生信宝典
生信宝典




除了数理统计,今天我们继续聊一下R语言的另一个任务:绘图。
基础绘图包包括 :高级绘图函数和低级绘图函数。plot()函数是不是特别简单?其实它是基础绘图包中的高级绘图函数。基础绘图包在R语言被安装后即存在,可直接使用,永不升级。基础绘图包不算Low,很多CNS文章仍在使用。”钻石恒久远、经典永留存“,所谓颜值不在于绘图包是否高级,主要在于线条的粗细、精心的排版、文字与图形之间的比例、以及有点儿"品位"的颜色搭配。 基础绘图包中的高级绘图函数,包括:plot()泛型函数(generic method)、boxplot()盒型图、barplot()条形图、hist()直方图或金字塔图、pie()饼图、dotchart()克利夫兰点图和coplot()条件图等(后两个有些冷门)。这里有一个实践过程中容易混淆的地方:大部分par()函数的参数(即:函数中的参数,不是低级绘图函数)不仅可以自己使用,也可以直接在上述其它高级绘图函数中使用,效果等同于在par()中使用(par是什么?看我们之前的一篇的文章:点我)。一些参数只能在par()中使用,高级绘图函数无法实现其功能,如: ask; fig; fin; lheight; mai; mar; mfcol; mfrow; mfg; new; oma; omd; omi; pin; plt; ps; pty; usr; xlog; ylog等(注意:这些是函数内部的参数,不是函数)。 基础绘图包中的低级绘图函数,无法(凭空)绘图,即只有在高级绘图函数绘制出来的图形中有效,如:text()加文本, legned()加图例, axis()绘制坐标轴, points()加散点, titles()加标题, arrows()加箭头, box()绘制图形边框, abline()加直线, clip()修剪图形, locator()识别图中的点的坐标, layout()切分画布, lines()加线条, segments()加线段, rug()加小地毯, polygon()构建多边形, mtext()在图形四周添加文字, grid()添加背景网格线。 高级绘图包(注意与基础绘图包的高级绘图函数是两码事儿),包括ggplot2包、maps包、曼哈顿图等。这些包需要额外安装、加载,且必须与R的版本相匹配,也可能互相依赖,故经常出现版本不可用的问题。最新版的R可能已经自带一些高级绘图包,但不全。你也可以开发一个新的、风靡学界的高级绘图包,并留上你的名字等印记,顺带着发个SCI,不用买试剂、做实验,一样可以被高引用、对科学有所贡献。高级绘图包单独作为一个系列放在聊生信公众号后续的文章中。
methods(plot)## [1] plot.acf* plot.data.frame* plot.decomposed.ts*
## [4] plot.default plot.dendrogram* plot.density*
## [7] plot.ecdf plot.factor* plot.formula*
## [10] plot.function plot.hclust* plot.histogram*
## [13] plot.HoltWinters* plot.isoreg* plot.lm*
## [16] plot.medpolish* plot.mlm* plot.ppr*
## [19] plot.prcomp* plot.princomp* plot.profile.nls*
## [22] plot.raster* plot.spec* plot.stepfun
## [25] plot.stl* plot.table* plot.ts
## [28] plot.tskernel* plot.TukeyHSD*
## see '?methods' for accessing help and source code一、利用基础绘图包的高级绘图函数——boxplot()绘制盒型图(或叫箱线图)
生成一个随机数:
rnorm(40) # rnorm()函数用于生成一个数值向量,其中的数值符合正态分布(随机生成);默认mean = 0, sd = 1,即平均值为0,标准差为1## [1] 0.73359740 -0.32093259 0.05099123 -1.14747108 -0.29760444 -0.19115771
## [7] -0.18050401 -0.65705753 -0.58041793 -0.18732920 0.25136324 1.80564477
## [13] -0.30739795 1.72920486 -1.24785193 -0.06134842 0.29841122 0.29935828
## [19] 0.60156069 0.80647689 0.44584861 -0.10413528 -1.61214793 -2.21374982
## [25] -0.13816031 -0.03873687 -0.87576900 -0.01112754 -0.57068791 -0.04539396
## [31] 1.63399958 -0.17046456 -0.18404878 0.65711950 1.99138871 -0.29185956
## [37] -0.62310740 0.83584807 1.11986269 -0.58150804附加一些关于数据的统计知识:
一个由多个数值组成的数值向量,一般具有:平均值、最大值、最小值、中值(又称中位数,是指将统计总体当中的各个变量值按大小顺序排列起来,形成一个数列,处于变量数列中间位置的变量值就称为中位数)、方差等。这些统计值用来反映数据的总体特征。
四分位数是通过3个点将全部数据等分为4部分,其中每部分包含25%的数据。很显然,中间的四分位数就是中位数,因此通常所说的四分位数是指处在25%位置上的数值(称为下四分位数)和处在75%位置上的数值(称为上四分位数)。
所谓统计学中的箱线图(box plot)就是对四分位数的绘图。
所谓正态分布(Normal distribution),也称“常态分布”,又名高斯分布(Gaussian distribution)。若随机变量X服从一个数学期望为μ、方差为σ2的正态分布,则记为N(μ,σ2)。正态分布的期望值μ决定了其概率密度图的位置,标准差σ决定了分布的幅度。当μ = 0, σ = 1时的正态分布是标准正态分布N(0,1)。
boxplot(rnorm(40)) #绘制一组符合正态分布的随机数据的盒型图,rnorm()函数用于产生服从标准正态分布N(0,1)的随机数,我们此时产生了40个。
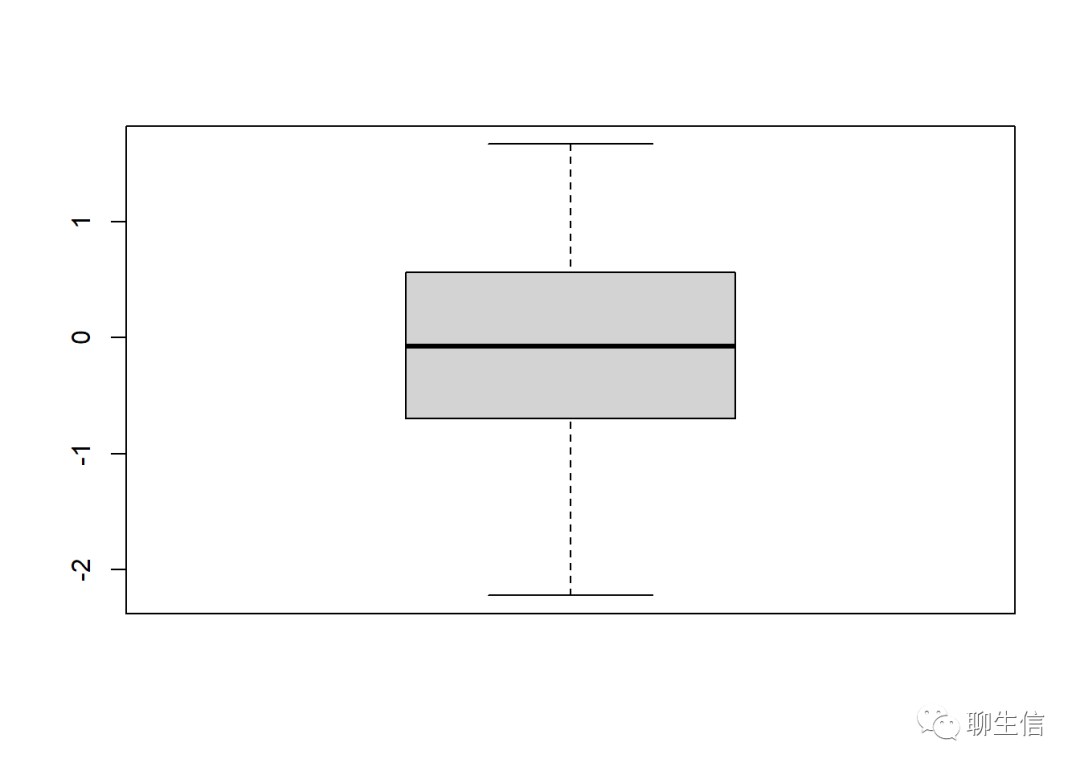
跟上图完全一样的代码再画一次图,然后比较这两个图的区别:
