 Python绿色通道
Python绿色通道




后台回复【大礼包】送你Python自学大礼包

我们现在处于一个信息爆炸的大数据时代,数据在互联网上的传播和呈现方式多种多样,越来越多的公司开始重视保护自己的数据了,他们研发反爬虫技术,让爬虫不在可以随便的去爬取获取他们的信息。
如果你想要更好的获取数据,那么反爬虫的知识也需要有一定程度上的研究,当你掌握反爬虫的知识后,将会让你的爬虫更好的绕过反爬虫。
所以,我打算跟大家分享一些反爬虫技术的相关知识,让大家能够更好的提高自己的爬虫效率和应用防护等级。本文仅供大家学习,请勿用于非法途径。
01
反爬虫的概念和定义
我个人对反爬虫概念的理解是:一切限制爬虫程序从服务器获取数据的方式都属于反爬虫。它有多种限制手段,如:限制请求头、限制登陆、验证码检验、限制访问频率等。
从这些限制手段出发,可以将反爬虫分为主动型和被动型,两种类型。
开发者使用一些技术手段来区分正常用户和爬虫被称为主动型反爬虫,通常有限制请求头、限制访问频率、限制登陆等方式。
为了提高用户体验或节约资源,用一些技术间接提高爬虫访问难度被称为被动型反爬虫,通常有Ajax数据加载、点击切换标签页等方式。
当然,也可以从其他方面对反爬虫进行更加细化的划分,我们这里不在做详细的讲述,需要注意的是,同一种限制方式,可能属于不同的反爬虫技术类型,比如由JS加载的数据,我们可以说成动态渲染反爬虫,也可以说成是信息检验型反爬虫,所以我们在学习的时候,遇到这类情况时,知道怎么回事即可。
02
爬虫和反爬虫的对立关系
我们通过下图来了解爬虫和反爬虫之间即针锋相对,又互相进步的关系。(从左至右,从上至下发展)
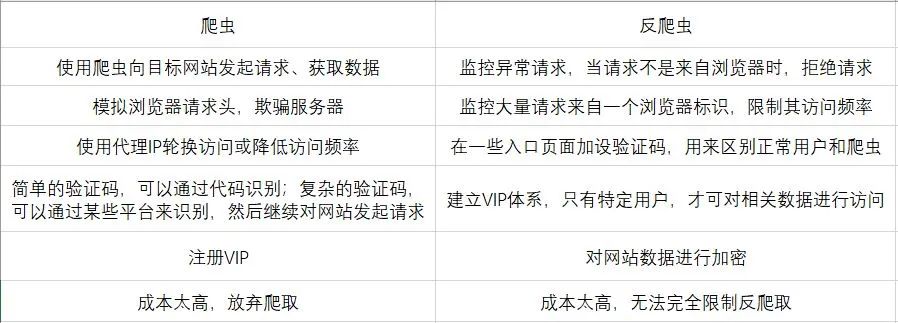
反爬虫不仅要会技术,同时也需要金钱进行支撑。我们有时需要购买代理IP或者开通VIP账户等,如果爬取数据量较大时,这些将是一笔不菲的开支。同时,在研究如何破解反爬虫时,还会消耗我们大量的时间,这也是需要计算的成本。
03
小结
本篇我简单的给大家介绍了一下反爬虫产生的原因和分类及其定义,后面我将会根据不同类型的反爬虫技术来跟大家分享其原理和对于的绕过方法。
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
Python自学超级硬核资料
最后送大家一份Python学习大礼包,从Python基础,爬虫,数据分析Web开发等全套资料,吃透资料,你可以扔掉其他资料,这些资料都是视频,学起来非常友好
Ps:都是视频学习资料,非常适合基础不好或者零基础的同学
推荐阅读
看完记得关注@Python绿色通道 及时收看更多好文 ↓↓↓

