 极市平台
极市平台





极市导读
本文提出了Involution卷积,可构建用于构建新型的神经网络架构!本文所提方法在分类、检测和分割等CV垂直任务上涨点明显,代码刚刚开源! >>加入极市CV技术交流群,走在计算机视觉的最前沿

作者单位:港科大, 字节跳动AI Lab, 北大, 北邮
1 简介
卷积一直是构建现代神经网络架构的核心组件,同时由于卷积的应用也引发了视觉深度学习的浪潮。而作者在这项工作中重新思考了视觉任务中标准卷积的内在原理,特别是与空间无关和特定于通道的方法。取而代之的是,本文通过反转前述的卷积设计原理(称为卷积)提出了一种用于深度神经网络的新颖原子操作。此外,本文还揭开了最近流行的Self-Attention运算的神秘面纱,并将其作为复杂化的实例插入到本文所提的involution卷积之中。大家可以将提出的involution算子作为基础以构建新一代神经网络,并在几种流行的Baseline(包括ImageNet分类,COCO检测和分割以及Cityscapes分割)上为不同的深度学习模型提供支持。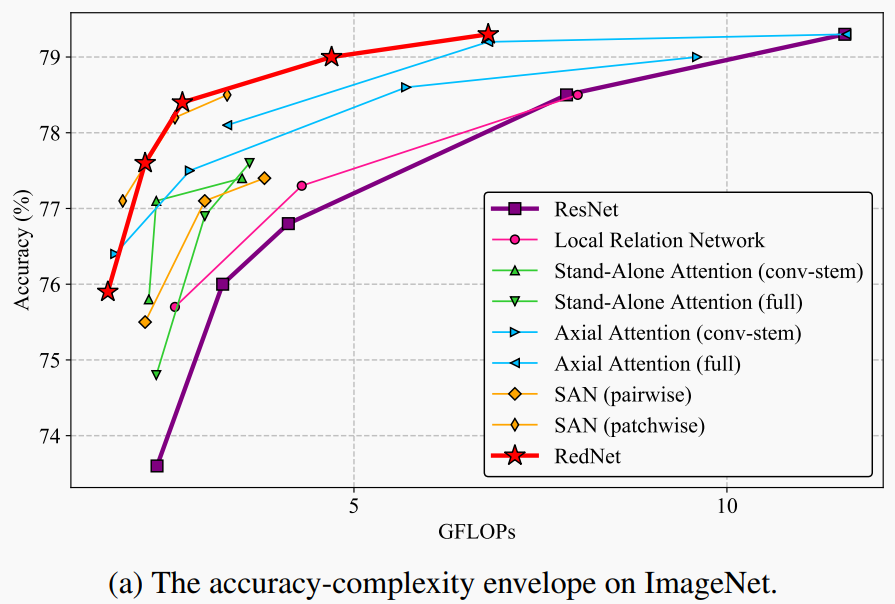
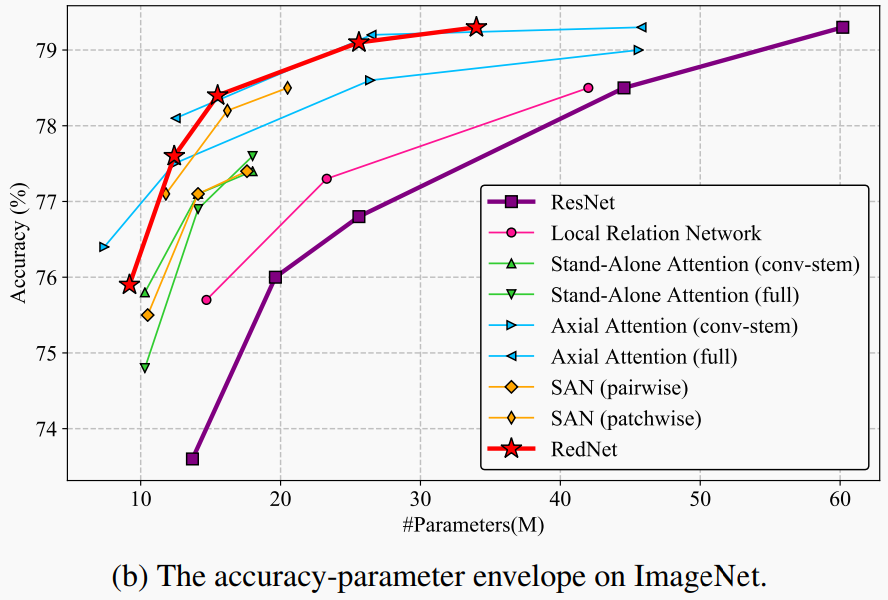
本文作者基于involution卷积构建了全新的ResNet-50架构RedNet,并改善了Baseline的性能,分别提高了1.6%的Top-1分类精度、2.5%和2.4%的边界框AP值,以及4.7%的mIoU,同时将计算成本压缩为原来的66%、65%、72%和57%。
本文主要贡献
作者重新思考卷积与空间和通道范围有关的内在原理。这一思考促使作者提出使用其他具有辨别能力和表达能力的潜在算子作为视觉识别的替代,突破了卷积现有的归纳偏见; 将把Self-Attention融入视觉表征的学习过程。在此背景下,关系建模中对像素对的组合要求受到了挑战。此外,统一了Self-Attention和卷积; 基于involution构建的模型进行了广泛的实验。
2 思考来源
尽管神经网络体系结构发展迅速,但卷积仍然是深度神经网络架构构建的主要组件。从经典的图像滤波方法中得到的灵感,卷积核具有2个显著的特性Spatial-agnostic和Channel-specific。在Spatial上,前者的性质保证了卷积核在不同位置之间的共享,实现了平移不变性。在Channel域中,卷积核的频谱负责收集编码在不同Channel中的不同信息,满足后一种特性。此外,自从VGGNet出现以来,现代神经网络通过限制卷积核的空间跨度不超过来满足卷积核的紧凑性。
一方面,尽管Spatial-Agnostic和Spatial-Compact的性质在提高效率和解释平移不变性等价方面有意义,但它剥夺了卷积核适应不同空间位置的不同视觉模式的能力。此外,局部性限制了卷积的感受野,对小目标或者模糊图像构成了挑战。
另一方面,众所周知,卷积核内部的通道间冗余在许多经典深度神经网络中都很突出,这使得卷积核对于不同通道的灵活性受到限制。
为了克服上述限制,本文作者提出了被称为的操作,与标准卷积相比,具有对称反向特性,即Spatial-Specific和Channel-Agnostic。
具体地说,核在空间范围上是不同的,但在通道上是共享的。由于核的空间特性,如果将其参数化为卷积核等固定大小的矩阵,并使用反向传播算法进行更新,则会阻碍学习到的对合核在不同分辨率的输入图像之间的传输。在处理可变特征分辨率的最后,属于特定空间位置的核可能仅在对应位置本身的传入特征向量的条件下作为实例生成。此外,作者还通过在通道维数上共享核来减少核的冗余。
综合上述2个因素,运算的计算复杂度随特征通道数量线性增加,动态参数化核在空间维度上具有广泛的覆盖。通过逆向设计方案,本文提出的具有卷积的双重优势:
可以在更广阔的空间中聚合上下文,从而克服了对远程交互进行建模的困难; 可以在不同位置上自适应地分配权重,从而对空间域中信息最丰富的视觉元素进行优先排序。
大家也都知道最近基于Self-Attention进一步的研究表明,很多任务为了捕获特征的长期依赖关系提出使用Transformer来进行建模。在这些研究中,纯粹的Self-Attention可以被用来构建具有良好性能的独立模型。