boxplot(rnorm(40))
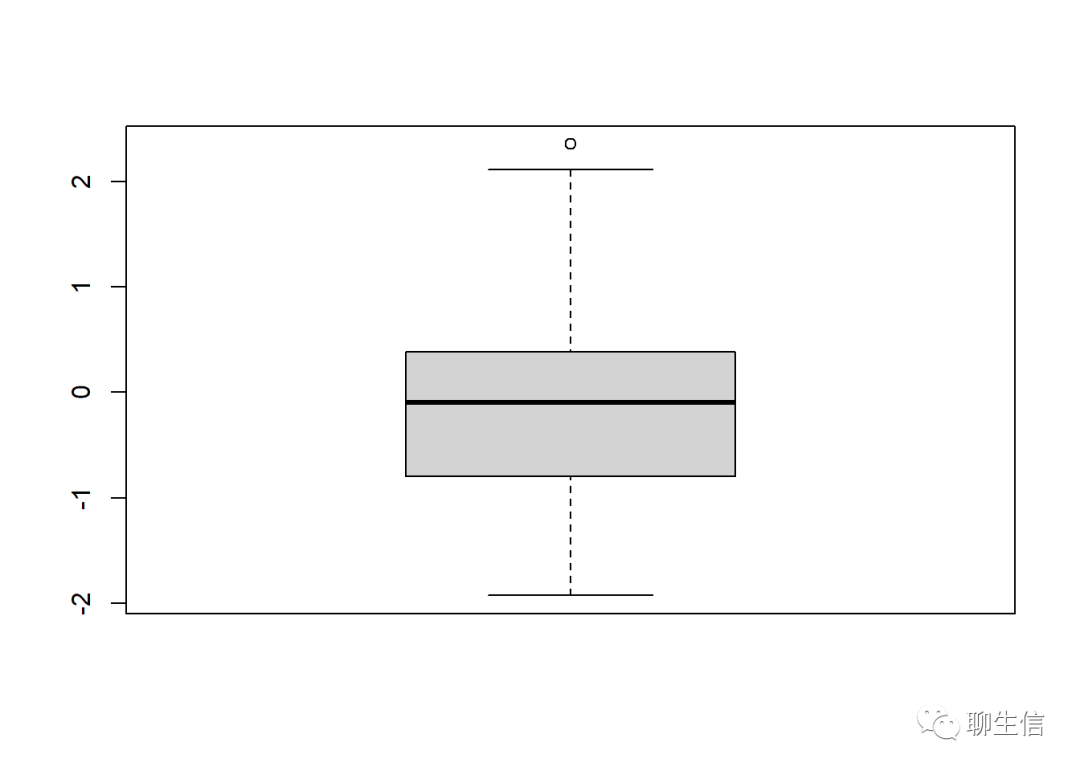
上述代码如果多运行几次,会发现:同样的代码,每次获得的图形略有不同。比如:坐标轴刻度;箱线图的最上面和最下面(胡须):有时候有小原点(异常值),有时候没有。每次获得的图形不同,是因为每次获得了不同的随机数。若想保证多次取到同一组随机数(利于代码、绘图的可重复性),则需要设置随机数种子set.seed(100)。
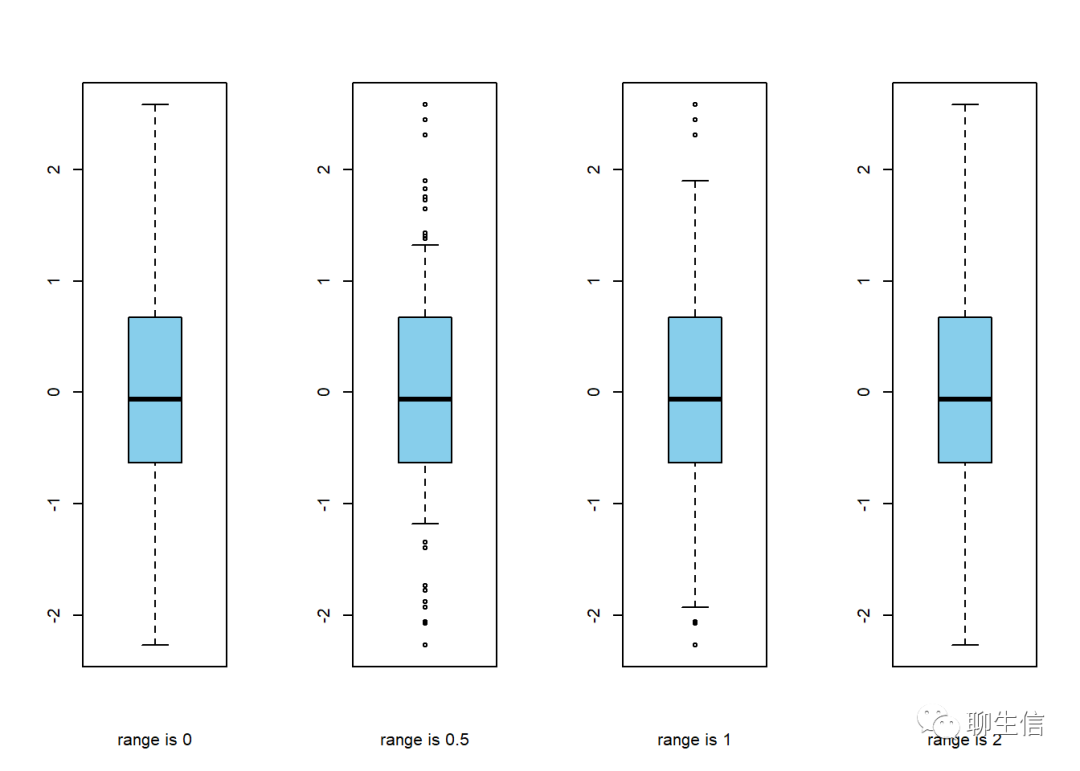
另外,若想控制箱线图的最上面和最下面(胡须)附近的小原点(异常值),可设置boxplot的range参数:
par(mfrow=c(1,4))
set.seed(100) #设置随机数种子,以保证多次取到同一组随机数,利于代码的可重复性。
data=rnorm(100) # 产生100个服从标准正态分布的随机数
boxplot(data, range=0, xlab='range is 0', col='skyblue')
#range为范围函数,表示覆盖本体极端值间距的倍数(即:决定箱线图最上沿及最下沿对箱体的覆盖区域)。
# range: this determines how far the plot whiskers extend out from the box. If range is positive, the whiskers extend to the most extreme data point which is no more than range times the interquartile range from the box. A value of zero causes the whiskers to extend to the data extremes.
boxplot(data, range=0.5,xlab='range is 0.5',col='skyblue')
boxplot(data, range=1, xlab='range is 1', col='skyblue')
boxplot(data, range=2, xlab='range is 2', col='skyblue')
##相关参数介绍:
#width设置box相对宽度;boxwex设置box宽度,取值越大盒子越宽
#outline逻辑参数,是否绘制离群点,默认为T,即绘制离群点
#notch逻辑参数,是否使用卡槽,默认为F
#names设置盒型图中各个box的标签(并不是这整个盒型图的标签)
#horizontal逻辑参数,是否横向放置盒型图,默认为F,即纵向放置
#add逻辑参数,是否将盒型图添加到现有图形上
#at配合add使用,该盒型图的横坐标位置的定义
# 建议每次看缭乱的代码之前,先细看后面画出的图,更容易看懂代码
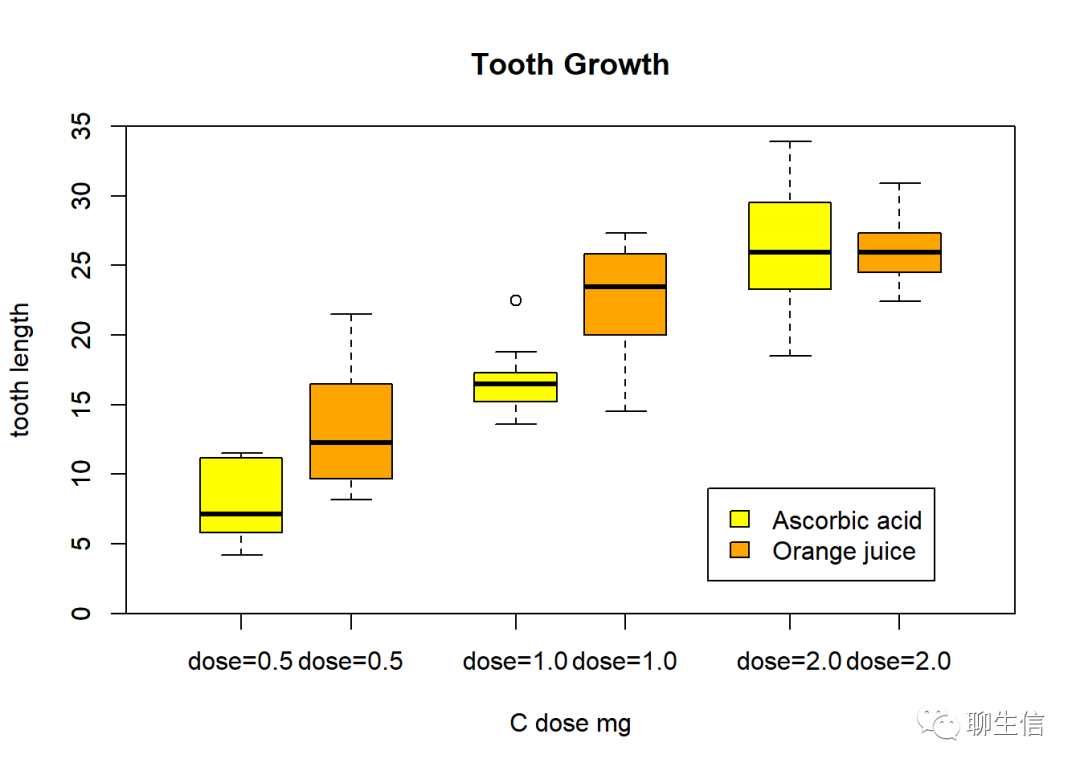
boxplot(len~dose,#绘制变量len与dose的盒型图(前者为连续型变量,后者是分类变量)
data=ToothGrowth,#使用R语言内置数据集ToothGrowth
boxwex=0.3,at=1:3-0.2,#at参数定义了图中盒子横坐标位置为0.8,1.8,2.8
subset=supp=="VC",#采集ToothGrowth中supp为VC的数据,即此处只绘制VC数据
col="yellow",
names=c('dose=0.5','dose=1.0','dose=2.0'),
main="Tooth Growth",
xlab="C dose mg",
ylab="tooth length",
xlim=c(0.5,3.5),ylim=c(0,35),
yaxs="i")
boxplot(len~dose,
data=ToothGrowth,
add=TRUE,
boxwex=0.3,
at=1:3+0.2,
names=c('dose=0.5','dose=1.0','dose=2.0'),
subset=supp=="OJ",
col="orange")
legend(2.5, 9, c("Ascorbic acid", "Orange juice"),
fill = c("yellow", "orange"))
#legned()为低级绘图函数: 加图例
names=c(rep("Maestro",20),rep("Presto",20),
rep("Nerak",20),rep("Eskimo",20),rep("Nairobi",20),rep("Artiko",20))
value=c(sample(3:10,20,replace=T),sample(2:5,20,replace=T),
sample(6:10,20,replace=T),sample(6:10,20,replace=T),
sample(1:7,20,replace=T),sample(3:10,20,replace=T))
data=data.frame(names,value)
data$names = as.factor(data$names)
#这是十分关键的一步!——将data中的names数据由向量属性(vector)改为因子属性(factor)
#由于data中默认所有数据均为向量属性,而boxplot函数只可以识别factor,若不手动更改其属性,则以下代码将无法正常运行。
#tips:R拥有许多用于存储数据的对象类型,包括标量、向量、矩阵、数组、数据框、列表及因子。
boxplot(data$value~data$names,
col=ifelse(levels(data$names)=="Nairobi",
"lightblue",
ifelse(levels(data$names)=="Eskimo",
"mediumpurple3",
"grey75")),
ylab="disease",xlab="- variety -")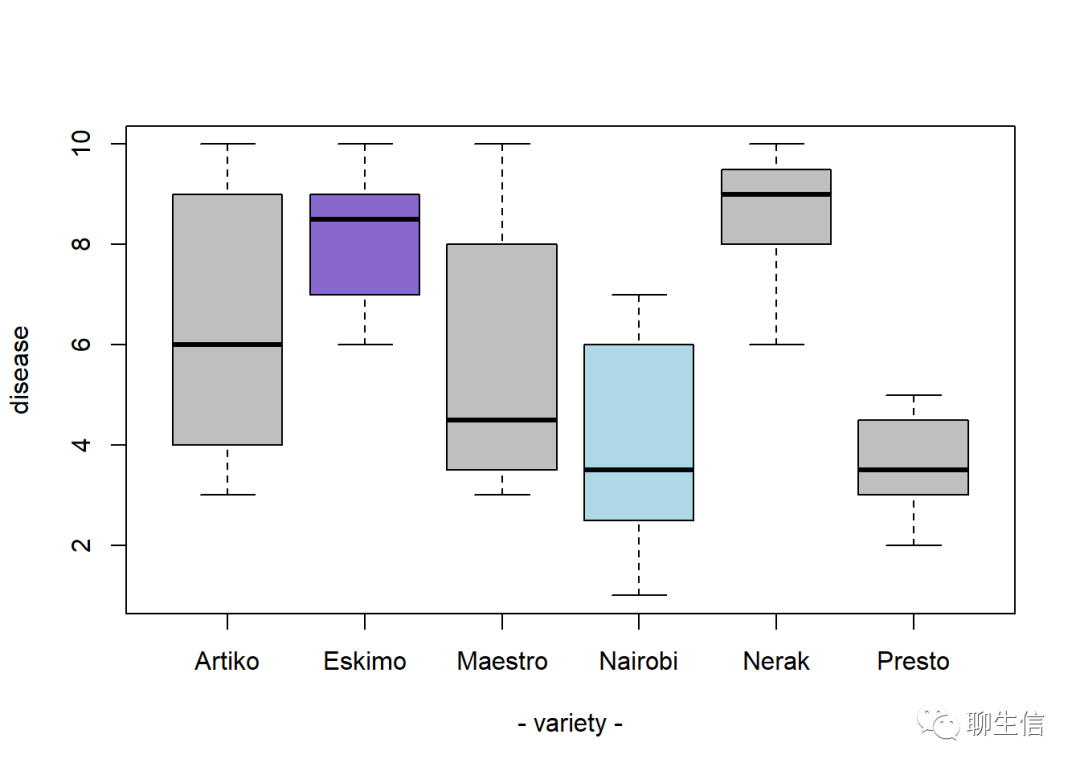
#这里出现了一个新函数!记得拿出小本本积累下来~~ifelse()使用方法为:ifelse(test, yes, no)。若输入"test"成立,则输出"yes",不成立则输出"no"
#在这里表示,若names=Nairobi,则将其显示为"lightblue",若names≠Nairobi,则进行第二次ifelse函数判断。(即若names=Eskimo,则将其输出为"mediumpurple3",若names≠Eskimo,则输出为"grey75")
#盒型图默认按照所给数据名称首字母进行排序,如何根据其他指标对盒型进行排序,让图形更美观呢?
