 小白学视觉
小白学视觉




点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
01.计算机视觉概论
什么是计算机视觉?为什么值得我们花时间去了解?它是怎么工作的?什么样的应用程序有商业价值?今天我们就一起来看看这个问题吧。
什么是计算机视觉?
计算机视觉指使用计算机自动执行人类视觉系统可以完成的任务。与人眼从外部环境接收光刺激类似,计算机使用数码相机接受这一信息,输入信息在大脑中进行处理,计算机则是使用某一种算法来处理获得的图像。
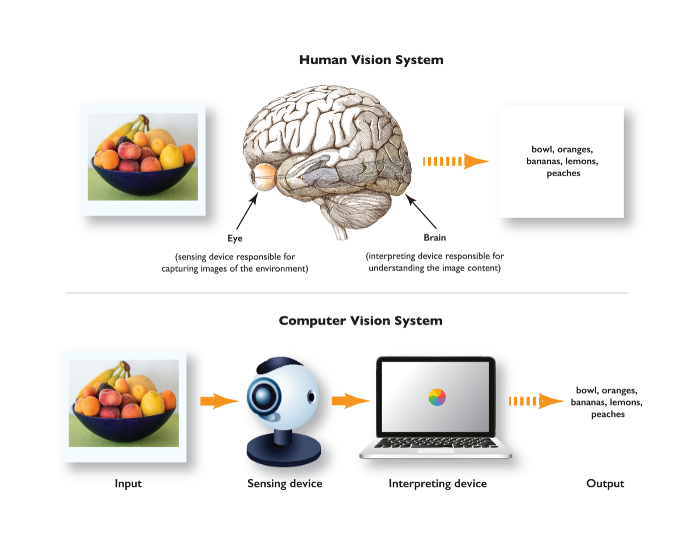
人眼与计算机的眼睛
目前的技术已经解决了获取图像不准确的问题,而且在过去的十年中也已经解决了数字图像中的标注工作。在2012年版的ILSVRC(ImageNet大型视觉识别挑战赛)中,来自世界各地的挑战研究小组在1000对象类在其ImageNet数据集中的超过一万张图片进行分类,深度学习在图像分类中也首次获得了第一名。
AlexNet [2]深度学习方法(第一作者Alex Krizhevsky)由多伦多大学SuperVision团队提出。他们利用了卷积神经网络(CNN)架构获得亚军!相比之下,Andrej Karpathy训练的图像分类器,获得了5.1%的错误率。2014年的最佳方法GoogLeNet [3],而且Karpathy本人指如果不好好训练的话图像分类器表现要差得多。显然,并非所有人都对大型模式识别有耐心和训练:
这是否意味着计算机现在能够像人类一样“看见”?答案当然不是。2015年,研究人员发现,许多先进的计算机视觉模型都容易受到恶意设计的高频模式的攻击,这些模式被称为“对抗性攻击”[4],从而诱骗模型修改其预测而我们却发现不了。
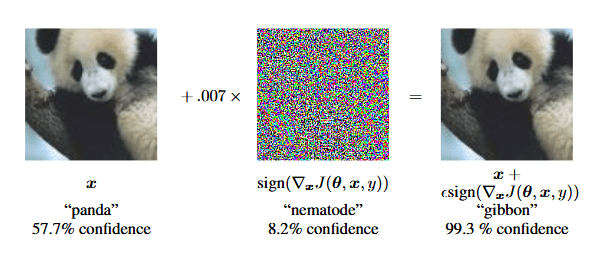
向“熊猫”添加高频“线虫”噪声会诱使网络预测“长臂猿”
这是另一个对抗性攻击如何欺骗计算机视觉算法的幽默示例。麻省理工学院的研究人员开发了一种特殊的图案,将它们放在专门设计的玩具乌龟上,以欺骗网络以预测“步枪”。
为什么要研究机器视觉?
除了对抗性攻击之外,还有高度专业化的研究人员,为什么我们还要关心计算机视觉?与Andrej Karpathy原因相同-大规模视觉识别需要大量的训练和时间。最终,仍然会有人为错误。根据Karpathy在ILSVRC中与计算方法竞争的单一经验,他已经放弃了以下想法:
l将任务外包给多个人以赚钱(例如,将其外包给Amazon Mechanical Turk上的付费本科生或付费贴标商)
l将任务外包给无薪的学术研究人员
最后,Karpathy决定独自执行所有任务,以减少标签不一致问题。Karpathy说,他花了大约1分钟的时间才能在较小的测试集中识别出1,500张图像中的每张图像。相比之下,现代的卷积神经网络可以使用不错的GPU在不到一秒钟的时间内识别图像中的对象。如果我们必须识别100,000张图像的完整测试集呢?尽管开发计算机视觉处理系统需要开发时间和专业知识,但是计算机可以比人类更一致地执行视觉识别,并且在需要时可以更好地扩展。
计算机视觉如何实现?
对于计算机,图像是像素强度的2D阵列。如果图像是黑白图像,则每个像素有一个通道。如果图像是彩色的,则每个像素通常有三个通道。如果图像来自视频,则还存在时间分量。由于阵列很容易在数学上进行操作(参见线性代数),因此我们可以开发定量的方法来检测图像中存在的内容。
手动调整方法

