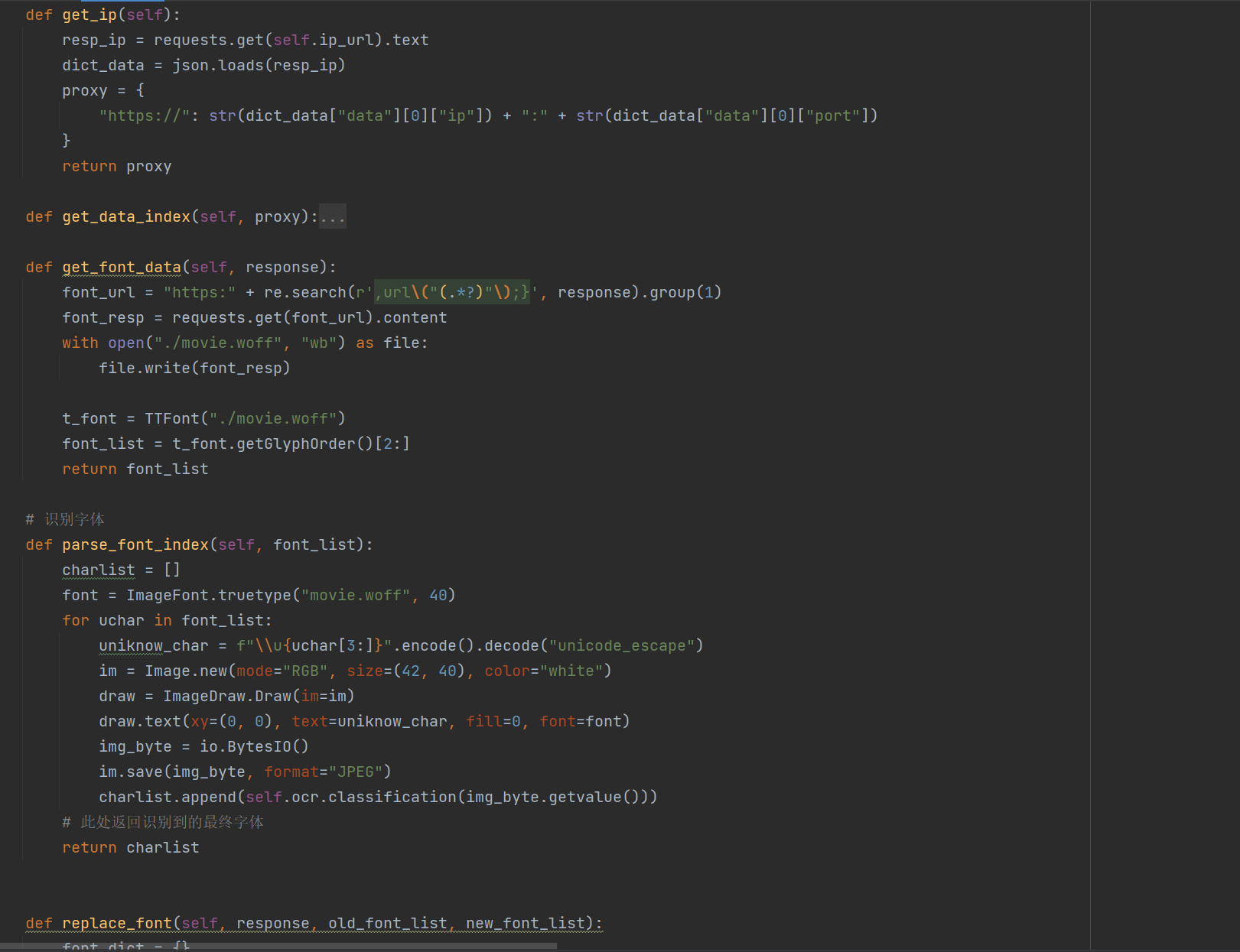
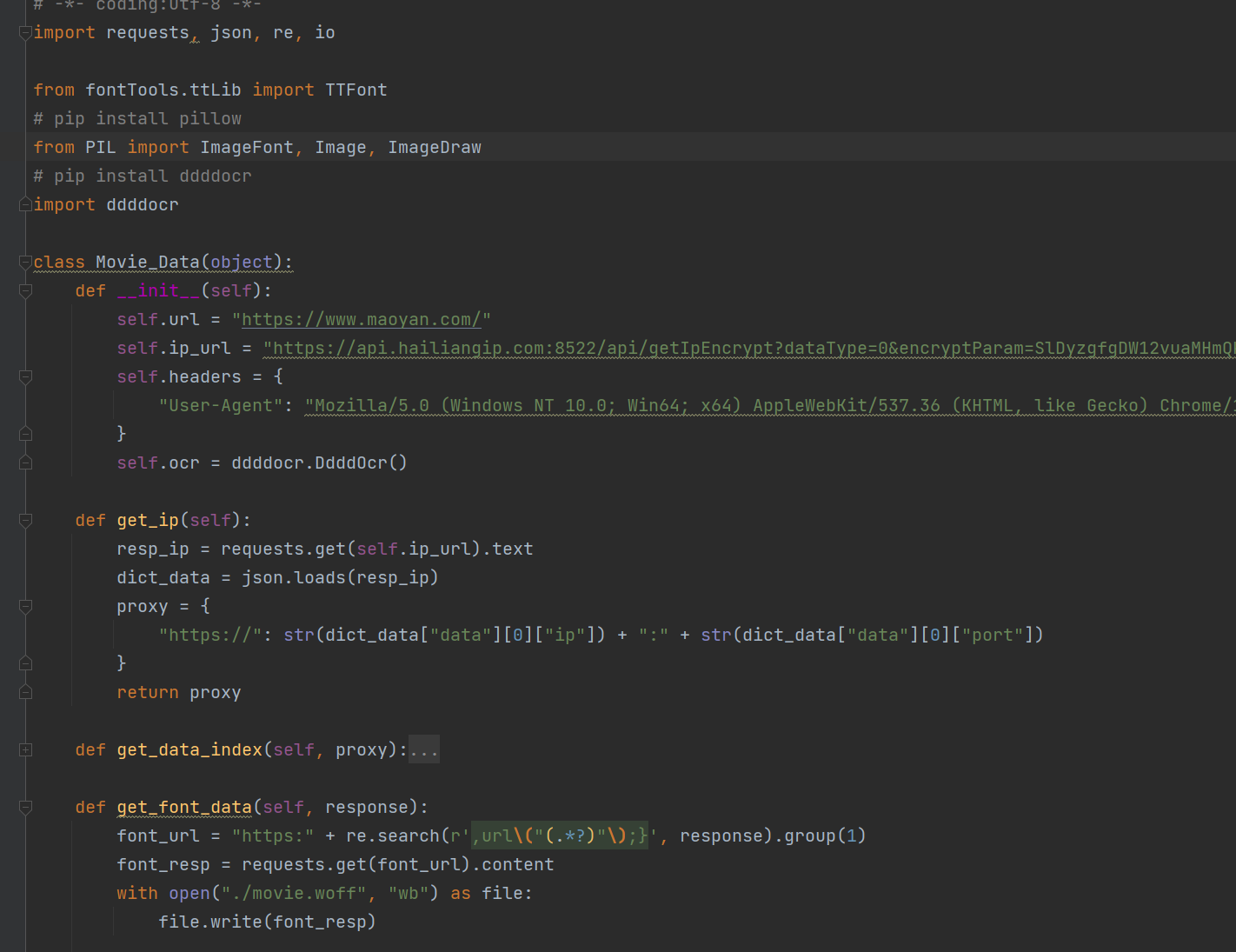
利用requests对猫眼电影 网站进行数据获取,存在的难点有字体反爬,以及实时数据获取,需要...
