 目标检测与深度学习
目标检测与深度学习




点击左上方蓝字关注我们

链接 | https://zhuanlan.zhihu.com/p/234506503
大家好,我是dog-qiuqiu,这篇文章可能不会涉及太多技术算法上的讲解,可能先和大家探讨下关于这个算法的一些定位和应用场景的问题吧。
Yolo-Fastest:
简单、快速、紧凑、易于移植
适用于所有平台的实时目标检测算法
基于yolo的最快最小已知通用目标检测算法
针对ARM移动端优化设计,优化支持NCNN推理框架
基于部署在RK3399、Raspberry Pi 4b...等嵌入式设备上的NCNN,实现全实时30fps+
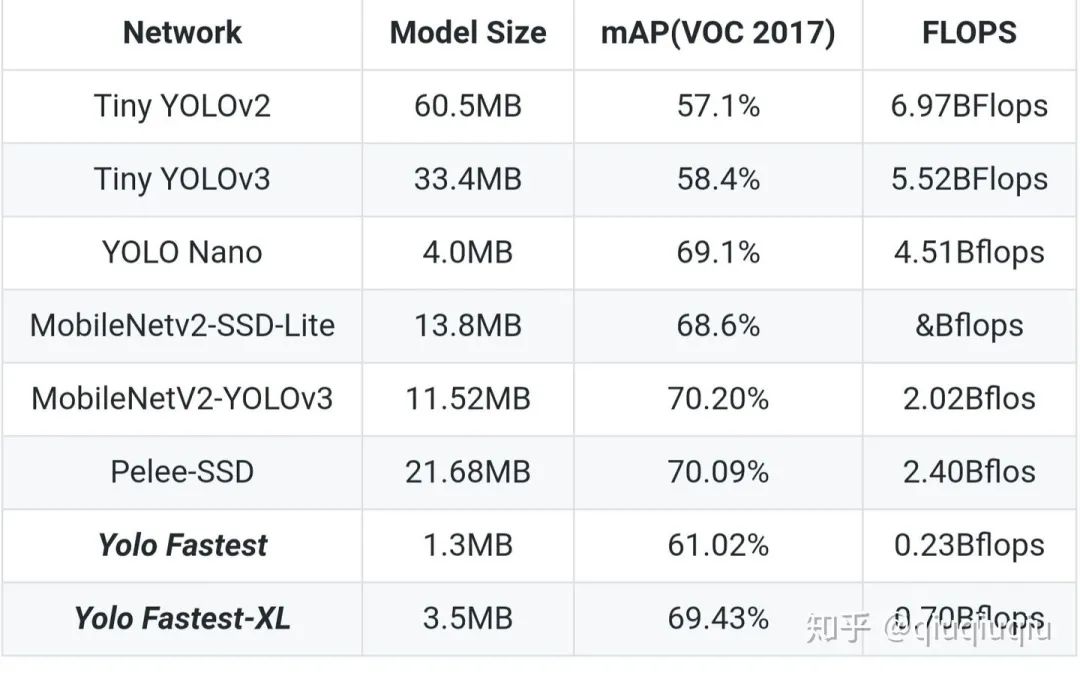
Yolo-Fastest,顾名思义,应该是现在已知开源最快的最轻量的改进版yolo通用目标检测算法(貌似也是现在通用目标检测算法中最快最轻量的),其实初衷就是打破算力的瓶颈,能在更多的低成本的边缘端设备实时运行目标检测算法,例如树莓派3b,4核A53 1.2Ghz,在最新基于NCNN推理框架开启BF16s,320x320图像单次推理时间在60ms~,而在性能更加强劲的树莓派4b,单次推理33ms,达到了30fps的全实时。而相比较下应用最广泛的轻量化目标检测算法MobileNet-SSD要在树莓派3b跑200ms左右,Yolo-Fastest速度整整要快3倍+,而且模型才只有1.3MB,而MobileNet-SSD模型达到23.2MB,Yolo-Fastest整整比它小了20倍,当然这也是有代价的,在Pascal voc上的map,MobileNet-SSD 是72.7,Yolo-Fastest是61.2,带来了接近10个点的精度损失,当然孰轻孰重,大家都有各自的想法。其实大家一般的检测任务本身不会像VOC那样检测20类那么多那么复杂,一般都是几类甚至单类检测,那么这样对于模型本身学习能力要求没那么高,因为本身类别越多样本不平衡的问题越大,越影响模型本身的性能。其实这个问题可以参考我的yoloface-500kb,一个只有400kb大小的人脸检测模型,这个本身就是个轻量化单类目标检测模型。下图是树莓派3b 基于Ncnn的常见模型的Benchmark。

