 Python绿色通道
Python绿色通道




↑ 关注 + 星标 ,每天学Python新技能
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包 
后台回复【大礼包】送你Python自学大礼包




如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
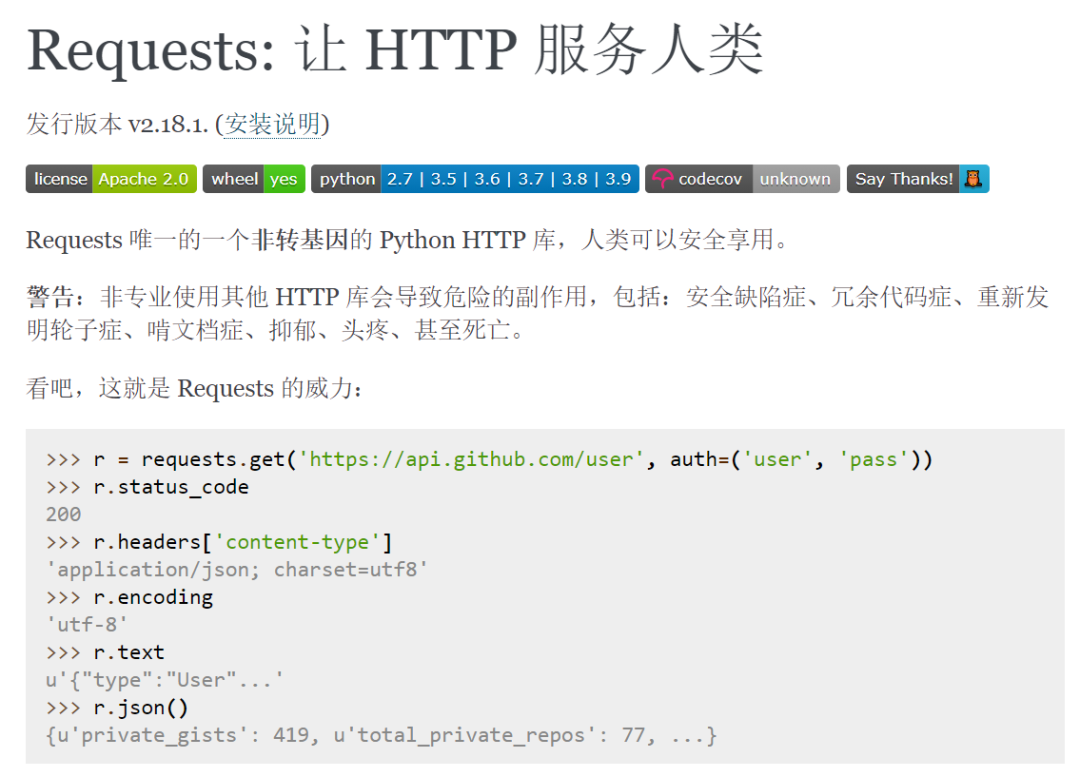
Python自学超级硬核资料
最后送大家一份Python学习大礼包,从Python基础,爬虫,数据分析Web开发等全套资料,吃透资料,你可以扔掉其他资料,这些资料都是视频,学起来非常友好
Ps:都是视频学习资料,非常适合基础不好或者零基础的同学
推荐阅读
看完记得关注@Python绿色通道 及时收看更多好文 ↓↓↓

