风雨兼程8684
后端
· 1月前
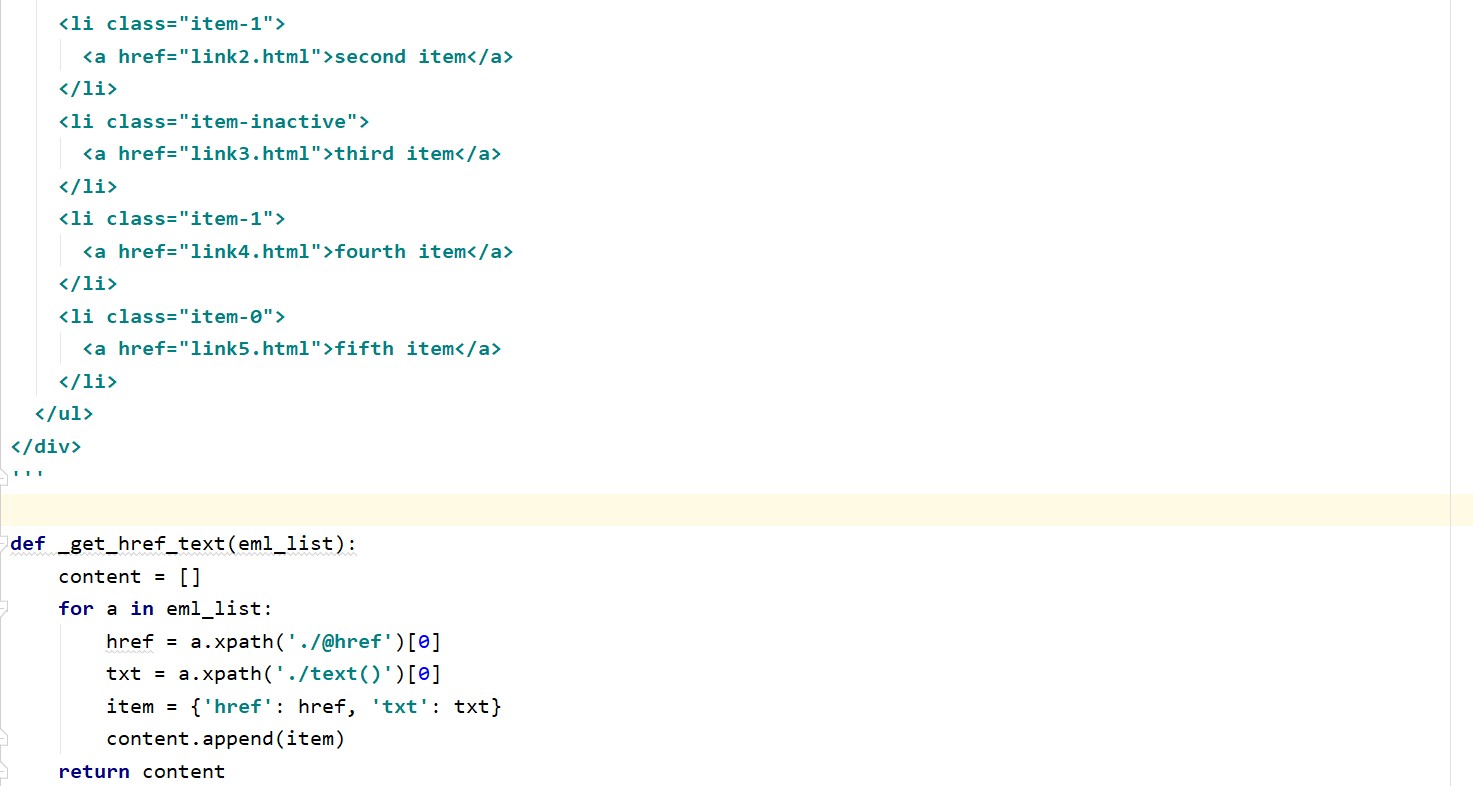
本项目通过利用python编程,并调用lxml网页解析库的etree模块中的xpath接口实现...
