
kanimito
后端
· 1月前
1.利用selenium进行一系列的自动化操作,从而获取到淘宝中宝贝名、店铺名、原价、现价和月...
抓取淘宝网数据
https://www.proginn.com/w/1427140
资源下载
 分享
分享
 点赞
点赞
 评论
评论
kanimito
后端
· 1月前
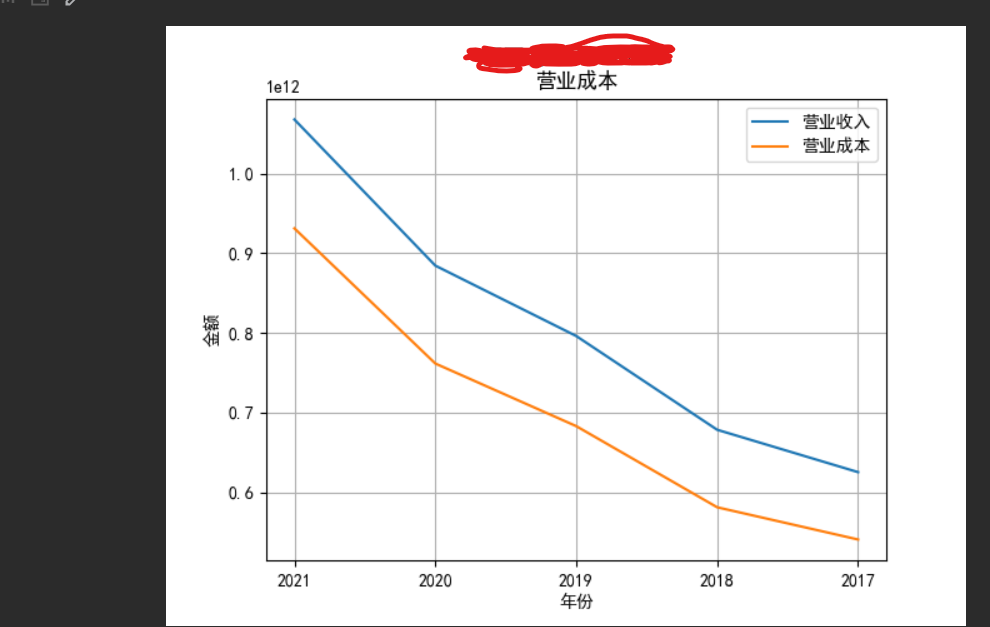
1.利用requests模块和lxml模块对网站数据进行分析,然后抓取营业收入和营业成本,并转...
抓取企业利润表数据并作出折线图