而本文将揭示Self-Attention是通过一个复杂的关于核结构的公式来对邻近像素之间的关系进行建模,其实也就是化的特殊情况。相比之下,本文所采用的核是根据单个像素生成的,而不是它与相邻像素的关系。
更进一步,作者在实验中证明,即使使用简单版本,也可以实现Self-Attention的精确。
3 简述CNN
这里设为输入特征,其中, 分别为其高度,宽度和输入通道。在特征张量内,位于图像单元中的每个特征向量都可以被认为是代表某些高级语义的像素。一个固定核大小为的Co卷积滤波器记为,其中每个滤波器包含卷积核,并以滑动窗口的方式对输入特征映射进行乘加运算,得到输出特征映射,定义为:
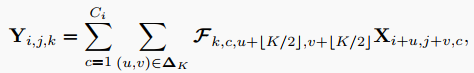
其中,为考虑对中心像素进行卷积的邻域偏移量集合,记为(这里的表示笛卡尔积):
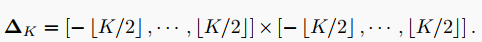
此外,Depth-wise Convolution将Group Convolution推到极端,其中每个卷积核严格地对以为索引的单个特征通道进行卷积,因此在假设输出通道数等于输入通道数的情况下,从中消除第一个维来形成。这样,卷积运算就变成了:
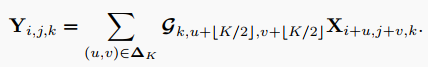
注意,卷积核是特定于Channel中的第个特征slice ,并在该slice中的所有空间位置之间共享。
4. Involution设计
4.1 Involution原理简述
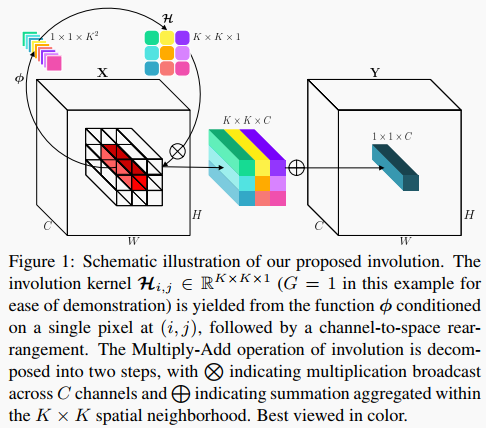
与上面描述的标准卷积或Depth-wise卷积相比,Involution核被设计成包含Spatial和Channel的反向特征变换。
具体来说,Involution核是专门为位于对应坐标的像素定制的,但在通道上共享,计算每个组共享相同Involution核的组数。利用Involution核对输入进行乘加运算,得到Involution的输出特征映射,定义为:
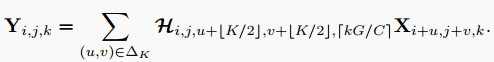
与卷积核不同,Involution核的形状取决于输入特征映射的形状。想法是生成以原始输入张量为条件的Involution核,使输出核与输入核对齐。这里将核生成函数符号为,并将每个位置的函数映射抽象为:
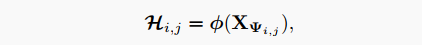
其中的像素群是受限制的。
复现细节: 考虑到卷积的简洁性,使Involution在概念上尽可能简单。目标是首先为内核生成函数提供一个设计空间,然后快速原型一些有效的设计实例以供实际使用。在这项工作中,作者选择从单个像素跨越每个Involution内核。形式上每个像素有核生成函数,其形式如下:
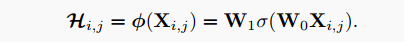
其中和代表2个线性变换,共同构成bottleneck结构,中间通道维数由降阶比控制,以便有效处理,表示批处理归一化后的对于2个线性变换的非线性激活函数。
简单说一下步骤:
第一步
Involution核(在这个例子中为了便于演示,设G=1)是由在处以单个像素为条件的函数产生的,随后是Channel到Spatial的重排;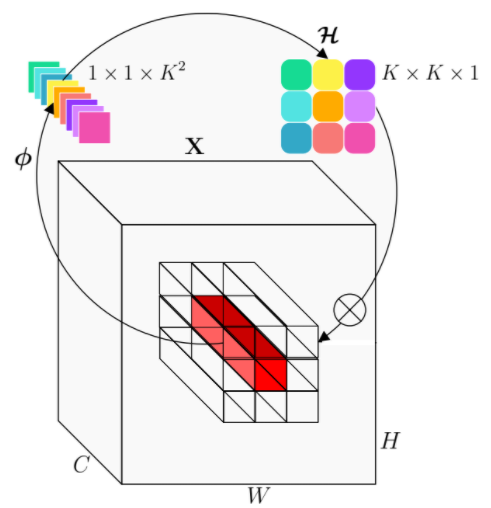
第二步
将Involution的乘加运算分解为2个步骤,表示跨C个信道传播的乘法运算,表示在空间邻域内聚合的求和运算。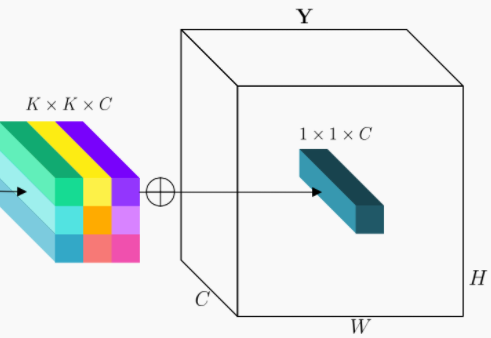
其具体操作的PyTorch风格的伪代码如下:

4.2 Self-Attention一般化表达
严格来说本文提出的Involution本质上可以成为Self-Attention的一般化表达。通过计算Query与Value的对应关系Q和K得到的关联度,得到Self-Attention pool Value,公式为: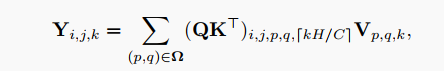
其中、、是对输入的线性变换,为多Heads Self-Attention中Head的个数。相似之处在于,这2种操作符都通过加权和来收集邻域或较小范围内的像素。一方面,Involution的计算机制可以看作是空间域上的一种集中。另一方面,Attention Map,或者说Self-Attention中的affinity矩阵,可以看作是一种Involution核。