#这里以各box中数据中位数排序举例:
data$names = as.factor(data$names)
data$value = as.numeric(data$value)
order_names <- with(data,reorder(names,value,median,na.rm=TRUE))
#对names进行重新排序,标准为median(value),即value中位数。
boxplot(data$value~order_names,col='salmon',ylab="disease",xlab="- variety -")
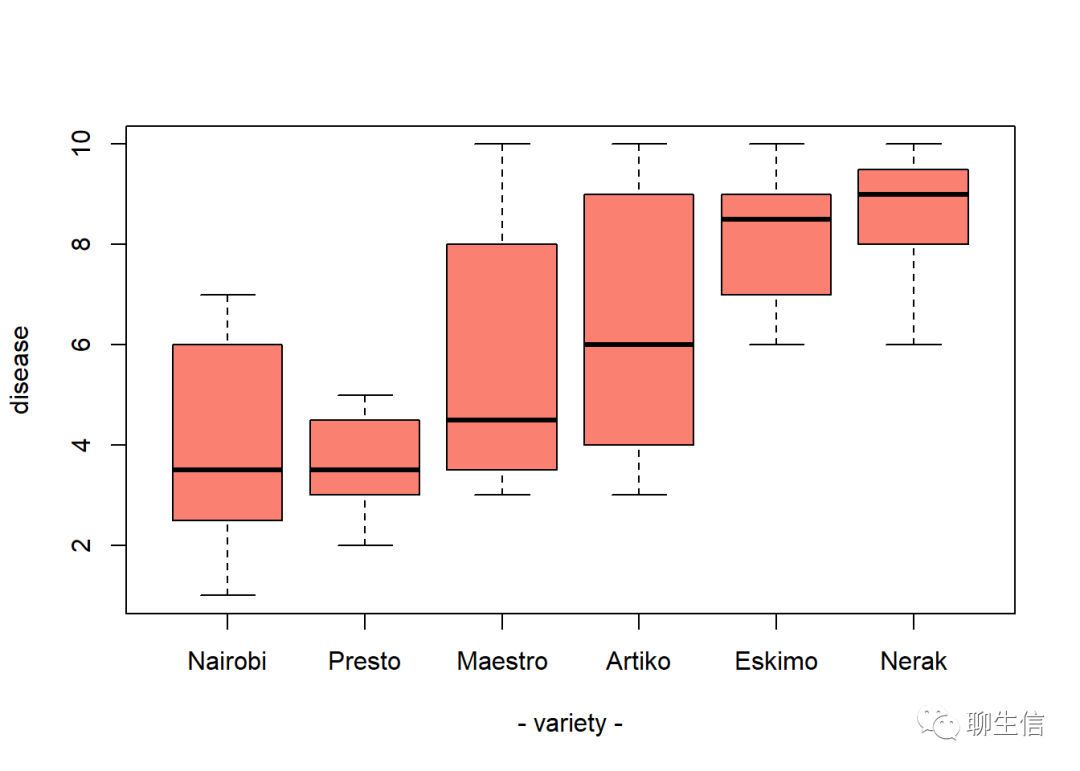
#新函数reorder()使用方法:reorder(x,y,z),x为需要重排的因子变量,y为排序标准,z为函数名称二、利用基础绘图包的高级绘图函数——barplot()绘制条形图(或叫直方图)
##相关参数介绍:
#height:用于设置条形高度
#width:用于设置条柱宽度,默认为1
#space:用于设置条柱间隔
#names.arg:用于设置条形图标签,即自定义各条带名称
#horiz:逻辑参数,是否使用水平条柱
#plot:逻辑参数,是否画图
#add:逻辑参数,是否将条形图添加到现有的图形上
data <- sample(c(10:100),10)#生成10个10-100之间的随机整数
barplot(data,col=rainbow(10,s=0.5))
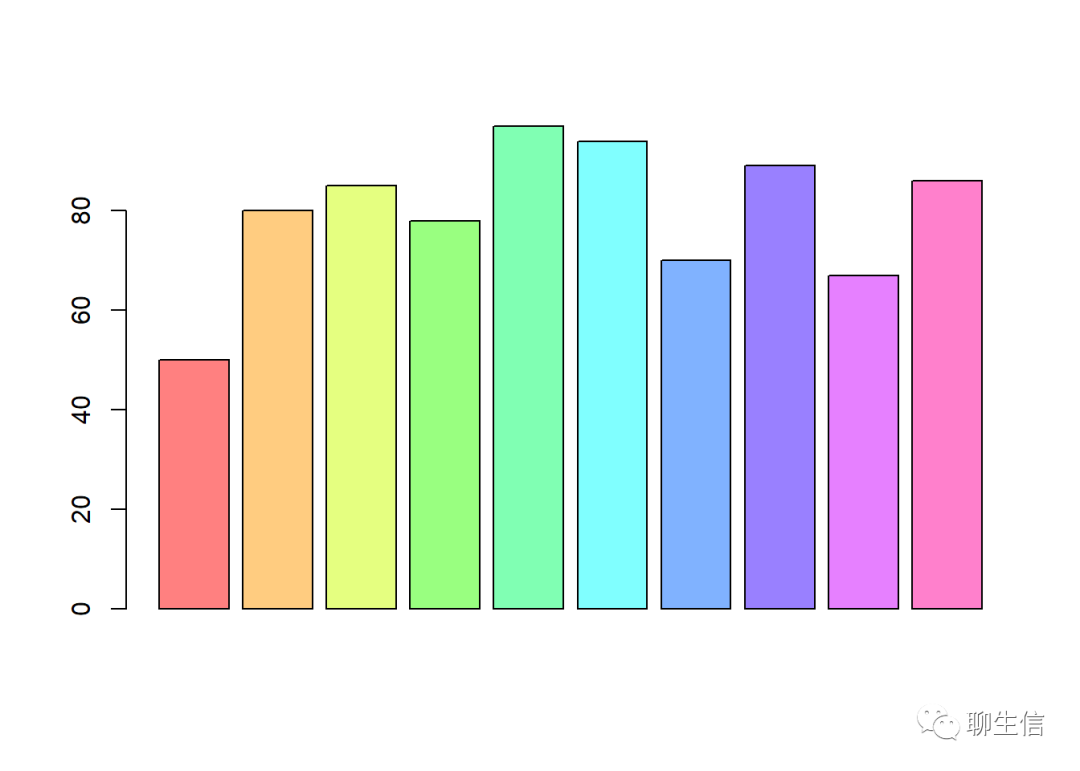
#将这10个随机数传入barplot()函数,使用rainbow()内置函数生成彩虹色,并将饱和度s调至0.5set.seed(10)
par(mfrow=c(1,3), cex.main=2)
my_matrix <- matrix(data = sample(10:50,9),nrow = 3,dimnames = list(c('A','B','C'),paste(1:3)))
#生成一个3行3列的矩阵,行名(dimnames)为、B、C,列名(paste)为1、2、3
barplot(my_matrix,beside = T,col=c('rosybrown',' wheat','seashell'),main = '原始条形图')
#beside参数表示是否将条柱平行放置,若为F则堆栈放置
barplot(t(my_matrix),beside = T,col=c('rosybrown',' wheat','seashell'),main = '行列互换后条形图')
#t()函数为专置函数,即将矩阵行列进行互换
barplot(t(my_matrix),beside = F,col=c('rosybrown',' wheat','seashell'),main = '堆栈放置')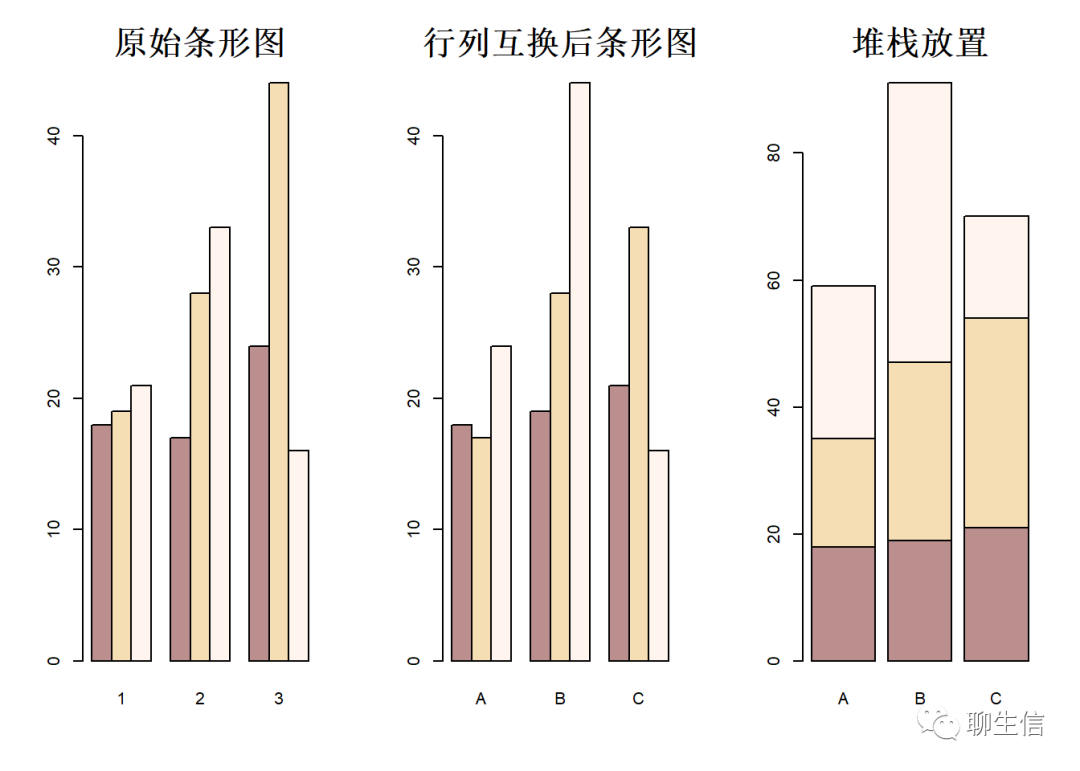
par(mfrow=c(2,2),bg='navajowhite')
average_gdp <- c(10000,8000,13000,9200)
country <- c('China','Korea','Japan','Singapore')
#构造一个数据,用于表示四个国家人均GDP。
barplot(average_gdp,names.arg = country,col=heat.colors(4))
#为每一个条柱添加标签#heat.colors()函数为生成一个从红色渐变到黄色再到白色的暖色系。
barplot(average_gdp,names.arg = country,horiz = TRUE,col=heat.colors(4))
#horiz = TRUE设置水平放置条图
barplot(average_gdp,names.arg = country,horiz = FALSE,width = c(0.4,0.6,0.8,1.0),col=heat.colors(4))
#width设置条柱宽度