基于lxml的href属性和文本内容提取
https://www.proginn.com/w/1472700

资源下载
 分享
分享
 点赞
点赞
 评论
评论
风雨兼程8684
后端
· 1月前
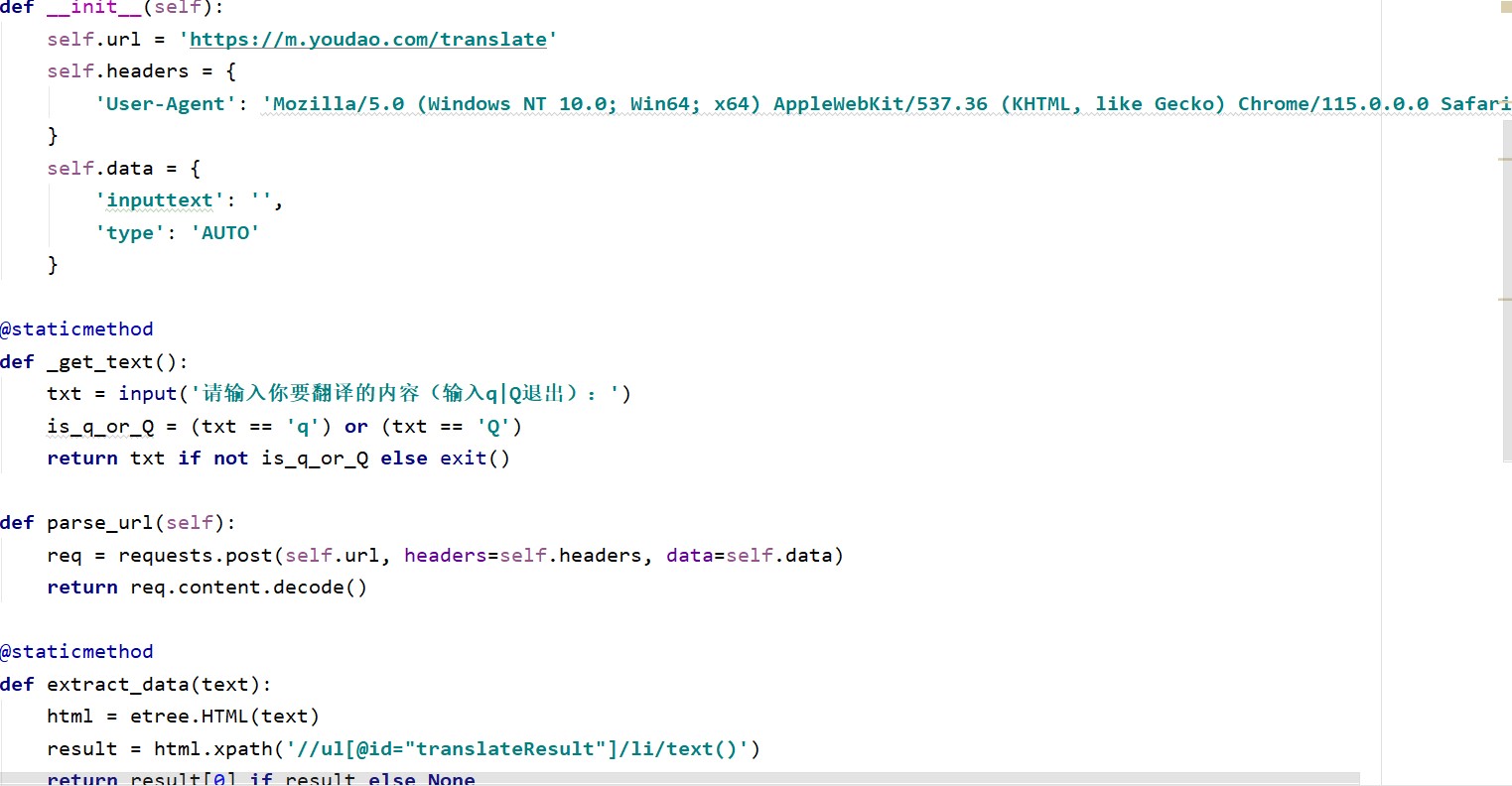
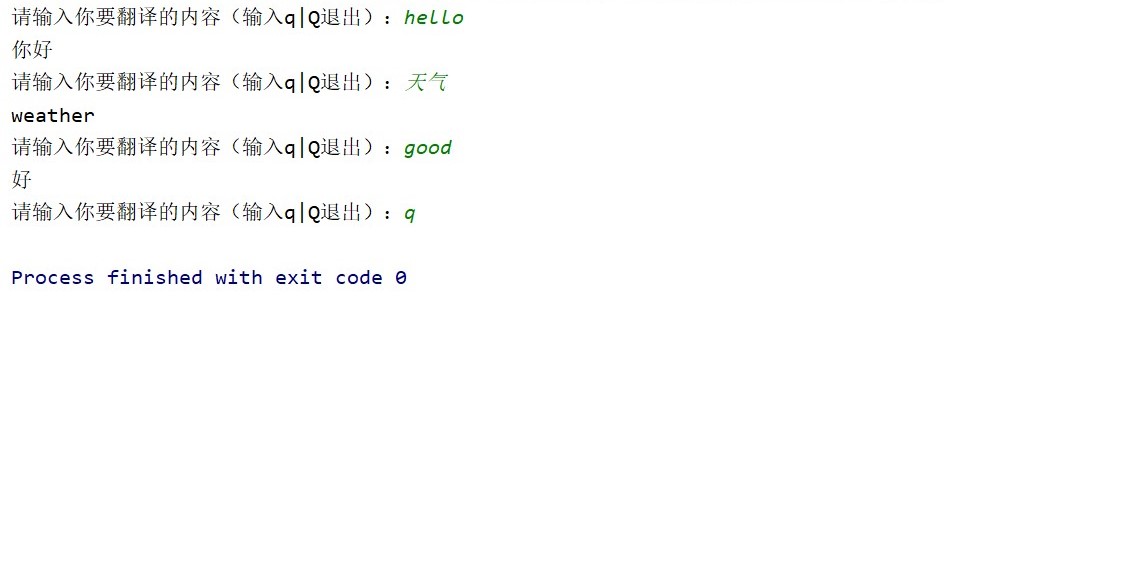
