 3D视觉工坊
3D视觉工坊




点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

论文标题:PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation


标签:有监督 | 特征学习、点云分类、语义分割
 的张量,num_channels一般为3,表示点云的三维坐标。
的张量,num_channels一般为3,表示点云的三维坐标。

1 motivation
2 contribution
3 solution
无序性 --> 对称函数设计用于表征 点不是孤立的,需要考虑局部结构 --> 局部全局特征结合 仿射变换无关性 --> alignment network

直接将点云中的点以某种顺序输入(比如按照坐标轴从小到大这样)

 是我们的目标,右边
是我们的目标,右边  是我们期望设计的对称函数。由上公式可以看出,基本思路就是对各个元素(即点云中的各个点)使用
是我们期望设计的对称函数。由上公式可以看出,基本思路就是对各个元素(即点云中的各个点)使用  分别处理,在送入对称函数 中处理,以实现排列不变性。 就是MLP, 就是max pooling
分别处理,在送入对称函数 中处理,以实现排列不变性。 就是MLP, 就是max pooling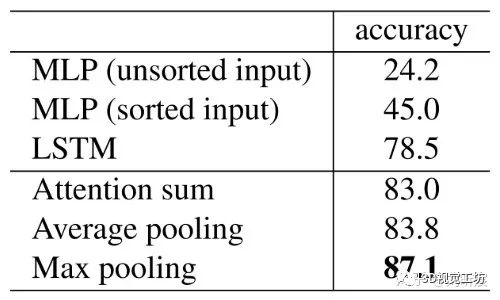
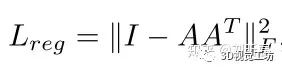

