
CPU 比 GPU 训练神经网络快十几倍,英特尔:别用矩阵运算了
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
在深度学习与神经网络领域,研究人员通常离不开 GPU。得益于 GPU 极高内存带宽和较多核心数,研究人员可以更快地获得模型训练的结果。与此同时,CPU 受限于自身较少的核心数,计算运行需要较长的时间,因而不适用于深度学习模型以及神经网络的训练。



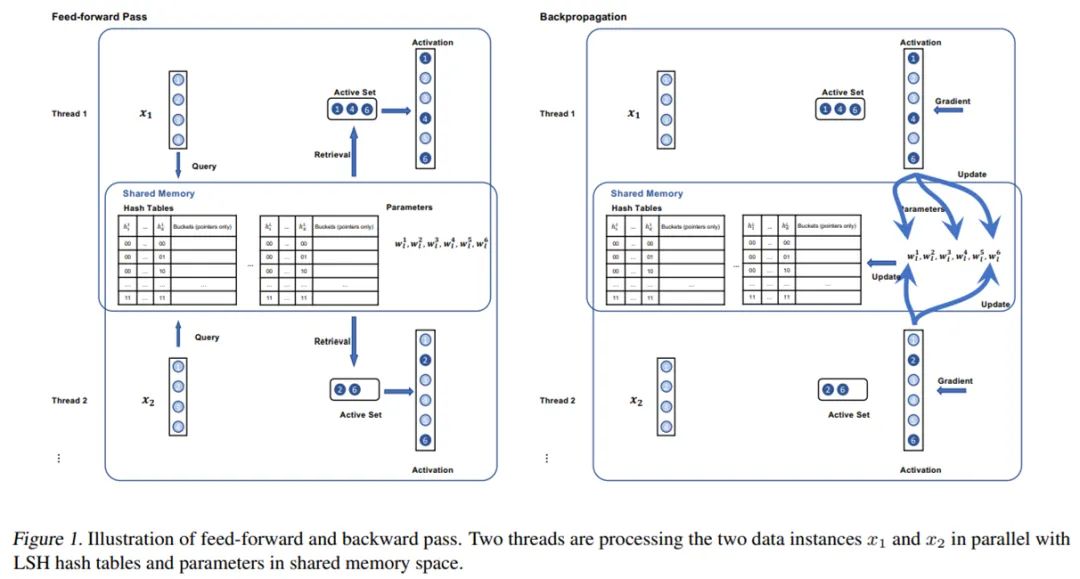
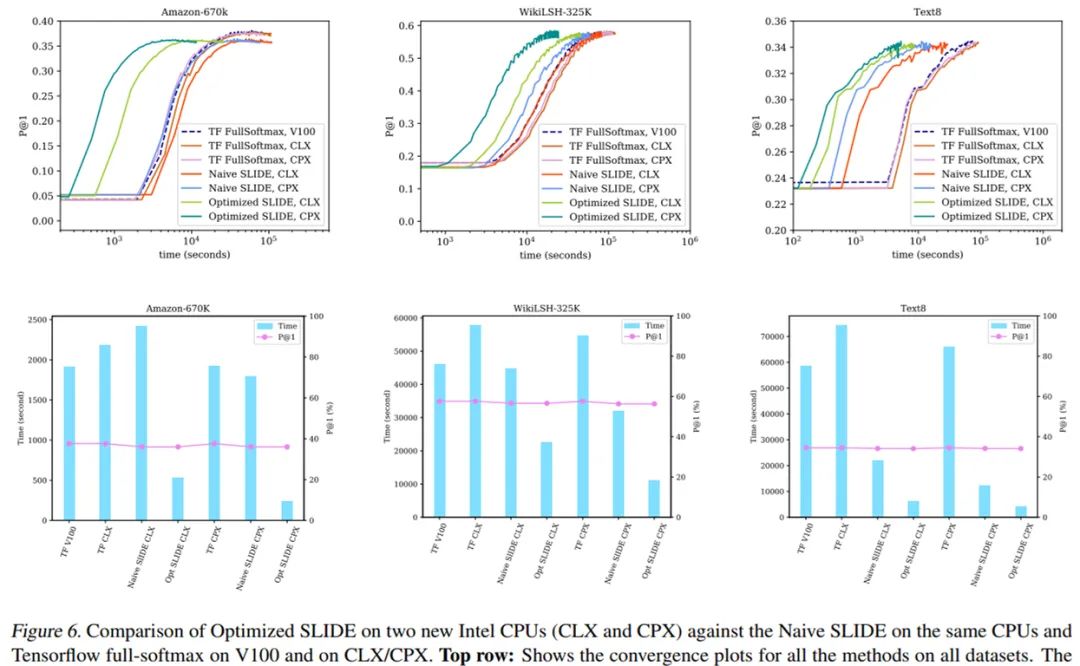
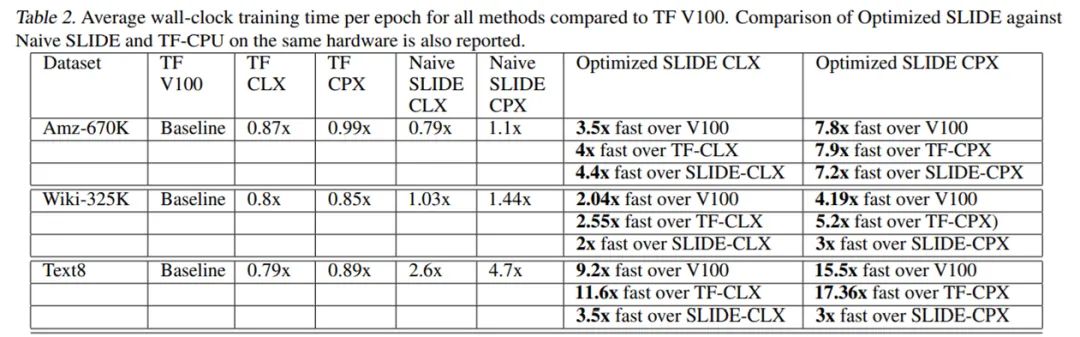
1)V100 GPU 上的 full-softmax tensorflow 实现; 2) CPX 上的 full-softmax tensorflow 实现; 3)CLX 上的 full-softmax tensorflow 实现; 4)CPX 上的 Naive SLIDE; 5)CLX 上的 Naive SLIDE。



点个在看 paper不断!
评论