 新智元
新智元





新智元报道
新智元报道
来源:专知
编辑:David
【新智元导读】在过去的几年里,每个月都会发布新的机器学习加速器,用于语音识别、视频对象检测、辅助驾驶和许多数据中心应用。本文更新了过去两年人工智能加速器和处理器的调研,收集和总结了目前已公开发布的商业加速器的峰值性能和功耗数据。
在过去的几年里,每个月都会发布新的机器学习加速器,用于语音识别、视频对象检测、辅助驾驶和许多数据中心应用。

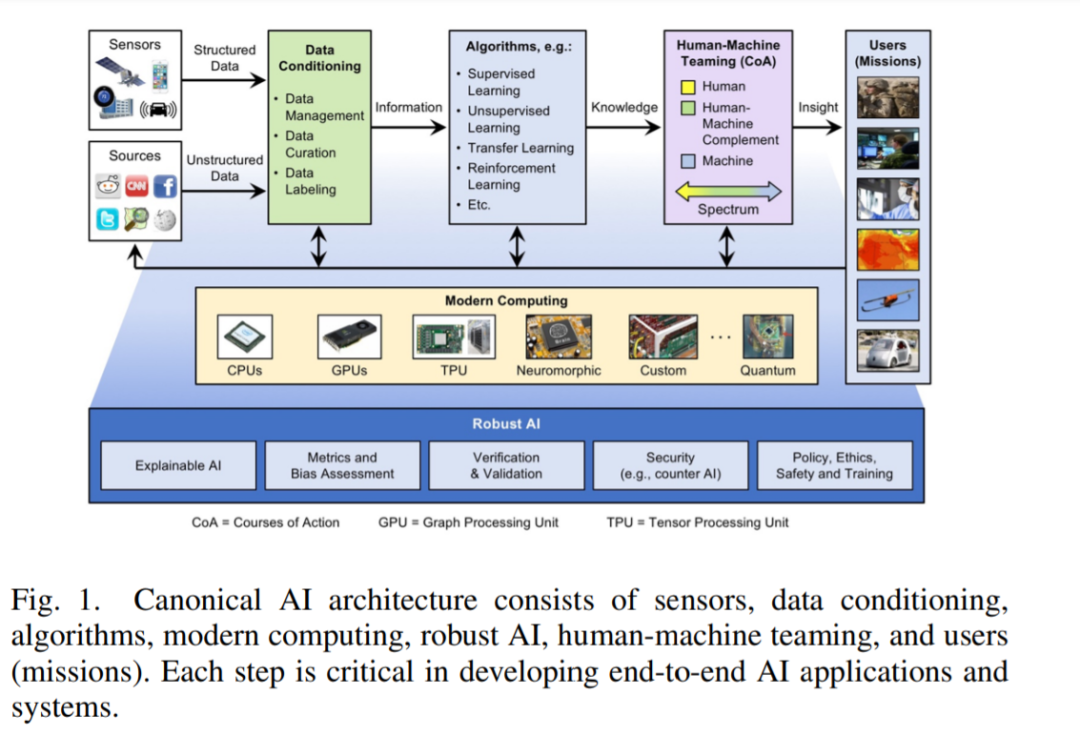
引言
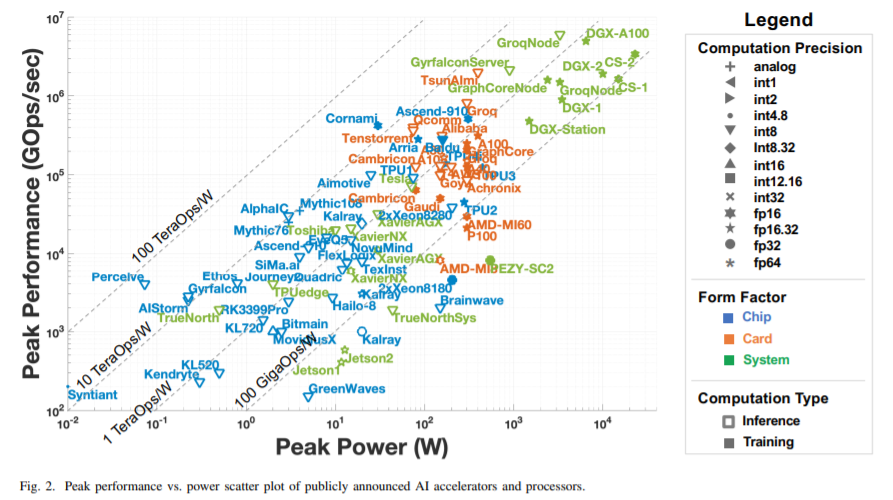
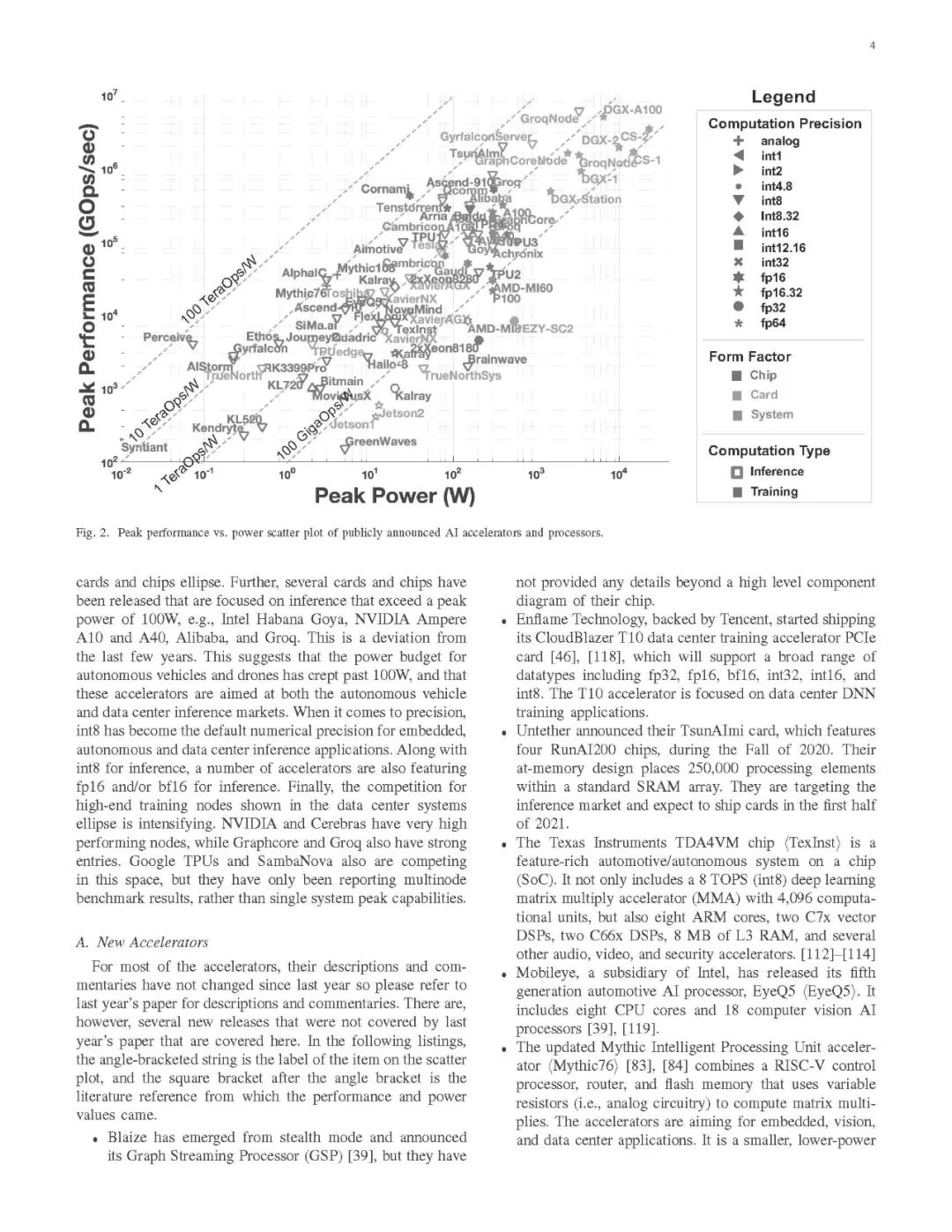
公开发布的各AI加速器和处理器的峰值性能和峰值功率图
神经网络类型——虽然人工智能和机器学习包含了一系列广泛的基于统计的技术,但本文继续关注去年的重点,面向深度神经网络(DNNs)和卷积神经网络(CNN)的加速器和处理器,因为它们具有相当高的计算强度。
神经网络训练与推理——正如前两次调研中所解释的那样,该调研侧重于用于推理的加速器和处理器,原因有很多,包括国防和国家安全AI/ML边缘应用依赖推理。
数值精度——我们将考虑加速器支持的所有数值精度类型,但对于大多数类型,它们的最佳推断性能是int8或fp16/bf16 (IEEE 16位浮点数或谷歌的16位脑浮点数)。但从图2中可以看出,许多不同的数值格式都报告了峰值性能。
神经形态计算和光子计算——在今年的调研没有发布峰值性能和峰值功率的数字。有一些神经形态处理器与传统加速器的相对比较,但没有确切的数字。也许明年,我们将开始看到实际的性能数据,我们可以纳入这个调研。
本文转载自微信公众号“专知”
-往期精彩-