barplot(average_gdp,names.arg = country,horiz = FALSE,space = 0,col=heat.colors(4))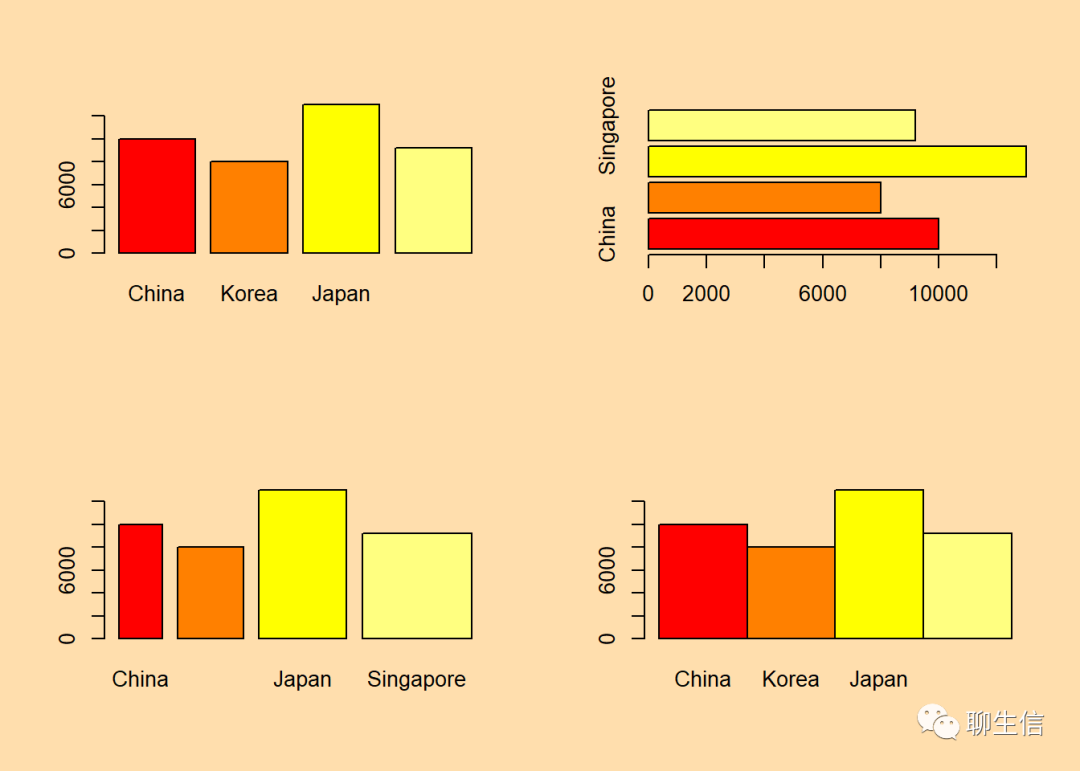
#space设置条柱间隔添加误差条
set.seed(20)
par(mfrow=c(1,2),bg='ivory')
data <- data.frame(doseA = rnorm(100,10,2),
doseB = rnorm(100,13,5),
doseC = rnorm(100,8,3))
#构建一个随机数据集,该数据集包含三个变量,分别表示三种不同的药物剂量下,小鼠的某种生理指标的变化水平,每一组均含有100个研究对象。
#rnorm(100,10,2)为随机取100个值,平均值为10,方差为2
#r这列代表随机,可以替换成dnorm, pnorm, qnorm 作不同计算
#r = random = 随机, d= density = 密度, p= probability = 概率 , q =quantile = 分位
data_mean <- apply(data,2,mean)#生成每一组的平均数
#新函数apply()表示将data数据中第2列取平均值。(1代表行,2代表列,也可写作c(1,2))
data_sd <- apply(data,2,sd)#生成每一组的标准差。
barcenters <- barplot(data_mean,names.arg = names(data_mean),ylim = c(0,20))
#将barplot()存入一个对象中,这个对象保存的是条柱的中心位置的横坐标
#names.arg参数为定义标签名称
segments(barcenters,data_mean-data_sd,barcenters,data_mean+data_sd,lty=1.2)
#segments()加线段
arrows(barcenters,data_mean-data_sd,barcenters,data_mean+data_sd,code =3,angle = 45)
#arrows()加箭头
#运用segments()和arrows(),两个低级绘图函数,这两个函数都接受x0,y0,x1,y1四个数值,分别表示起始点和终止点坐标。
#code可取1、2、3分别代表显示下箭头、上箭头、双箭头,angle代表箭头角度,取90时代表一条直线
#适度美化
A=c(rep("drug A",10),rep("drug B",10))
B=rnorm(20,10,4)
C=rnorm(20,8,3)
D=rnorm(20,5,4)
data = data.frame(A,B,C,D)
#生成数据框
colnames(data)=c("treatment","dose_1","dose_2","dose_3")
#重新命名数据集列名
sigbio=aggregate(cbind(dose_1,dose_2,dose_3)~treatment,data=data,mean)
#计算不同疗法下,不同剂量效果平均值
#新函数aggregate(formula, data, FUN, ..., subset, na.action = na.omit),
#formula处可以放一个公式,此处我们使用了cbind(), FUN代表可以在其中套用其他函数
#cbind(a,b,c)中矩阵a,b,c的行数必需相符,根据列进行合并,即叠加所有列,并有rbind()函数为叠加所有行
rownames(sigbio)=sigbio[,1]
sigbio=as.matrix(sigbio[,-1])
lim=1.2*max(sigbio)
error.bar <- function(x,y,upper,lower=upper,length=0.1,...){
arrows(x,y+upper,x,y-lower,angle = 90,code = 3,length = length,...)