其实,我还有个xl版本啊哈哈哈,精度更高当然模型更大速度当然…更慢啊xl就不多讲了,肯定树莓派3b没法实时,嘻嘻,但是这边有个基于麒麟990的NCNN的速度基准
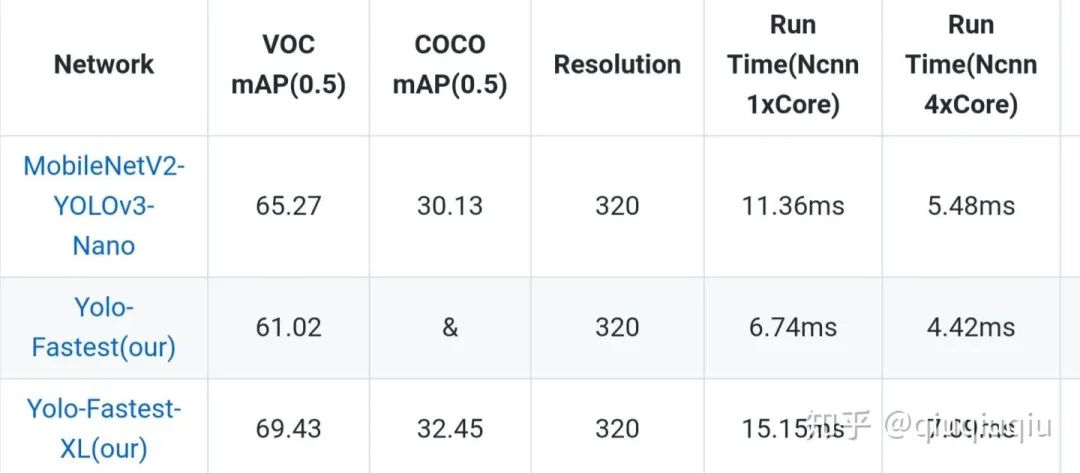
啥,精度还不够,看来直接祭出我的MobileNetv2-yolov3-lite,VOC 73.2%的mAP,37.4% AP05 COCO,只有8MB,1.8Bflops,比mb-ssd系列的算法动不动10几20几MB的模型大小轻量很多,精度也高一些,但是lite只是证明yolo比mb-ssd系列更有优势,真正有意义实时的是fastest-xl以及fastest,哈哈,在放一张对比图
指标全是参考论文以及github相应的开源项目再来张效果图吧这是fastest

这是xl

对了,其实旷视的thundernet才是大佬,250mbflops的计算量,VOC能达到70%,可惜没开源,但是是个二阶检测算法,估计没yolo好部署。不过话说,如果我用object365把模型在训练一遍迁移到voc是不是又得暴涨几个点
总得而言,这个模型本身没有创新点,但是绝对重实用。管你啥X86,ARM,GPU,NNIE,Android,Linux…通吃,模型本身算子很简单,特别好移植,哈哈
Yolo-Fastest-1.1 多平台基准测试
| 设备 | 计算后端 | 系统 | 框架 | 运行 |
|---|---|---|---|---|
| 米11 | 骁龙888 | 安卓(arm64) | 神经网络 | 5.59ms |
| 伴侣 30 | 麒麟990 | 安卓(arm64) | 神经网络 | 6.12ms |
| 魅族16 | 骁龙845 | 安卓(arm64) | 神经网络 | 7.72ms |
| 开发板 | 骁龙835(猴子版) | 安卓(arm64) | 神经网络 | 20.52ms |
| 开发板 | RK3399 | Linux(arm64) | 神经网络 | 35.04ms |
| 树莓派 3B | 4xCortex-A53 | Linux(arm64) | 神经网络 | 62.31ms |
| Orangepi 零 Lts | H2+ 4xCortex-A7 | Linux(armv7) | 神经网络 | 550ms |
| 英伟达 | GTX 1050ti | Ubuntu(x64) | 暗网 | 4.73ms |
| 英特尔 | i7-8700 | Ubuntu(x64) | 神经网络 | 5.78ms |
以上是多核测试基准
以上速度基准测试是通过big.little CPU中的big core
树莓派 3B 启用 bf16s 优化,树莓派 64 位操作系统
rk3399需要把cpu锁在最高频率,ncnn并开启bf16s优化
Yolo-Fastest-1.1 行人检测
| 设备 | 系统 | 框架 | 运行 |
|---|---|---|---|
| 树莓派 3B | Linux(arm64) | 神经网络 | 62ms |
基于yolo-fastest-1.1的简单实时行人检测模型
启用 bf16s 优化,树莓派 64 位操作系统

END
 整理不易,点赞鼓励一下吧↓
整理不易,点赞鼓励一下吧↓