https://www.proginn.com/w/1427137
资源下载
分享
点赞
评论
kanimito
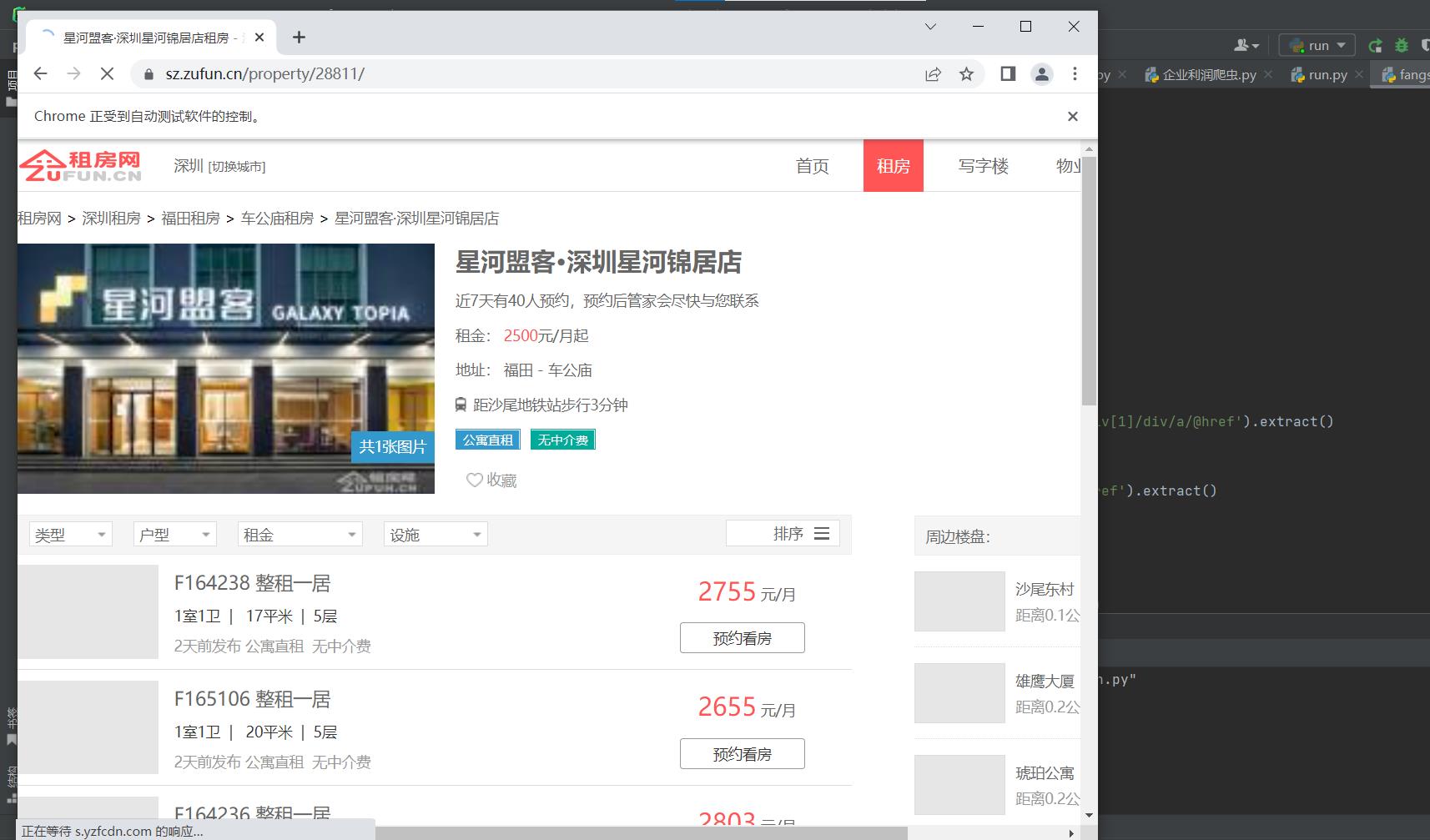
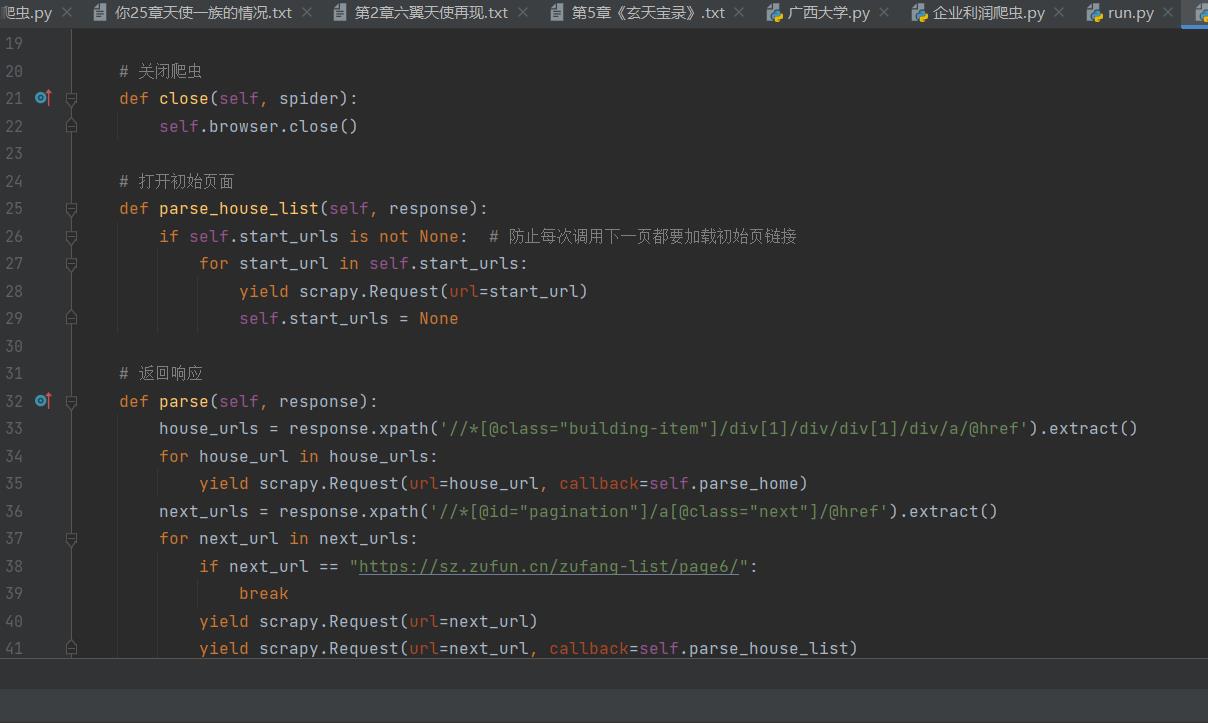
后端
· 1月前
1.利用scrapy框架写出抓取深圳房源网数据的代码,可抓取深圳房源网的房源信息、房源价格、面...
抓取深圳房源网数据
https://www.proginn.com/w/1427134
资源下载
分享
点赞
评论