 3D视觉工坊
3D视觉工坊




点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

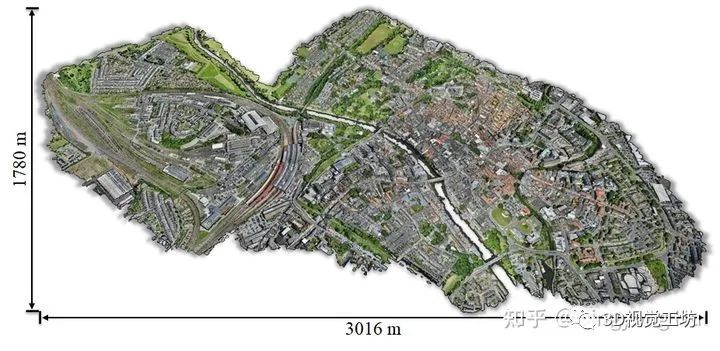


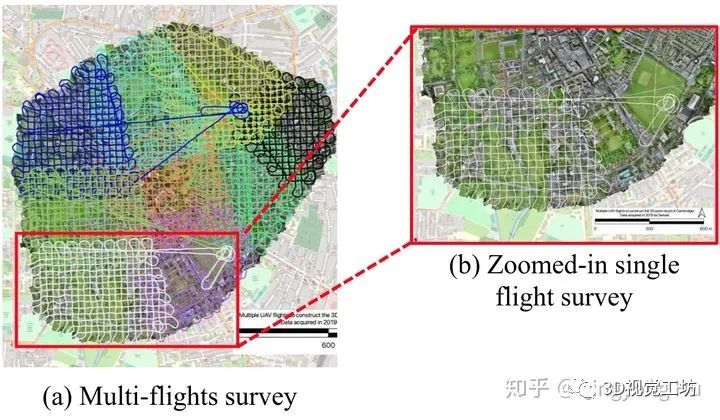
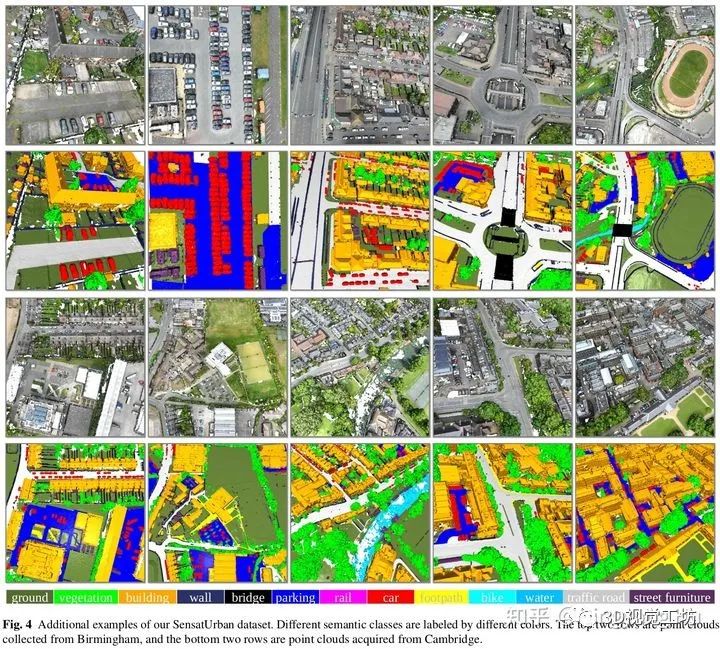
对于三维点云的重建,我们直接采用了现成的软件比如Pix4D根据 Structure from Motion(SfM) 和 dense image matching,以实现从捕获的航空图像序列中重建密集和彩色的3D点云。对于伯明翰周边的市区,我们将所有捕获的连续图像输入到Pix4D,总共生成569,147,075个3D点,覆盖了1.6平方公里的面积。同样,我们为剑桥市附近的市区重建了2,278,514,725点,面积约为4.6平方公里。此外,我们在约克郡也采集了3.2平方公里内的904,155,619个点。
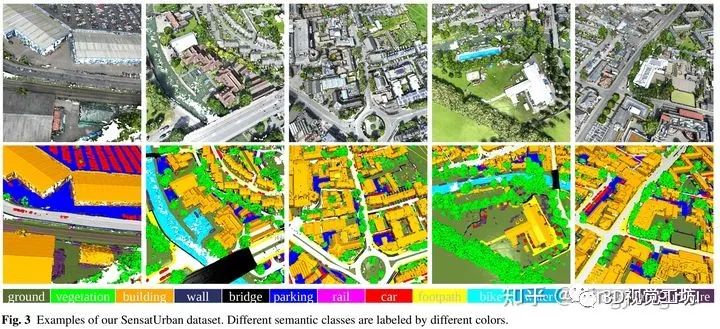
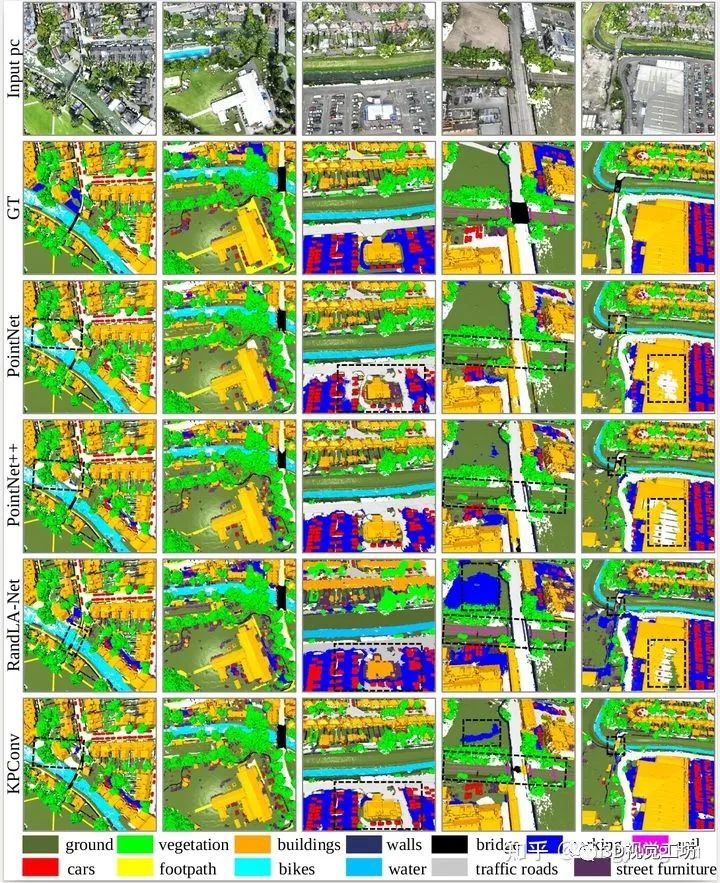
地面(ground)