本项目实现了利用python中的requets库爬取有道翻译手机端网页数据,然后利用lxml库...
基于Python的有道翻译手机端网页数据爬取
https://www.proginn.com/w/1472697
资源下载
分享
点赞
评论
风雨兼程8684
后端
· 1月前
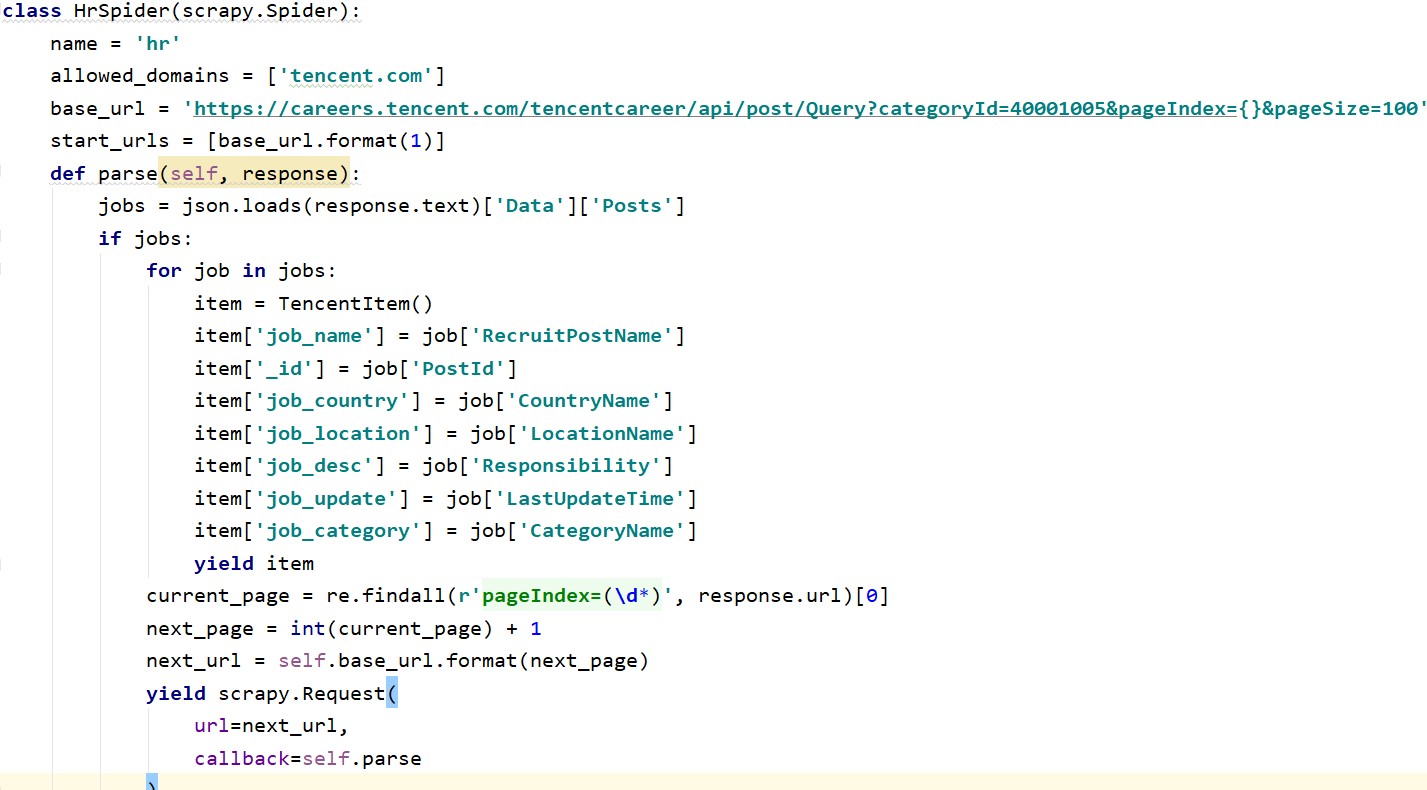