我有一个理论……0代表曲线,1代表直线
这被称为“手动调整方法”,因为它要求操作人员开发基于规则的理论,该理论关于如何检测计算机可以理解的给定模式。这可能是执行计算机视觉的最明显方式。但是,尽管它可以解决一些简单的问题,例如识别简单的数字和字母,但是一旦为它提供了具有光照变化,背景,遮挡和视点变化的更复杂的图像,它就会迅速瓦解。
机器学习方法
例如,假设您要检测图像中是否包含狗或猫。在训练时,您会获得大量标有狗或猫的图像集合。您采用一种算法并对它进行训练,直到它可以很好地识别出大多数训练图像为止。要检查它在看不见的图像上是否仍能正常工作,请为其提供新的猫狗图像,并验证其性能。

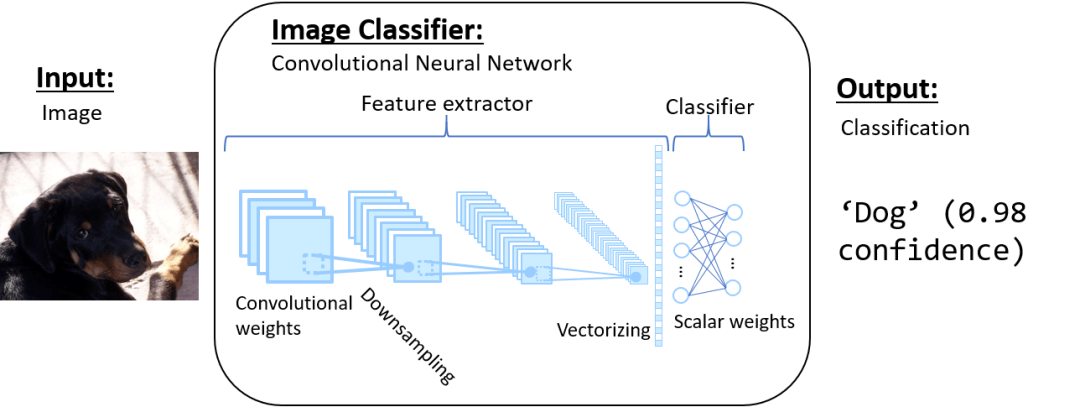
近年来,机器学习的“繁荣”实际上是所谓的“深度学习”模型的繁荣。这些模型使用可学习权重的层来提取特征并进行分类,而先前的模型使用手动调整的特征和浅可学习的权重来对其进行分类。如前所述,计算机视觉中最基本的模型之一就是“卷积神经网络”(简称CNN或ConvNet)。这些模型通过使用3D权重和下采样对卷积进行反复卷积(将其视为2D乘法)从图像中提取特征。然后,将要素转换为一维矢量,然后与标量权重相乘以生成输出分类。
02.计算机视觉的主要任务
由于人类视觉系统可以同时执行许多不同的任务,而计算机视觉应该可以复制它,因此有很多方法可以将其分解为离散的任务。通常,计算机视觉要解决的核心任务如下(以难度递增的顺序):
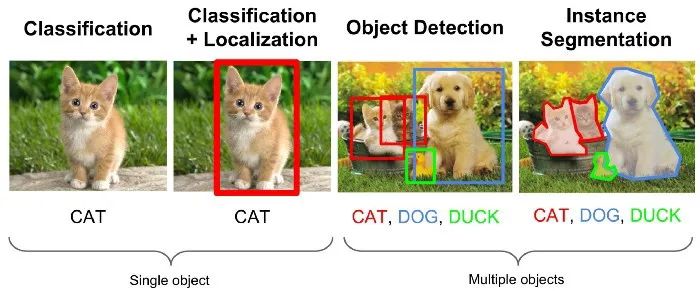
1.图像分类:给定具有单个对象的图像,预测存在的对象(对于按对象,标签或其他属性标记,搜索或索引图像很有用)
2.图像本地化:给定具有单个对象的图像,预测存在的对象并在其周围绘制一个边框(用于定位或跟踪对象的外观或运动)
3.对象检测:给定包含多个对象的图像,预测两个对象均存在,并在每个对象实例周围绘制一个边界框(用于定位或跟踪多个对象的外观或运动)
4.语义分割(图中未显示):给定具有多个对象的图像,预测存在的两个对象并预测属于每个对象类别(例如猫类别)的像素(用于分析多个对象类别的形状)
5.实例分割:给定包含多个对象的图像,预测存在的两个对象,并预测哪些像素属于对象类的每个实例(例如Cat#1与Cat#2)(可用于分析多个对象实例的形状)
可用的数据集和模型
正如ILSVRC提供已经注释的数据(ImageNet)来客观比较不同研究人员的算法一样,竞争研究人员又发布了他们的模型来支持其主张并促进进一步的研究。这种开放式协作的文化意味着许多最新的数据集和模型可供公众公开使用,并且顶级模型可以容易地应用,甚至不需要重新培训。
当然,如果“ tape_player”和“ grey_whale”(也许是“ machine_1”或“ door_7”)未涵盖需要识别的对象,则有必要收集自定义数据和注释。但是在大多数情况下,可以使用新数据简单地对最新模型进行重新训练,并且仍然可以保持良好的性能。
图像分类(单个标签)