}
stdev=aggregate(cbind(dose_1,dose_2,dose_3)~treatment,data = data,sd)
rownames(stdev)=stdev[,1]
stdev=as.matrix(stdev[,-1])*1.96/10
ze_barplot=barplot(sigbio,beside = T,legend.text = T,col=c('blue','skyblue'),
ylim=c(0,lim),ylab = "height")
error.bar(ze_barplot,sigbio,stdev)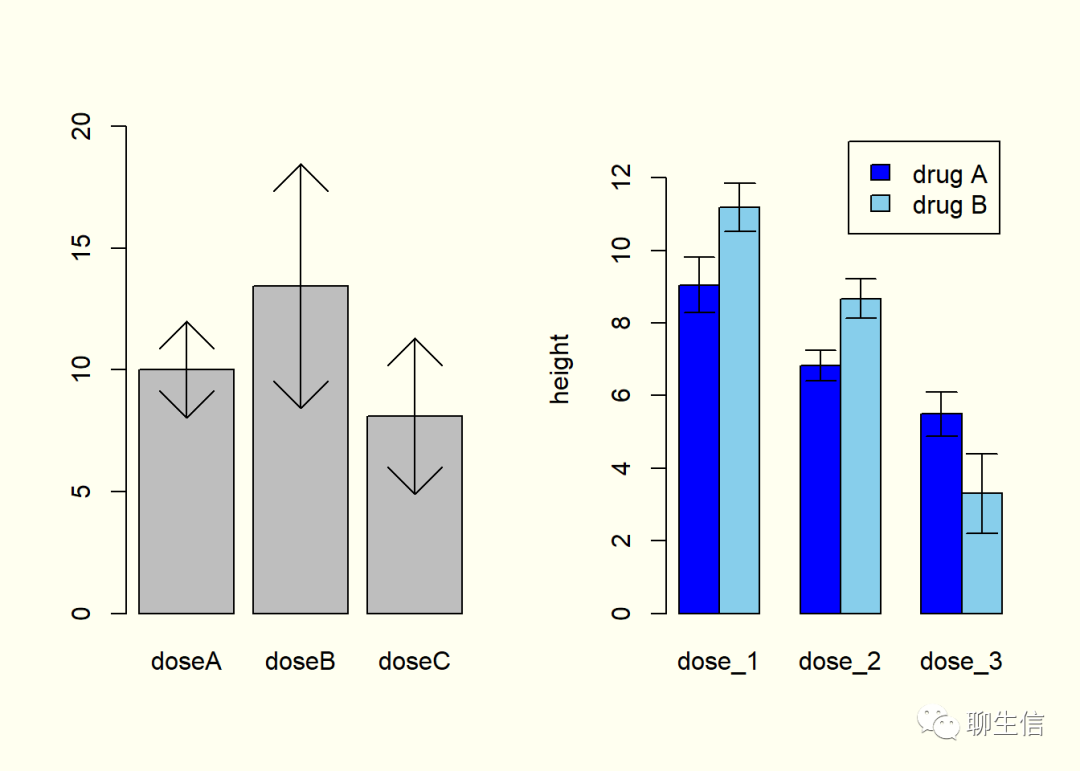
#直方图独有的参数介绍:
#breaks:截断参数表示直方图具体的区间范围
#freq:逻辑参数,表示是否显示频数,默认为T,若设置为F,则显示概率密度图
#include.lowest:逻辑参数,表示是否包括最小值,可配合breaks参数使用
#right:逻辑参数,表示是否包括最大值,使用方法同include.lowest
#density:是否添加图中斜线(shading lines),注意不是添加密度线
#angle:表示shading lines的斜率,默认为45°
##绘制直方图
op <- par(mfrow=c(2,3))
set.seed(100)
data <- rnorm(200,10,5)
hist(data,col = 'light green')
#原始默认直方图
hist(data,col = 'skyblue',breaks = 15)
#breaks = 15表示将原始数据分隔成10组
hist(data,col = 'orange',breaks = seq(-5,25,1))
#seq()函数用于产生一组有规律的数值,seq(-5,25,1)表示从-5到25取值,间距为1
hist(data,col = 'pink',breaks = seq(-5,25,1),density = TRUE,angle=45)
#添加shading lines,并设置角度为45°
hist(data,col = 'yellow',breaks = seq(-5,25,1),freq = F)
lines(density(data),col='blue',lty=3,lwd=2)
#显示概率密度图
hist(data,col = 'pink',breaks = seq(-5,25,1),freq = F,axes=F,main='聊生信教学图例',xlab = '',ylab='')
lines(density(data),col='sienna',lty=1,lwd=1)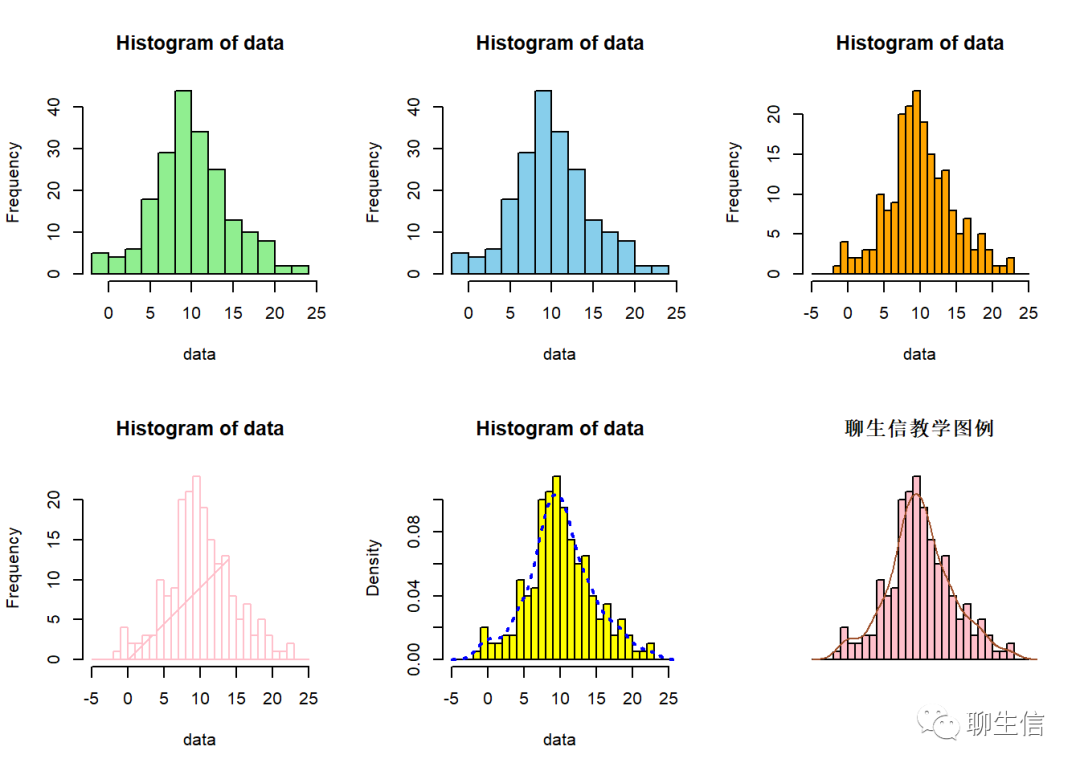
#可自行运用上期介绍各参数进行自定义直方图样式
par(op)
#释放以上参数##直方图叠加:
#install.packages("effects")
#前文中的操作我们使用R中自带的程序包即可完成,在此我们学习安装并使用新包.
#新包"effects"
library(effects)## Loading required package: carData## lattice theme set by effectsTheme()
## See ?effectsTheme for details.data("TitanicSurvival")#调用新包中"TitanicSurvival"这一数据
hist(TitanicSurvival$age,main = '泰坦尼克号不同年龄游客生存死亡占比直方图',
xlab = '年龄',ylab = '占比',col = 'skyblue',breaks = seq(0,80,1))
#绘制年龄分布图,从0~80岁,每两岁画一个条柱
hist(TitanicSurvival$age[which(TitanicSurvival$survived=='no')],
col = 'indianred',add=T,breaks = seq(0,80,1))
#add参数为T时,表示在当前年龄分布图上添加另一个直方图,此处我们添加的为survived=='no',即不同年龄死亡比例.
legend(60, 40, c("存活", "死亡"),
fill = c("skyblue", "indianred"))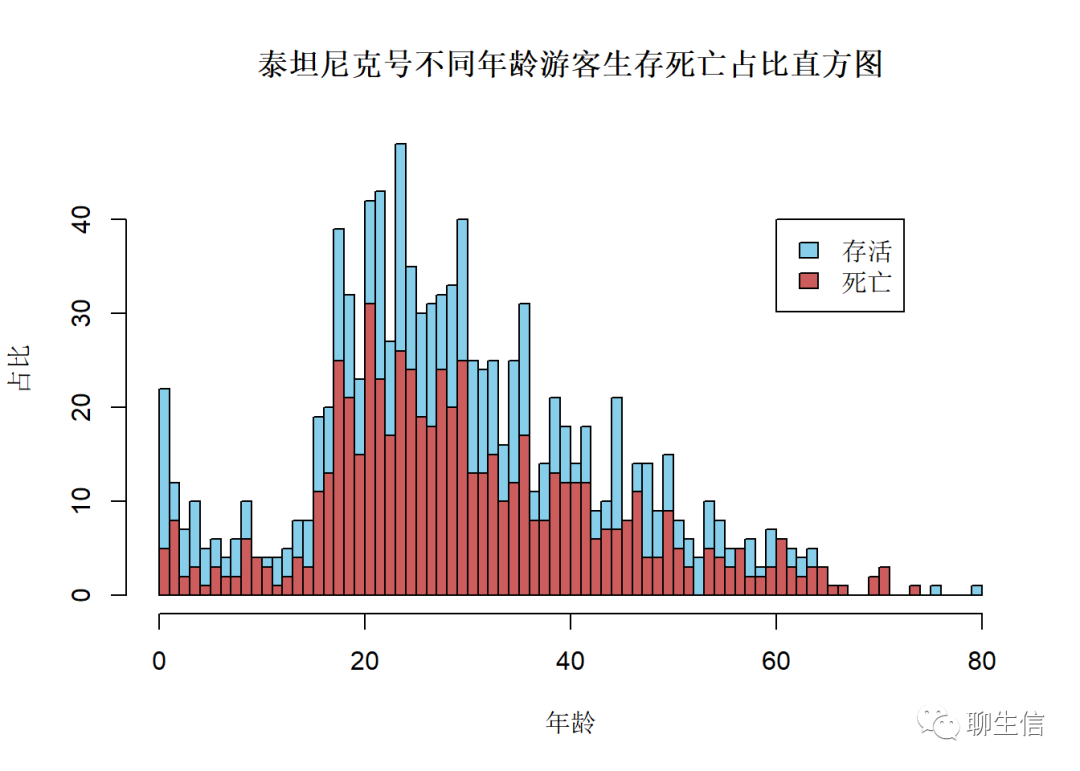
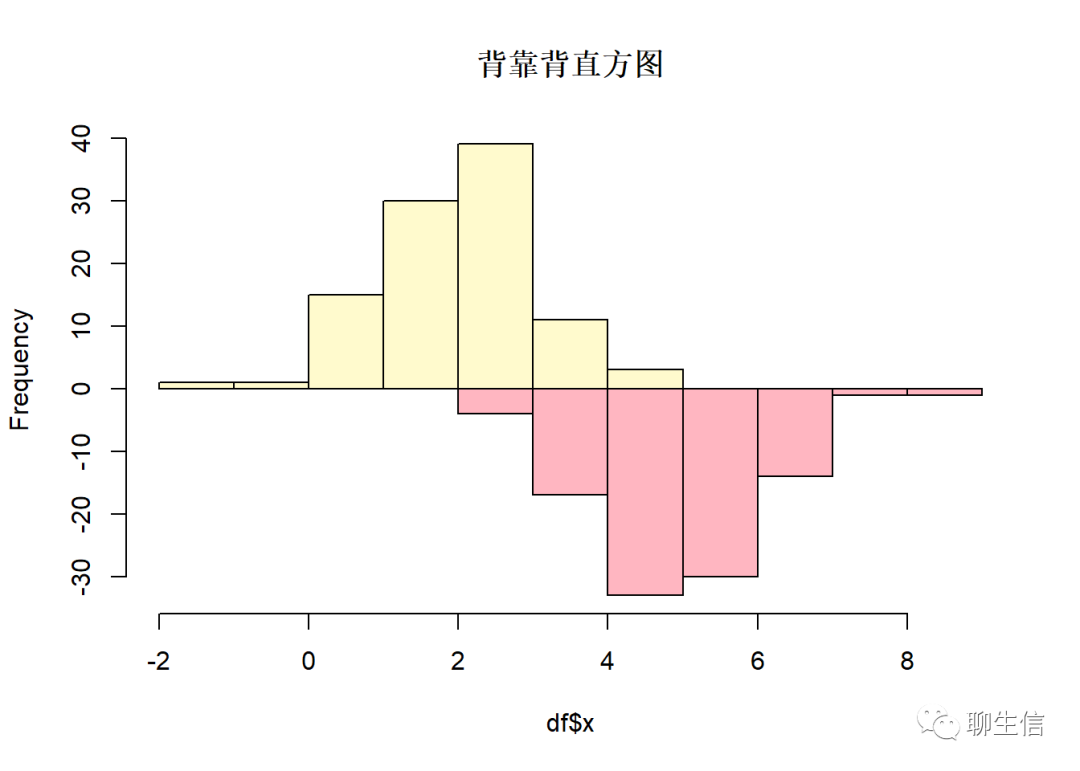
##背靠背直方图
df=data.frame(x=rnorm(100,mean=2),x2=rnorm(100,mean=5))
h1=hist(df$x,plot = F)
h2=hist(df$x2,plot = F)
#绘制两个直方图,数据存在h1h2两个对象中
h2$counts= - h2$counts
#将h2的值反过来
hmax= max(h1$counts)
hmin= min(h2$counts)
#设置y轴取值范围
X = c(h1$breaks,h2$breaks)
xmax = max(X)
xmin = min(X)
#设置x轴取值范围
plot(h1,ylim = c(hmin,hmax),col="lemonchiffon",
xlim = c(xmin,xmax),main = '背靠背直方图')
lines(h2,col='lightpink')
##金字塔图--PlotPyramid()
#install.packages('DescTools')#下载新包
library(DescTools)
#lx:接受一个数值向量或一个矩阵.当lx为一个向量时,则该向量用来绘制左半边的条形图或直方图;当为一个矩阵时,该矩阵的第一列数据用来绘制左半边的图,第二列绘制右半边的图,自动忽略其他列.