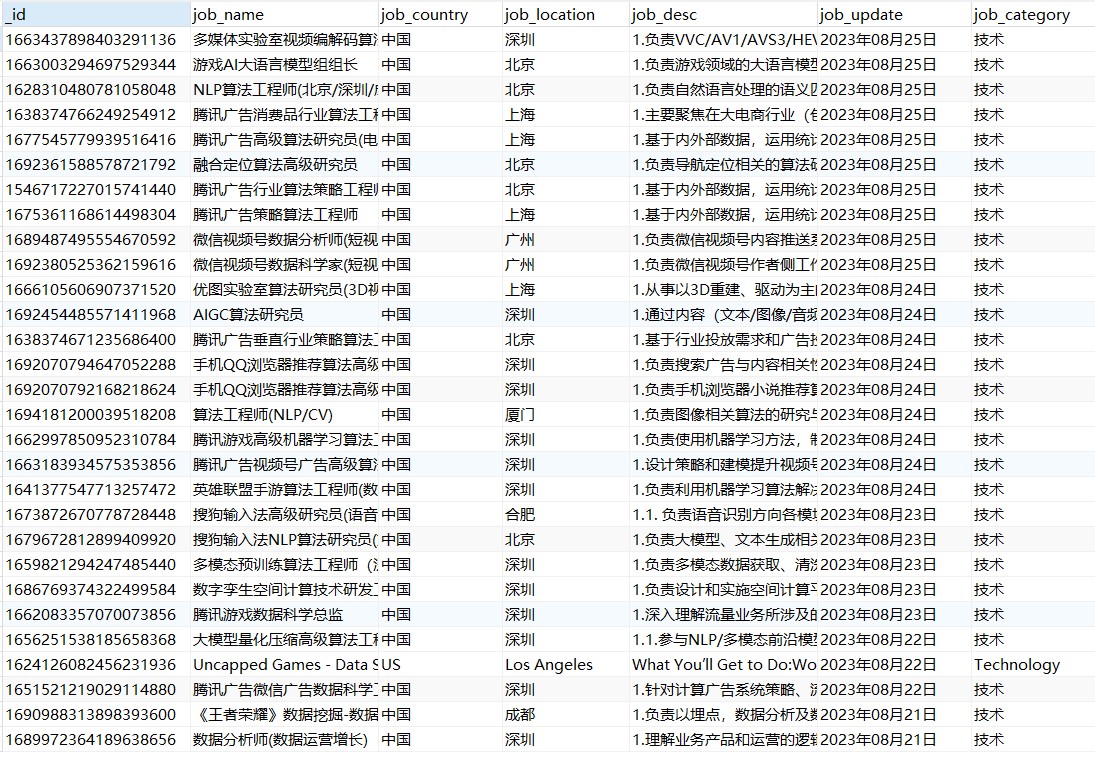
本项目实现了通过Scrapy框架爬取腾讯招聘数据的职位名称,职位所在城市,职位描述信息,职位发...
基于Scrapy框架的腾讯招聘数据爬取
https://www.proginn.com/w/1472693
资源下载
分享
点赞
评论