植被(vegetation)
建筑物(building)
墙(wall)
桥梁(bridge)
停车场(parking)
铁轨(rail)
交通路(traffic road)
街道设施(street furniture)
汽车(car)
人行道(footpath)
自行车(bike)
水(water)
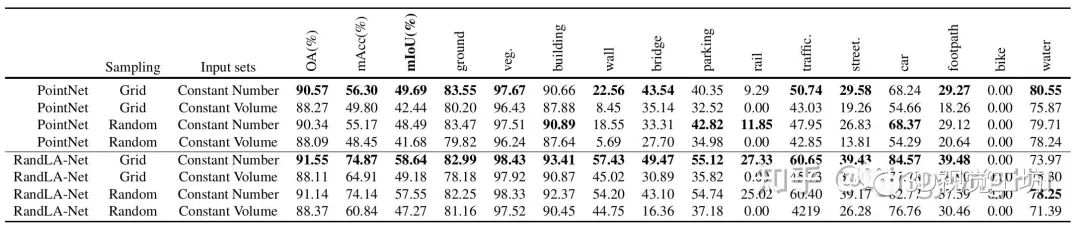
第一步使用网格下采样能得到更好的结果;
相比与恒定体积输入集,在恒定密度输入时基于PointNet或RandLA-Net的框架均能获得更好的分割结果;
总的来说,数据准备对于处理大规模城市点云确实非常重要。不同的预处理步骤带来的性能差距在10%(mIoU)以上,因此有必要进一步探索更为有效、统一的数据准备方法
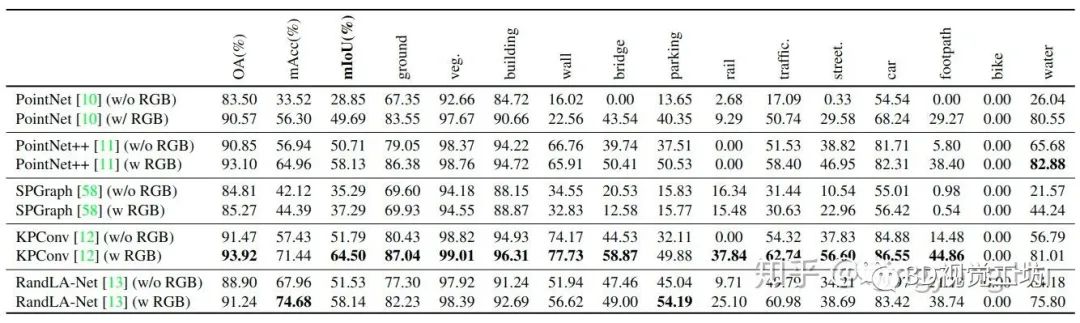
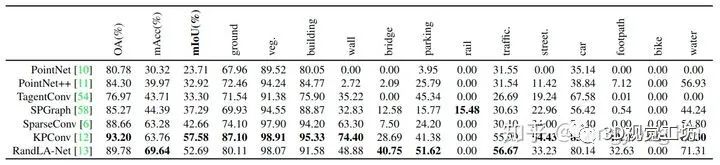
输入几何坐标以及颜色信息时,PointNet/PointNet ++,KPConv和RandLA-Net均可实现更高的分割精度。这是因为如果仅提供3D坐标,许多城市中的语义类别在本质上就无法区分(例如,桥梁,水与地面);