5 Rednet网络搭建
作者在ResNet的主干和主干的所有瓶颈位置上使用Involution替换掉了卷积,但保留了所有的卷积用于通道映射和融合。这些精心重新设计的实体联合起来,形成了一种新的高效Backbone网络,称为RedNet。pytorch实现如下:
from torch.autograd import Functionimport torchfrom torch.nn.modules.utils import _pairimport torch.nn.functional as Fimport torch.nn as nnfrom mmcv.cnn import ConvModulefrom collections import namedtupleimport cupyfrom string import TemplateStream = namedtuple('Stream', ['ptr'])def Dtype(t):if isinstance(t, torch.cuda.FloatTensor):return 'float'elif isinstance(t, torch.cuda.DoubleTensor):return 'double'=True)def load_kernel(kernel_name, code, **kwargs):code = Template(code).substitute(**kwargs)kernel_code = cupy.cuda.compile_with_cache(code)return kernel_code.get_function(kernel_name)CUDA_NUM_THREADS = 1024kernel_loop = '''#define CUDA_KERNEL_LOOP(i, n) \for (int i = blockIdx.x * blockDim.x + threadIdx.x; \i < (n); \i += blockDim.x * gridDim.x)'''def GET_BLOCKS(N):return (N + CUDA_NUM_THREADS - 1) // CUDA_NUM_THREADS_involution_kernel = kernel_loop + '''extern "C"__global__ void involution_forward_kernel(const ${Dtype}* bottom_data, const ${Dtype}* weight_data, ${Dtype}* top_data) {${nthreads}) {const int n = index / ${channels} / ${top_height} / ${top_width};const int c = (index / ${top_height} / ${top_width}) % ${channels};const int h = (index / ${top_width}) % ${top_height};const int w = index % ${top_width};const int g = c / (${channels} / ${groups});value = 0;#pragma unrollfor (int kh = 0; kh < ${kernel_h}; ++kh) {#pragma unrollfor (int kw = 0; kw < ${kernel_w}; ++kw) {const int h_in = -${pad_h} + h * ${stride_h} + kh * ${dilation_h};const int w_in = -${pad_w} + w * ${stride_w} + kw * ${dilation_w};if ((h_in >= 0) && (h_in < ${bottom_height})(w_in >= 0) && (w_in < ${bottom_width})) {const int