对象本地化(多个边界框)
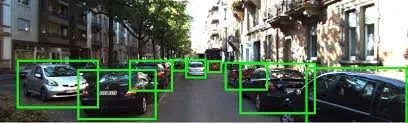
Frustum PointNets(2017),AP = 84.00%
语义细分(多个类别细分)

实例细分(多个实例细分)
 EfficientPS(2019),AP = 39.1%
EfficientPS(2019),AP = 39.1%03.可能的商业用途
现在,我们已经了解了什么是计算机视觉,它为何有用以及如何执行,对于企业来说有哪些潜在应用程序?与文本或数据库记录不同,图像通常不被公司很好地分类和存储。但是,我们认为,某些专业领域的公司将有数据和动力,可以从使用计算机视觉从其存储的图像数据中提取额外的价值中受益。
产业
第一个领域是制造业,资源开采和建筑业。这些公司通常会大量生产产品,开采资源或建造土建工程,并且许多监视或预测分析是手动完成的或使用简单的分析技术完成的。但是,我们认为计算机视觉对于自动化以下任务会很有用:
缺陷检测,质量控制:通过学习正常产品的外观,计算机视觉系统可以在机器操作员检测到可能的缺陷时对其进行标记(例如,来自AiBuild的Ai Maker)

预测性维护:通过了解给定机械在其使用寿命即将结束时的外观,计算机视觉系统可以实时监视机械,量化其状态(例如强度为90%)并预测何时需要维护
远程测量:通过学习在感兴趣的对象(例如,材料中的裂缝)周围画一个边界框,计算机视觉系统可以确定该对象的实际大小
机器人技术:通过学习识别其视野中的物体,嵌入机器人内部的计算机视觉系统可以学习操纵物体(例如在工厂中)或导航其环境
医疗类
医学领域是可以从计算机视觉中受益的类似领域,因为许多工作集中在监视和测量人类患者的身体状况(而不是机械或制成品)上。
医学诊断辅助工具:通过学习医生感兴趣的诊断组织的外观,计算机视觉系统可以建议相关区域并加快诊断速度(例如,使用HistoSegNet从病理切片中分割组织学类型)
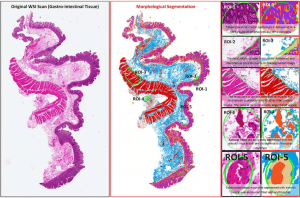
远程测量:同样,通过学习在感兴趣的对象(例如病变)周围绘制边界框,计算机视觉系统可以确定该对象的实际大小,以监视患者随时间的进展(例如,Swift Skin和Wound (来自Swift Medical)