猫眼电影爬虫
https://www.proginn.com/w/1465188
资源下载
分享
点赞
评论
pplei
后端
· 1月前
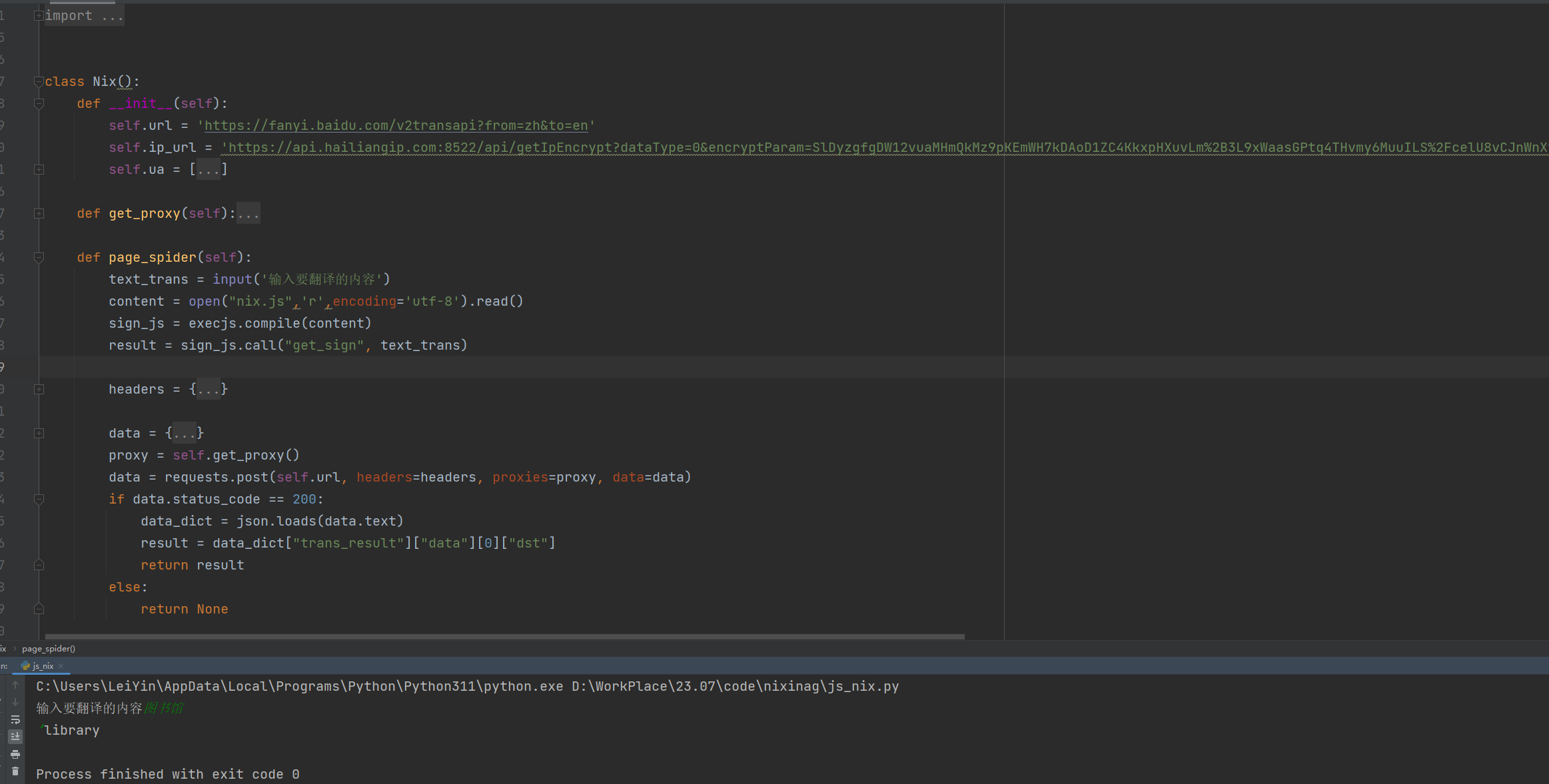