#rx:若lx为矩阵时,该参数无作用.若lx为一个数值向量时,则rx接受一个相同长度的数值向量,用来绘制右半边的图.
#ylab:设置y轴标签,接受一个字符串向量.
#ylab.x:y轴标签的位置参数,默认为0,即标签位于x=0的位置,也就是图的正中间.
#border:设置图形的边框,当不需要边框是,设置border=NA.
#lxlab,rxlab:设置左右两张图的x轴标签.
#gapwidth:设置左右两张图之间的间距,设置为0时,则无间隙.
#xaxt:设置是否绘制x轴,设置为n时,则不绘制x轴.
#args.grid:绘制背景网格,设置为NA则无背景网格.
par(mfrow=c(1,3))
m.pop <- c(3.2,3.5,3.6,3.6,3.5,3.5,3.7,3.9,3.7,3.5,3.2,2.8,2.2,1.8,1.5,1.3,0.7,0.4,0.2)
f.pop <- c(3.2,3.4,3.5,3.5,3.5,3.7,4.0,3.8,3.9,3.6,3.2,2.5,2.0,1.7,1.5,1.3,1.0,0.8,0.4)
age <- c("0-4","5-9","10-14","15-19","20-24","25-29","30-34","35-39","40-44","45-49",
"50-54","55-59","60-64","65-69","70-74","75-79","80-84","85-89","90+")
#准备数据
PlotPyramid(m.pop,f.pop,
ylab=age,space=0,
col=c("lightsteelblue","pink"),main="Age Distribution at Baseline",
lxlab="male",rxlab="female")
#绘制左侧第一张图
PlotPyramid(m.pop,f.pop,
ylab=age,space=0,
col=c("lightsteelblue","pink"),
xlim=c(-5,5),
main="Age Distribution at Baseline",
lxlab="male",rxlab="female",gapwidth=0,ylab.x=-5)
#绘制中间第二张图
PlotPyramid(c(1,3,5,2,0.5),c(2,4,6,1,0),
ylab= LETTERS[1:5],space=0.3,
col=rep(rainbow(5,s=0.5),each=2),
xlim=c(-10,10),args.grid=NA,cex.names=1.5,adj=1,
lxlab="Group A",rxlab="Group B",gapwidth=0,ylab.x=-8,xaxt="n")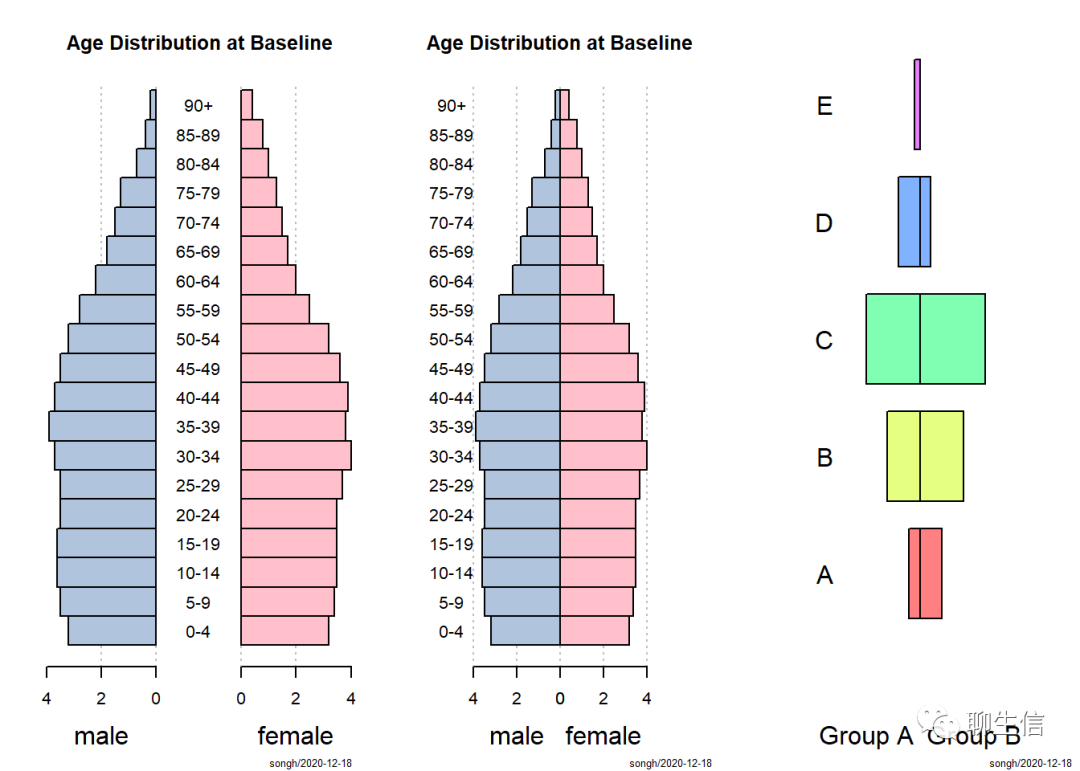
#绘制右侧第三张图##镜面图
x1= rnorm(100,mean = 2)
x2= rnorm(100,mean = 5)
par(mfrow=c(2,1))
par(mar=c(0,5,3,3))
plot(density(x1),main = "",xlab = "",ylim=c(0,1),xaxt="n",las=1,col="slateblue",lwd=4)
par(mar=c(5,5,0,3))
plot(density(x2),main = "",xlab="Value of my variable",ylim=c(1,0),las=1,col="tomato",lwd=4)
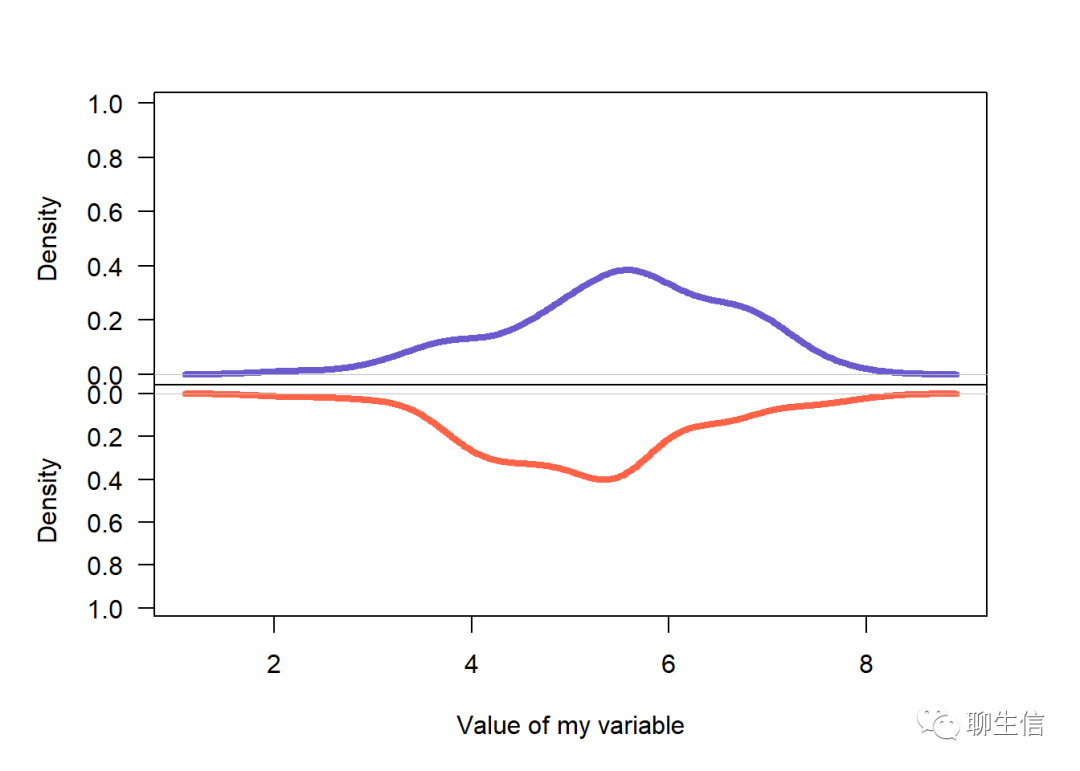
四、利用基础绘图包的高级绘图函数——pie()绘制饼图
#常用参数介绍
#x:非负数值向量,用于绘制占比情形
#edges:饼图边缘圆滑程度,取值越大越圆滑,默认值为200
#radius:饼图半径,默认为0.8
#clockwise:逻辑参数,用于确定是否采用顺时针方向绘制对应扇形,默认为F
#density:表示阴影线密度,默认值为NULL,表示没有阴影线
#border:表示划分饼的切割线的颜色
pie(rep(1,26),col = rainbow(26,s=0.7),labels = LETTERS[1:26],radius = 1,clockwise=T)