对于SPGraph,由于几何分区性能主要取决于输入点云的几何坐标,因为增加RGB信息后并不会对性能有明显的提升;
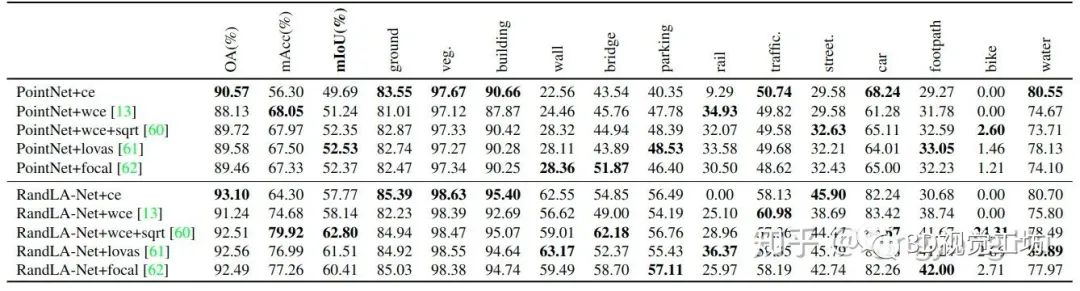
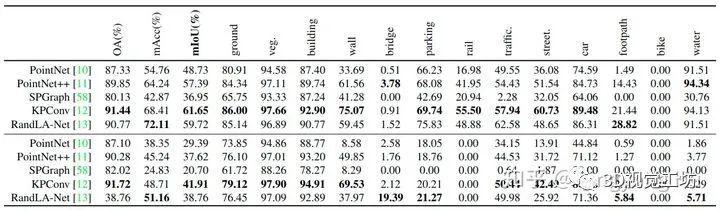
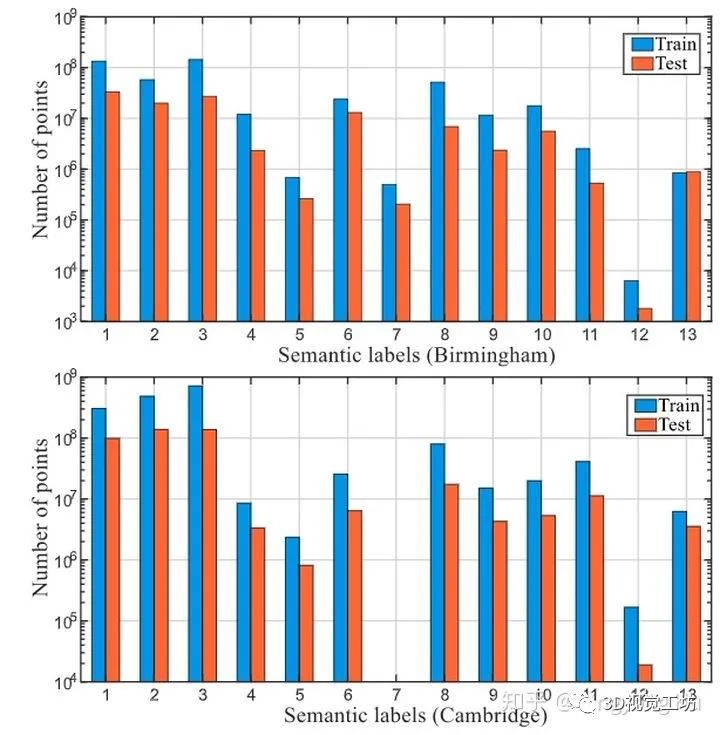
不均衡的语义类别分布可能是阻碍模型泛化能力的关键因素,因为模型倾向于拟合主要类别,而无法很好地学习到次要类别的鲁棒性;
很难将某些城市类别的形态变化从一个数据集推广到另一个数据集。
由于缺乏有效的数据集,这个问题并没有被广泛关注。然而,我们认为该问题具有非常重要的意义
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿 
▲长按关注公众号
▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、orb-slam3等视频课程)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款 
圈里有高质量教程资料、可答疑解惑、助你高效解决问题 觉得有用,麻烦给个赞和在看~ 

