 程序员的成长之路
程序员的成长之路





阅读本文大概需要 4 分钟。
来自:https://www.jianshu.com/p/523635f5f133
本文翻译自全球访问量排名第8位的论坛Reddit博客上的文章,讲的是关于Reddit如何在海量浏览量下实时统计浏览量的。

统计方法
计数必须达到实时或者接近实时。
每个用户在一个时间窗口内仅被记录一次。
帖子显示的统计数量的误差不能超过百分之几。
整个系统必须能在生成环境下,数秒内完成阅读计数的处理。
线性概率计算方法,它非常精确,但是需要的内存数量是根据用户数线性增长的。
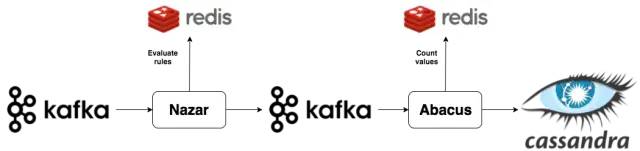
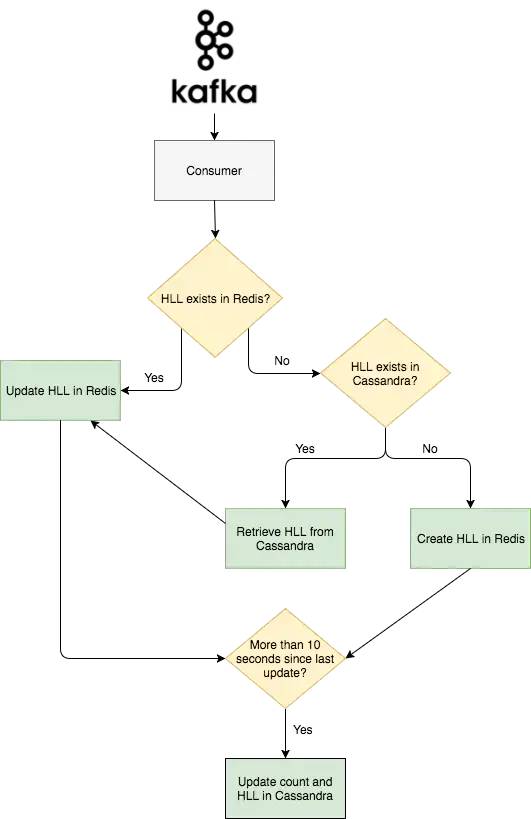
基于HyperLogLog (HLL)的计算方法,HLL的内存增长是非线性的,但是统计的精准度和线性概率就不是同一级别的了。
Twitter的Algebird库,Scala实现,Algebird的文档撰写非常好,但是关于它是如何实现HLL的,不是很容易理解。
stream-lib库中的HyperLogLog++实现,Java编写。stream-lib代码的文档化做的很好,但我们对如何适当调优它,还是有些困惑的。
Redis的HLL实现(我们最终的选择),我们觉得Redis的实现不管从文档完善程度还是配置和提供的API接口,来说做的都非常好。另外的加分点是,使用Redis可以减少我们对CPU和内存性能的担忧。
推荐阅读:
【89期】面试官 5 连问一个 TCP 连接可以发多少个 HTTP 请求?
【88期】面试官问:你能说说 Spring 中,接口的bean是如何注入的吗?
【87期】面试官问:Java序列化和反序列化为什么要实现Serializable接口

微信扫描二维码,关注我的公众号
朕已阅 