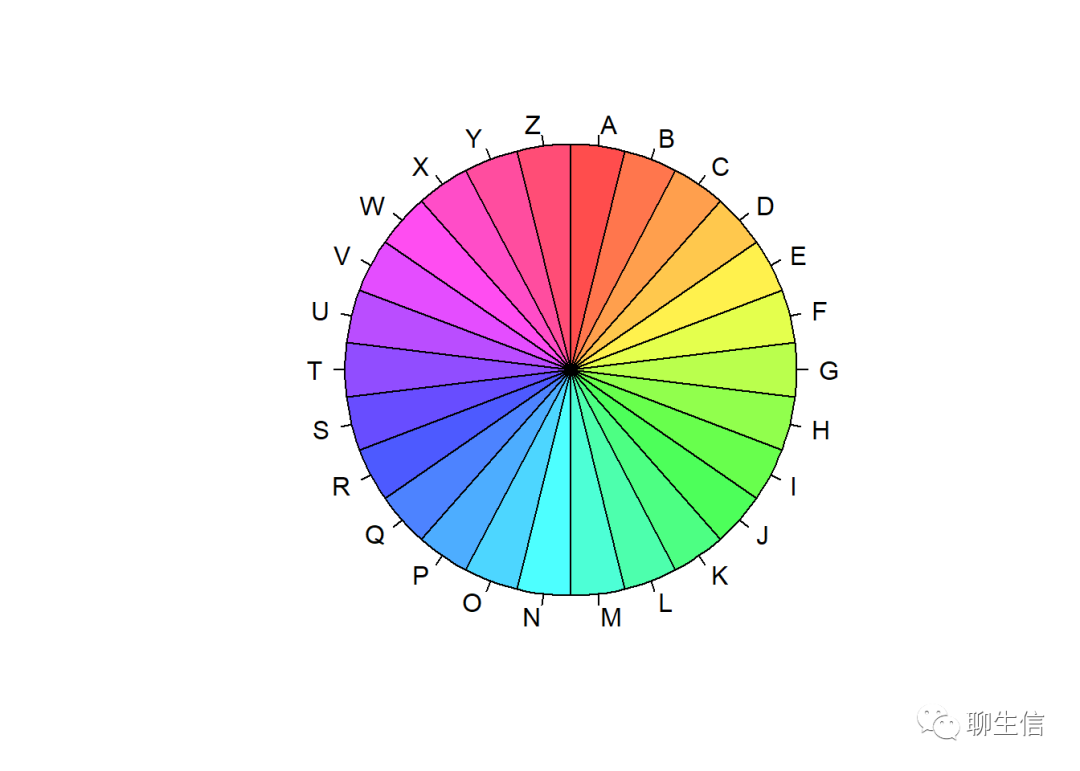
library(RColorBrewer)
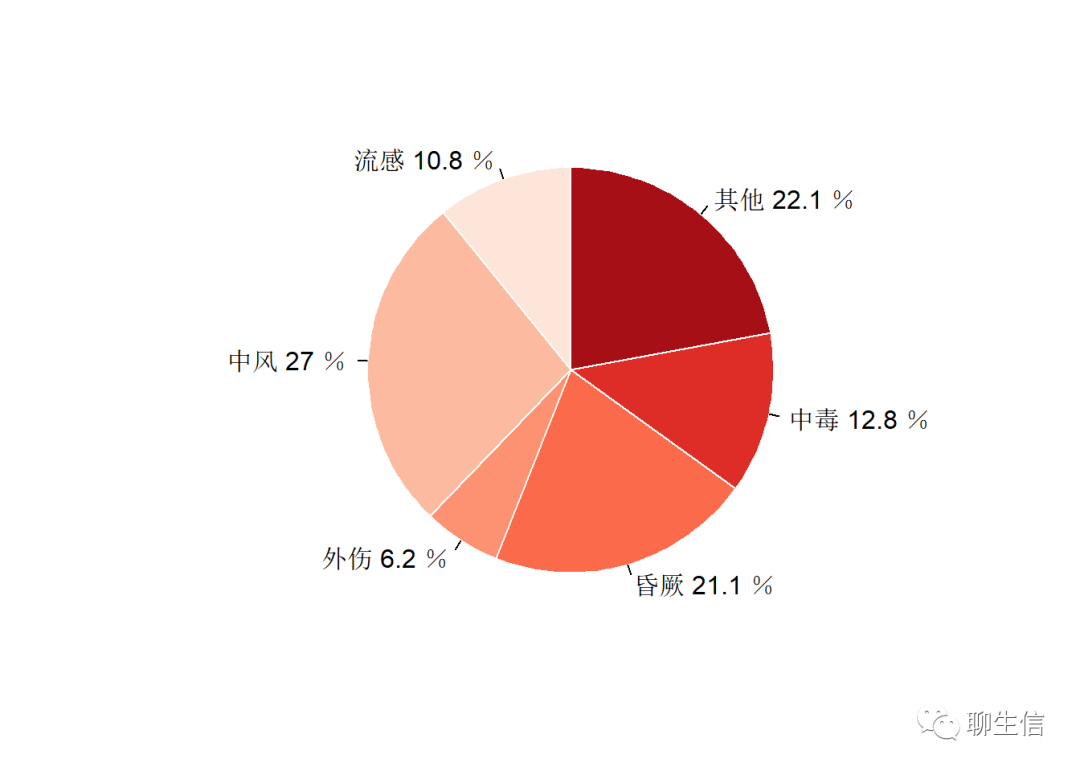
pie.mydata <- c(10.8,27.0,6.2,21.1,12.8,22.1)
diseasetypes <- c("流感","中风","外伤","昏厥","中毒","其他")
names(pie.mydata) <- paste(diseasetypes,pie.mydata,"%",sep=" ")
pie(pie.mydata,col = brewer.pal(length(pie.mydata),"Reds"),border=0,radius = 0.9,init.angle = 90)# init.angle为设置初始角度大小,顺时针是为90度,否则为0
# 总体来说基础绘图包中pie()函数能力有限,如果需要更多灵活展示,还要学习ggplot2
五、利用基础绘图包的高级绘图函数——绘制克利夫兰点图
#部分参数介绍:
#x:接受一个向量或矩阵
#groups:x的分组情况,若x为矩阵,则默认groups为该矩阵的列
#gdata:每组的值,通常为一个汇总值,比如均值或中位数
#cex, pt.cex:都是用来设置大小,前者用于字符设置,后者用于图中元素设置
#color,gcolor,lcolor:颜色参数,第一个用于设置图中点和标签;第二个用于设置组的标签和值的颜色;第三个用于设置图中水平线的颜色
op <- par(xaxs = "i")
#xaxs参数:设置坐标轴x的间隔方式。取值范围为:"r","i","e", "s","d"。
#一般来说,计算方式是由xlim的数值范围确定的(如果xlim指定了的话)。"r"(regular)首先会对数值范围向两端各延伸4%,然后在延伸后的数值区间中设置坐标值;"i"(internal)直接在原始的数据范围中设置坐标值;**"s"(standard)和"e"(extended)、;"d"(direct)目前还不支持。**
dotchart(t(VADeaths),xlim = c(0,100),main = "Death Rates in Virginia-1940",
lcolor = 'skyblue',color = 'lightsalmon',gcolor = 'mediumorchid',pch = 16)
# 使用内置数据集VADeaths
par(op)

六、利用基础绘图包的高级绘图函数——coplot()绘制条件图
#部分参数介绍:
#formula:传入一个公式.此处的公式与R基础包中的其他函数所要求的公式格式相同.一般形式为y~x,左边是因变量,右边是自变量.那么条件绘图的条件体现在哪呢?把这个公式稍微改造一下,y~x|a,注意,添加一个管道符.这个公式的意思就是在变量"a"存在的情况下,y随x的变化而变化,这就是条件的意思.
#data:传入一个数据框,必须包含你所写公式中x,y等变量
#given.values:给定一个值,可根据例子进行理解
#panel:设置面板默认为points,也可改为hist,barplot等
#rows,columns:行列参数,接受一个数值分割画布.
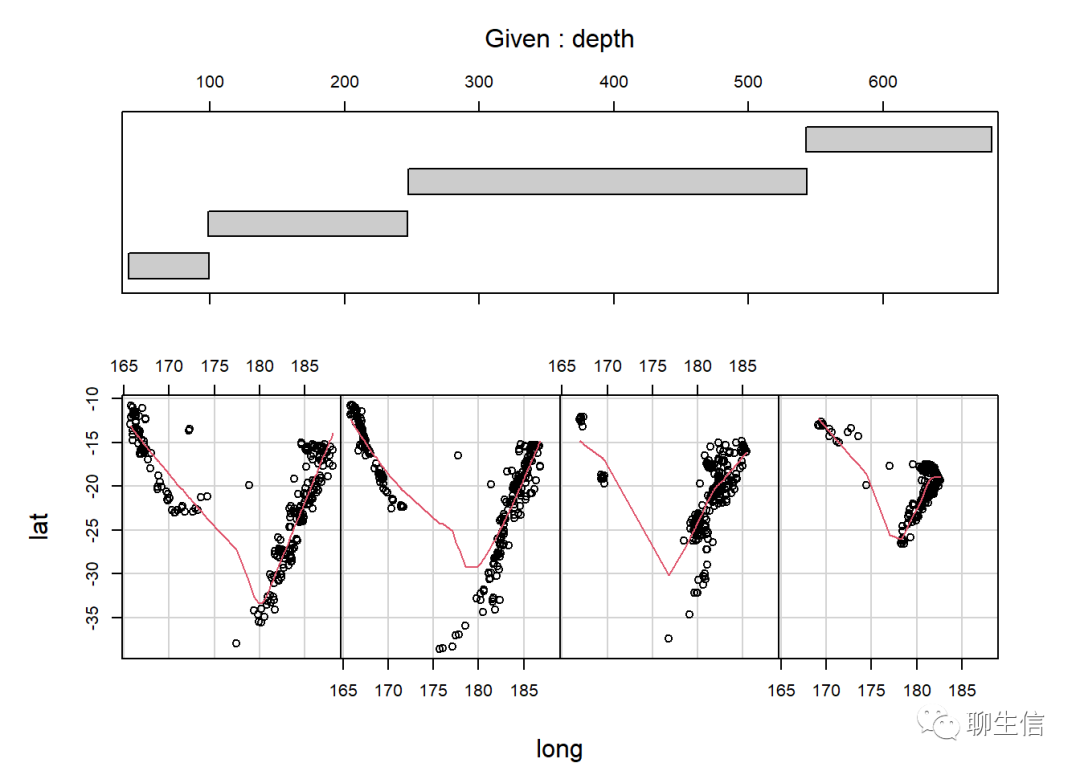
given.depth <- co.intervals(quakes$depth,number = 4,overlap = 0)
#此处调用co.intervals函数,将震源深度分为4组,且不重叠,overlap可设置为0~1,表示各组叠加程度.
coplot(lat~long|depth,data = quakes,given.values = given.depth,rows = 1,
panel = function(x,y,...)panel.smooth(x,y,span = 0.7))#此处我们定义了panel函数,如果用hist写法应该是panel=function(x,y,...)hist(x,...)
#三个点"..."表示缺省参数,因为hist()中有很多参数,不可能一一列出,所以采用 "..."表示.