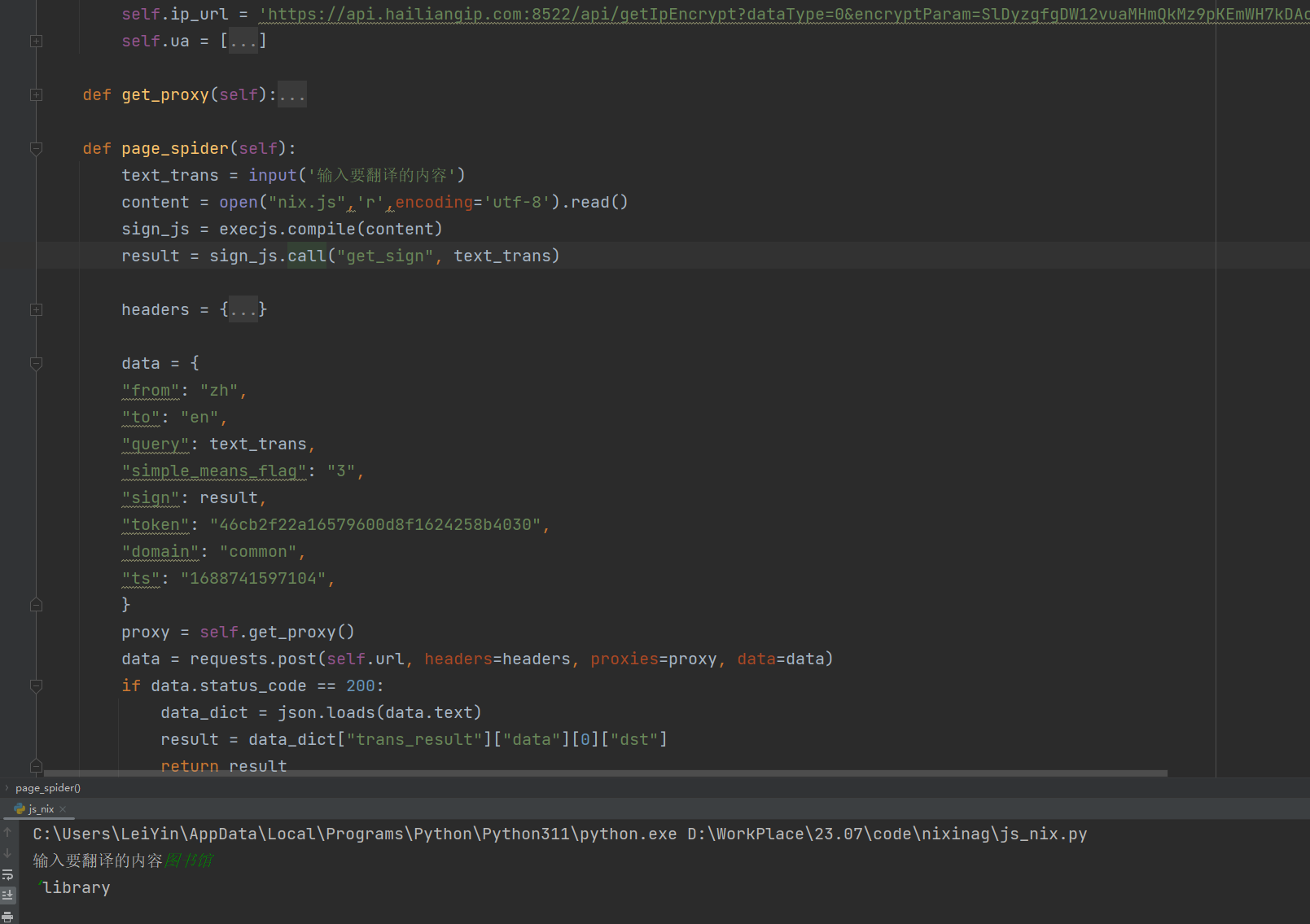
1、利用requests模块对目标网站进行数据获取2.难点:数据不存在源代码中,需要对网页请求...
Js逆向网页爬虫
https://www.proginn.com/w/1465182
资源下载
分享
点赞
评论