文件和多媒体
文档和多媒体是另一个可以从计算机视觉中受益的领域,因为大多数公司以扫描的文档,图像和视频的形式保存大量的非结构化(和无注释)信息。尽管大多数公司倾向于不标记这些图像,但有些公司可能具有可以被利用的有用标签(例如,在线零售商店的产品信息)。
光学字符识别(OCR):可以识别并提取扫描文档的文本以进行进一步处理
图像搜索引擎:图像可用于搜索其他图像(例如,用于在线零售网站,搜索与最近购买的产品类似的视觉相似产品或造型相似产品)
视觉问题解答(VQA):用户可以向计算机视觉系统询问有关图像中描绘的场景的问题,并接收人为语言的响应-这对于视频字幕很重要。

视频摘要:计算机视觉系统可以总结视频中的事件并返回简明摘要-这对于自动生成视频描述非常重要
零售和监视
零售(我们之前已经提到过)和监控是可以从计算机视觉中受益的其他领域。他们依靠实时监控人类行为者及其行为来优化所需的结果(例如购买行为,非法行为)。如果可以从视觉上观察到该行为,则计算机视觉可以是一个很好的解决方案。
人类活动识别:可以训练计算机视觉系统来识别视频馈送中人类当前的活动(例如,步行,坐着),这对于量化人群中坐着的人数或识别人群流量瓶颈很有用
人体姿势估计:还可以训练计算机视觉系统来定位人体关节的位置和方向,这对于虚拟现实交互,手势控制或出于医疗或体育目的分析人的动作非常有用
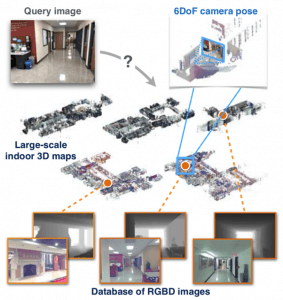
室内视觉本地化:计算机视觉系统可用于将室内环境的当前实时图像或视频馈送与已知快照的数据库进行匹配,并在该室内环境中定位当前用户的位置(例如,用户在室内拍照)大学校园,并有一个应用显示他们所在的位置)
卫星影像
卫星图像是我们可以看到计算机视觉有用的最后领域,因为它经常被用于通过专家繁琐的手动注释来监视土地使用和环境随时间的变化。如果训练有素,计算机视觉系统可以加快对卫星图像的实时分析,并评估哪些地区受到自然灾害或人类活动的影响。
船舶/野生生物跟踪:通过卫星图像或港口或野生动植物保护区,计算机视觉系统可以快速计数和定位船舶和野生生物,而无需繁琐的人工注释和跟踪


作物/牲畜监测:计算机视觉系统还可以监测农业用地状况(例如,通过定位患病或低产地区),以优化农药使用和灌溉的分配
大家会看到,计算机视觉为企业带来了许多应用程序。但是,企业应该首先考虑以下几点:
l数据:您是从第三方,供应商处获取图像数据还是自己收集图像数据?大多数数字数据不可用或未分析
l注释:您是从第三方,供应商处获取注释还是自己收集注释?
l问题表述:您要解决什么样的问题?这是领域专业知识将派上用场的地方(例如,足以检测机器何时有缺陷(图像识别),还是我们还需要定位缺陷区域(对象检测)?)
l转移学习:经过预训练的模型是否可以很好地完成工作(如果是,则需要较少的研发工作)?
l计算资源:您是否有足够的计算能力用于训练/推理(计算机视觉模型通常需要云计算或强大的本地GPU)?
l人力资源:您是否有足够的时间或专业知识来实施模型(计算机视觉通常需要机器学习工程师,数据科学家或具有研究生教育水平且工作时间专用于研究问题的研究科学家)?
l信任问题:最终用户/客户是否信任计算机视觉方法?必须建立良好的关系,并采用可解释性的方法来确保透明度和问责制,从而促进更高的用户接受度
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~