以上我们就已经学习了主要的R自带的高级绘图函数,但若需要对高级绘图函数所绘制的图形进行美化,则还需要使用低级绘图函数进行修饰。将低级绘图函数与高级绘图函数结合起来使用,画出来的图才会更加专业美观。如前所述,在使用高级绘图函数进行图形绘制以后,这些低级绘图函数才会起作用,而其所起作用的范围也仅限于当前绘制出的这一幅图形。
这里简单介绍几个低级绘图函数的使用方法:
# 1. 图例的添加--legend()
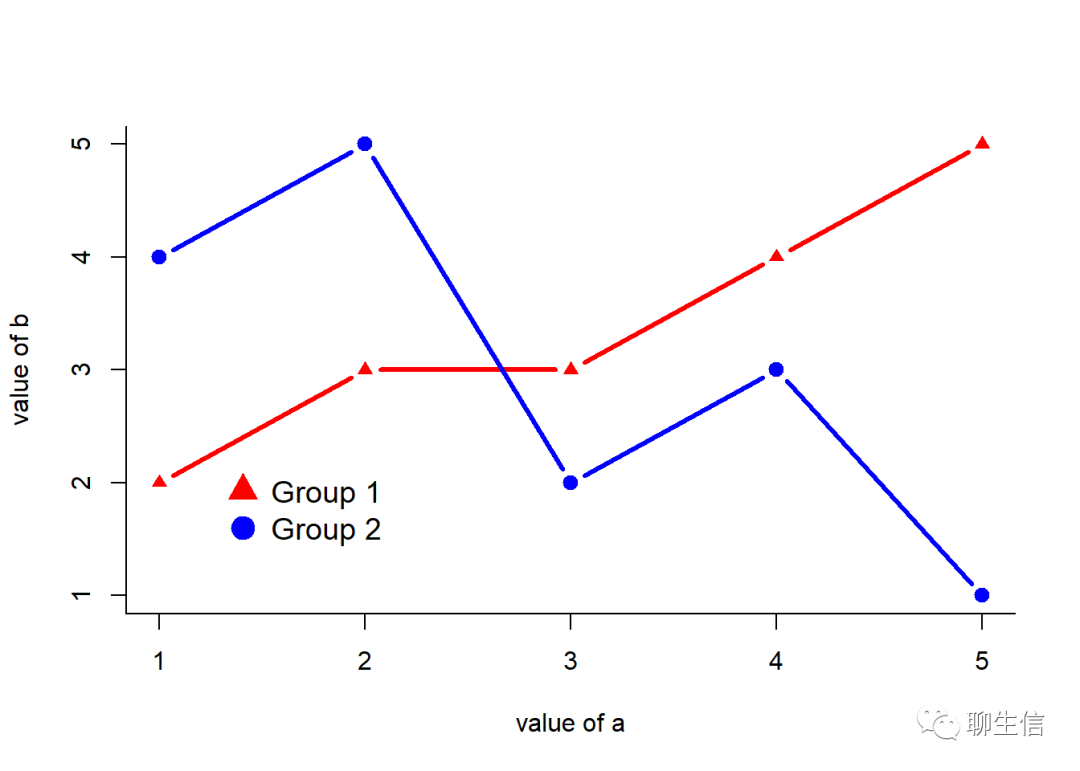
a=c(1:5);b=c(2,3,3,4,5);cc=c(4,5,2,3,1)#自定义生成三个变量
plot(b~a,type="b",bty="l",xlab="value of a",ylab = "value of b",col='red',lwd=3,pch=17,ylim=c(1,5))
#绘制关于a和b的线图
lines(cc~a,col='blue',lwd=3,pch=19,type="b")
#此处用lines()函数添加第二条函数线
legend("bottomleft",legend = c("Group 1","Group 2"),
col = c('red','blue'),
pch = c(17,19),
bty = "n",pt.cex = 2,cex = 1.2,text.col = "black",horiz = F,inset = c(0.1,0.1))
#bottomleft:为位置参数,接受一个字符串,比如'topright',表示右上方,也接受一个坐标,比如(3,5)
#legend = c("Group 1","Group 2"):在图例中添加内容,相当于设置图例中各组标签.
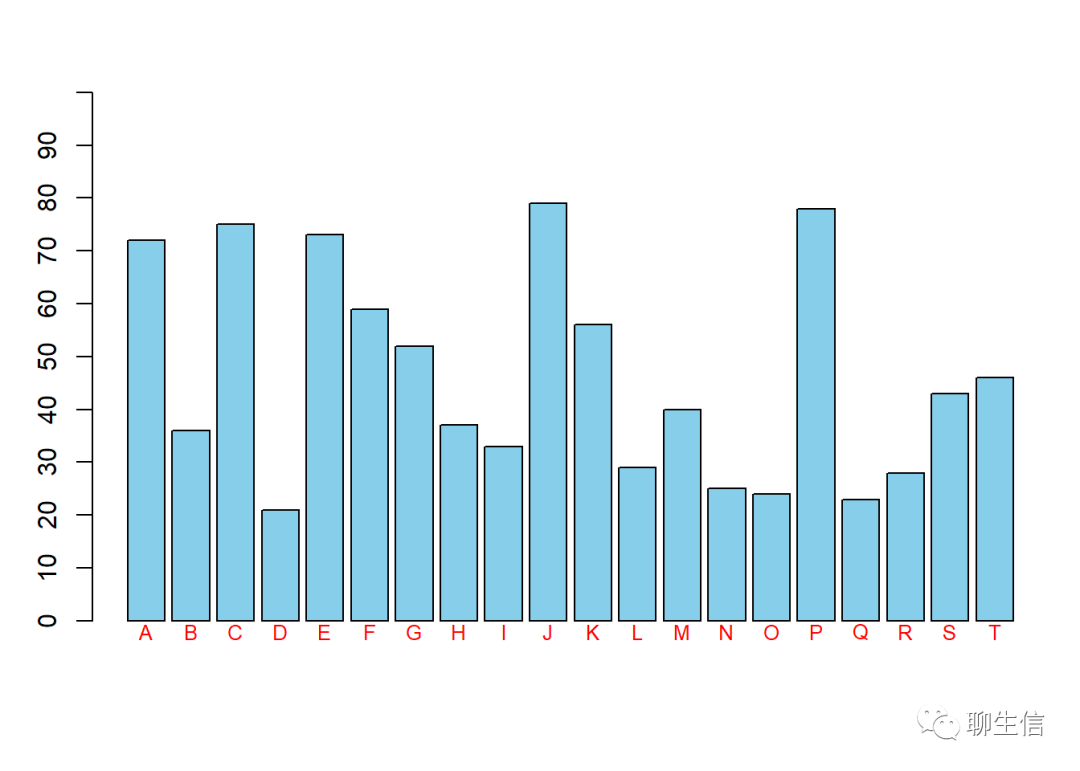
#pt.cex:定义图例中标签文字的大小data <- sample(20:80,20)
par(mar =c(4,3,3,1))
barcenter <- barplot(data,col = 'skyblue',axes = F,ylim =c(-5,100))
axis(2,at=seq(0,100,10))
#在图中添加文本:text(barcenter,-2,labels = LETTERS[1:20],col = 'red',cex = 0.8)
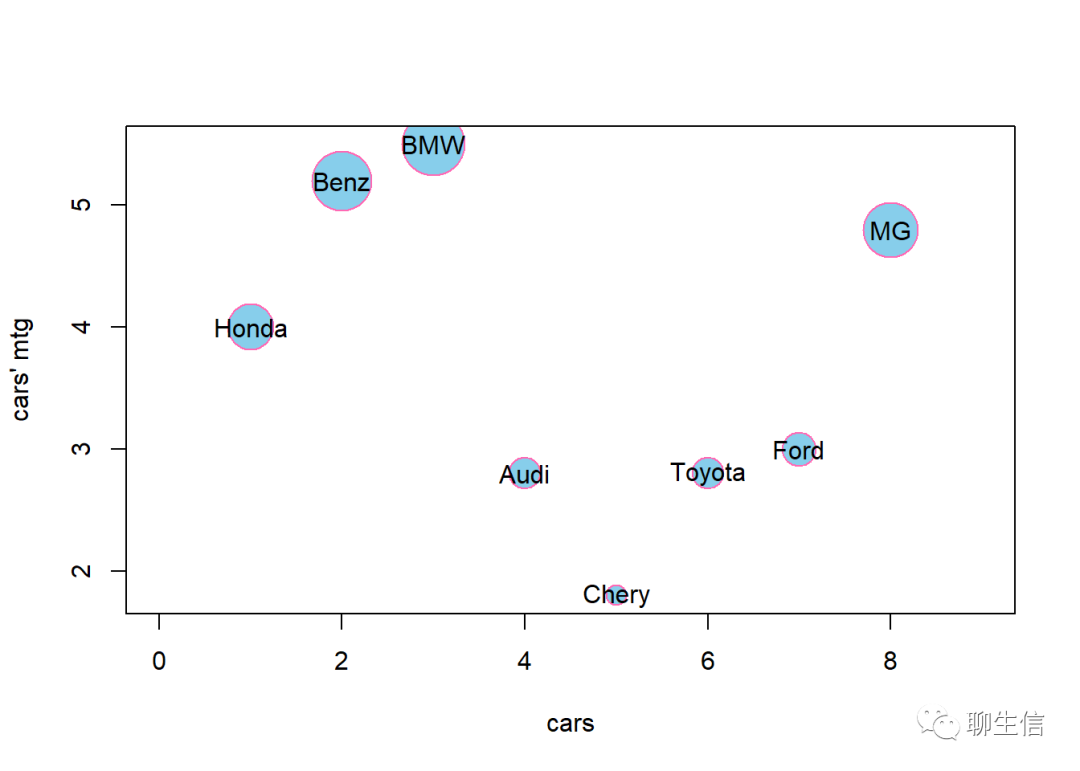
mycars <- data.frame(car = c('Honda','Benz','BMW','Audi','Chery','Toyota','Ford','MG'),
mtg = c(4.0,5.2,5.5,2.8,1.8,2.8,3.0,4.8))
#建造一个数据集
plot(mycars$mtg,cex=mycars$mtg,col='hotpink',pch=21,bg='skyblue',ylab = 'cars\' mtg',
xlab = 'cars',xlim = c(0,9))
#此处,cex参数被设置成车辆mtg的大小,由于mtg变量取值大小不一,因此也就生成了一个气泡图.
#在图中添加文本:
text(1:8,mycars$mtg,labels = mycars$car)# 在图中添加每辆车的名字。注意text()函数中的向量操作。
# 横坐标是1~7,纵坐标是每辆汽车mtg的取值。
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|




























后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集