offset = ((n * ${channels} + c) * ${bottom_height} + h_in)${bottom_width} + w_in;const int offset_weight = ((((n * ${groups} + g) * ${kernel_h} + kh) * ${kernel_w} + kw) * ${top_height} + h)${top_width} + w;value += weight_data[offset_weight] * bottom_data[offset];}}}= value;}}'''_involution_kernel_backward_grad_input = kernel_loop + '''extern "C"__global__ void involution_backward_grad_input_kernel(const ${Dtype}* const top_diff, const ${Dtype}* const weight_data, ${Dtype}* const bottom_diff) {${nthreads}) {const int n = index / ${channels} / ${bottom_height} / ${bottom_width};const int c = (index / ${bottom_height} / ${bottom_width}) % ${channels};const int h = (index / ${bottom_width}) % ${bottom_height};const int w = index % ${bottom_width};const int g = c / (${channels} / ${groups});value = 0;for (int kh = 0; kh < ${kernel_h}; ++kh) {for (int kw = 0; kw < ${kernel_w}; ++kw) {const int h_out_s = h + ${pad_h} - kh * ${dilation_h};const int w_out_s = w + ${pad_w} - kw * ${dilation_w};if (((h_out_s % ${stride_h}) == 0) && ((w_out_s % ${stride_w}) == 0)) {const int h_out = h_out_s / ${stride_h};const int w_out = w_out_s / ${stride_w};if ((h_out >= 0) && (h_out < ${top_height})(w_out >= 0) && (w_out < ${top_width})) {const int offset = ((n * ${channels} + c) * ${top_height} + h_out)${top_width} + w_out;const int offset_weight = ((((n * ${groups} + g) * ${kernel_h} + kh) * ${kernel_w} + kw) * ${top_height} + h_out)${top_width} + w_out;value += weight_data[offset_weight] * top_diff[offset];}}}}= value;}}'''_involution_kernel_backward_grad_weight = kernel_loop + '''extern "C"__global__ void involution_backward_grad_weight_kernel(const ${Dtype}* const top_diff, const ${Dtype}* const bottom_data, ${Dtype}* const buffer_data) {${nthreads}) {const int h = (index / ${top_width}) % ${top_height};const int w = index % ${top_width};const int kh = (index / ${kernel_w} / ${top_height} / ${top_width})${kernel_h};const int kw = (index / ${top_height} / ${top_width}) % ${kernel_w};const int h_in = -${pad_h} + h * ${stride_h} + kh * ${dilation_h};const int w_in = -${pad_w} + w * ${stride_w} + kw * ${dilation_w};if ((h_in >= 0) && (h_in < ${bottom_height})(w_in >= 0) && (w_in < ${bottom_width})) {const int g = (index / ${kernel_h} / ${kernel_w} / ${top_height} / ${top_width}) % ${groups};const int n = (index / ${groups} / ${kernel_h} / ${kernel_w} / ${top_height} / ${top_width}) % ${num};value = 0;for (int c = g * (${channels} / ${groups}); c < (g + 1) * (${channels} / ${groups}); ++c) {const int top_offset = ((n * ${channels} + c) * ${top_height} + h)${top_width} + w;const int bottom_offset = ((n * ${channels} + c) * ${bottom_height} + h_in)${bottom_width} + w_in;value += top_diff[top_offset] * bottom_data[bottom_offset];}= value;else {= 0;}}}'''class _involution(Function):@staticmethoddef forward(ctx, input, weight, stride, padding, dilation):assert input.dim() == 4 and input.is_cudaassert weight.dim() == 6 and weight.is_cudachannels, height, width = input.size()kernel_w = weight.size()[2:4]output_h = int((height + 2 * padding[0] - (dilation[0] * (kernel_h - 1) + 1)) / stride[0] + 1)output_w = int((width + 2 * padding[1] - (dilation[1] * (kernel_w - 1) + 1)) / stride[1] + 1)output = input.new(batch_size, channels, output_h, output_w)n = output.numel()with torch.cuda.device_of(input):f = load_kernel('involution_forward_kernel', _involution_kernel, Dtype=Dtype(input), nthreads=n,num=batch_size, channels=channels, groups=weight.size()[1],bottom_height=height, bottom_width=width,top_height=output_h, top_width=output_w,kernel_h=kernel_h, kernel_w=kernel_w,stride_h=stride[0], stride_w=stride[1],dilation_h=dilation[0], dilation_w=dilation[1],pad_h=padding[0], pad_w=padding[1])=(CUDA_NUM_THREADS,1,1),grid=(GET_BLOCKS(n),1,1),args=[input.data_ptr(), weight.data_ptr(), output.data_ptr()],stream=Stream(ptr=torch.cuda.current_stream().cuda_stream))weight)ctx.padding, ctx.dilation = stride, padding, dilationreturn output@staticmethoddef backward(ctx, grad_output):assert grad_output.is_cuda and grad_output.is_contiguous()weight = ctx.saved_tensorspadding, dilation = ctx.stride, ctx.padding, ctx.dilationchannels, height, width = input.size()kernel_w = weight.size()[2:4]output_w = grad_output.size()[2:]grad_weight = None, Noneopt = dict(Dtype=Dtype(grad_output),num=batch_size, channels=channels, groups=weight.size()[1],bottom_height=height, bottom_width=width,top_height=output_h, top_width=output_w,kernel_h=kernel_h, kernel_w=kernel_w,stride_h=stride[0], stride_w=stride[1],dilation_h=dilation[0], dilation_w=dilation[1],pad_h=padding[0], pad_w=padding[1])with torch.cuda.device_of(input):if ctx.needs_input_grad[0]:grad_input = input.new(input.size())n = grad_input.numel()= nf = load_kernel('involution_backward_grad_input_kernel',**opt)=(CUDA_NUM_THREADS,1,1),grid=(GET_BLOCKS(n),1,1),args=[grad_output.data_ptr(), weight.data_ptr(), grad_input.data_ptr()],stream=Stream(ptr=torch.cuda.current_stream().cuda_stream))if ctx.needs_input_grad[1]:grad_weight = weight.new(weight.size())n = grad_weight.numel()= nf = load_kernel('involution_backward_grad_weight_kernel',**opt)=(CUDA_NUM_THREADS,1,1),grid=(GET_BLOCKS(n),1,1),args=[grad_output.data_ptr(), input.data_ptr(), grad_weight.data_ptr()],stream=Stream(ptr=torch.cuda.current_stream().cuda_stream))return grad_input, grad_weight, None, None, Nonedef _involution_cuda(input, weight, bias=None, stride=1, padding=0, dilation=1):involution kernel"""assert input.size(0) == weight.size(0)assert input.size(-2)//stride == weight.size(-2)assert input.size(-1)//stride == weight.size(-1)if input.is_cuda:out = _involution.apply(input, weight, _pair(stride), _pair(padding), _pair(dilation))if bias is not None:out += bias.view(1,-1,1,1)else:raise NotImplementedErrorreturn outclass involution(nn.Module):def __init__(self,channels,kernel_size,:self).__init__()= kernel_size= stride= channelsreduction_ratio = 4= 16= self.channels // self.group_channels= ConvModule(in_channels=channels,out_channels=channels // reduction_ratio,kernel_size=1,conv_cfg=None,norm_cfg=dict(type='BN'),act_cfg=dict(type='ReLU'))= ConvModule(in_channels=channels // reduction_ratio,out_channels=kernel_size**2 * self.groups,kernel_size=1,stride=1,conv_cfg=None,norm_cfg=None,act_cfg=None)if stride > 1:= nn.AvgPool2d(stride, stride)def forward(self, x):weight = self.conv2(self.conv1(x if self.stride == 1 else self.avgpool(x)))c, h, w = weight.shapeweight = weight.view(b, self.groups, self.kernel_size, self.kernel_size, h, w)out = _involution_cuda(x, weight, stride=self.stride, padding=(self.kernel_size-1)//2)return out
6 实验
6.1 图像分类实验
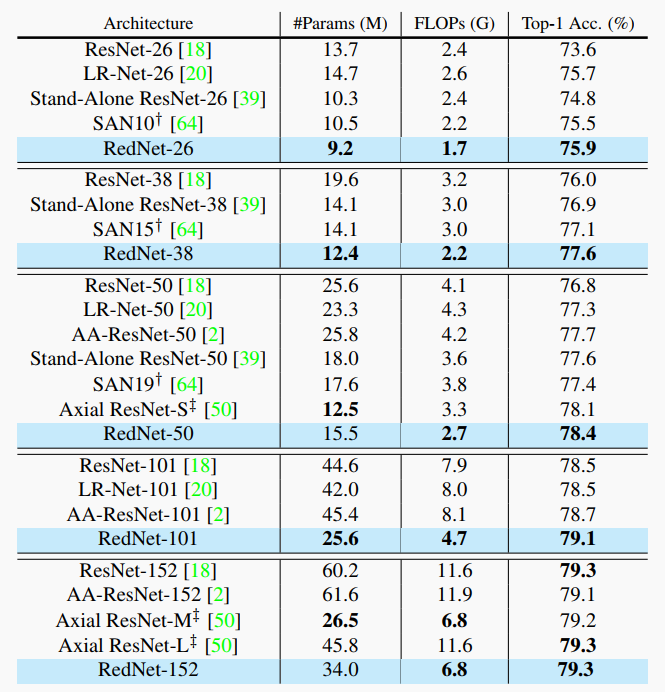 通过上表可以看出,RedNet与现有的SOTA模型对比,毫无疑问参数好精度高是最大的特点了。
通过上表可以看出,RedNet与现有的SOTA模型对比,毫无疑问参数好精度高是最大的特点了。
6.2 目标检测实验
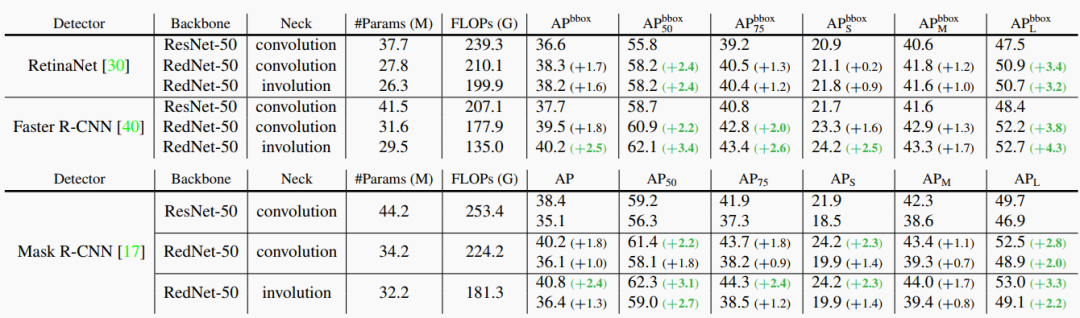 通过上表可以看出,RedNet作为Backbone的检测框架,不管是RetinaNet、Faster R-CNN还是Mask R-CNN都可以在参数量下降的情况下,依然有明显的AP的提升。
通过上表可以看出,RedNet作为Backbone的检测框架,不管是RetinaNet、Faster R-CNN还是Mask R-CNN都可以在参数量下降的情况下,依然有明显的AP的提升。
6.3 语义分割实验
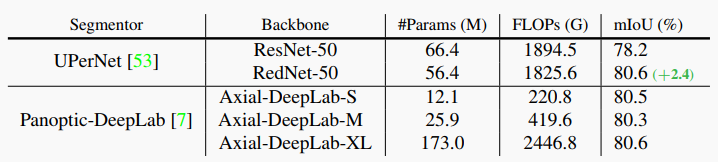 通过上表可以看出,RedNet在参数量下降的情况下,依然有2.4的mIoU的提升。
通过上表可以看出,RedNet在参数量下降的情况下,依然有2.4的mIoU的提升。
参考:
[1].Involution:Inverting the Inherence of Convolution for Visual Recognition
[2].https://github.com/d-li14/involution
推荐阅读
2021-03-11

2021-03-11

2021-03-10


# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