4 dataset and experiments
分割:mIoU
分割:ShapeNet Part dataset和Stanford 3D semantic parsing dataset
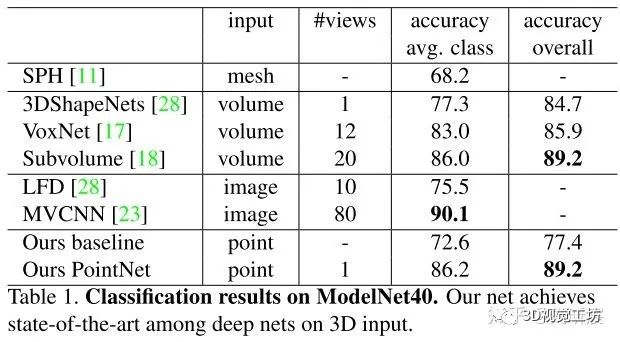
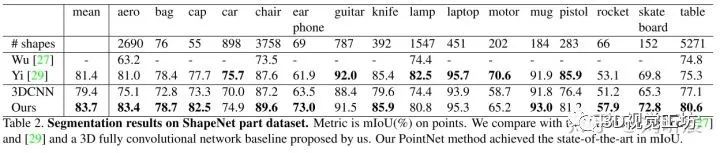
5 code
1. 如何对点云使用MLP?
2. alignment network怎么做的?
3. 对称函数如何实现来提取global feature的?
4. loss?
def get_model(point_cloud, is_training, bn_decay=None):
""" Classification PointNet, input is BxNx3, output Bx40 """
batch_size = point_cloud.get_shape()[0].value
num_point = point_cloud.get_shape()[1].value
end_points = {}
with tf.variable_scope('transform_net1') as sc:
transform = input_transform_net(point_cloud, is_training, bn_decay, K=3)
point_cloud_transformed = tf.matmul(point_cloud, transform)
input_image = tf.expand_dims(point_cloud_transformed, -1)
net = tf_util.conv2d(input_image, 64, [1,3],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv1', bn_decay=bn_decay)
net = tf_util.conv2d(net, 64, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv2', bn_decay=bn_decay)
with tf.variable_scope('transform_net2') as sc:
transform = feature_transform_net(net, is_training, bn_decay, K=64)
end_points['transform'] = transform
net_transformed = tf.matmul(tf.squeeze(net, axis=[2]), transform)
net_transformed = tf.expand_dims(net_transformed, [2])
net = tf_util.conv2d(net_transformed, 64, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv3', bn_decay=bn_decay)
net = tf_util.conv2d(net, 128, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv4', bn_decay=bn_decay)
net = tf_util.conv2d(net, 1024, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv5', bn_decay=bn_decay)
# Symmetric function: max pooling
net = tf_util.max_pool2d(net, [num_point,1],
padding='VALID', scope='maxpool')
net = tf.reshape(net, [batch_size, -1])
net = tf_util.fully_connected(net, 512, bn=True, is_training=is_training,
scope='fc1', bn_decay=bn_decay)
net = tf_util.dropout(net, keep_prob=0.7, is_training=is_training,
scope='dp1')
net = tf_util.fully_connected(net, 256, bn=True, is_training=is_training,
scope='fc2', bn_decay=bn_decay)
net = tf_util.dropout(net, keep_prob=0.7, is_training=is_training,
scope='dp2')
net = tf_util.fully_connected(net, 40, activation_fn=None, scope='fc3')
return net, end_points
input_image = tf.expand_dims(point_cloud_transformed, -1)
net = tf_util.conv2d(input_image, 64, [1,3],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv1', bn_decay=bn_decay)
net = tf_util.conv2d(net, 64, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv2', bn_decay=bn_decay)
 ,因此将点云看成是W和H分为N和3的2D图像,维度是
,因此将点云看成是W和H分为N和3的2D图像,维度是 
 ,正好对应的就是“2D图像”的一行,也就是一个点(三维坐标),输出通道数是64,因此输出张量维度应该是
,正好对应的就是“2D图像”的一行,也就是一个点(三维坐标),输出通道数是64,因此输出张量维度应该是 
 ,
,  卷积只改变通道数,输出张量维度是
卷积只改变通道数,输出张量维度是 def conv2d(inputs,
num_output_channels,
kernel_size,
scope,
stride=[1, 1],
padding='SAME',
use_xavier=True,
stddev=1e-3,
weight_decay=0.0,
activation_fn=tf.nn.relu,
bn=False,
bn_decay=None,
is_training=None):
""" 2D convolution with non-linear operation.
Args:
inputs: 4-D tensor variable BxHxWxC
num_output_channels: int
kernel_size: a list of 2 ints
scope: string
stride: a list of 2 ints
padding: 'SAME' or 'VALID'
use_xavier: bool, use xavier_initializer if true
stddev: float, stddev for truncated_normal init
weight_decay: float
activation_fn: function
bn: bool, whether to use batch norm
bn_decay: float or float tensor variable in [0,1]
is_training: bool Tensor variable
Returns:
Variable tensor
"""
with tf.variable_scope(scope) as sc:
kernel_h, kernel_w = kernel_size
num_in_channels = inputs.get_shape()[-1].value
kernel_shape = [kernel_h, kernel_w,
num_in_channels, num_output_channels]
kernel = _variable_with_weight_decay('weights',
shape=kernel_shape,
use_xavier=use_xavier,
stddev=stddev,
wd=weight_decay)
stride_h, stride_w = stride
outputs = tf.nn.conv2d(inputs, kernel,
[1, stride_h, stride_w, 1],
padding=padding)
biases = _variable_on_cpu('biases', [num_output_channels],
tf.constant_initializer(0.0))
outputs = tf.nn.bias_add(outputs, biases)
if bn:
outputs = batch_norm_for_conv2d(outputs, is_training,
bn_decay=bn_decay, scope='bn')
if activation_fn is not None:
outputs = activation_fn(outputs)
return outputs
def input_transform_net(point_cloud, is_training, bn_decay=None, K=3):
""" Input (XYZ) Transform Net, input is BxNx3 gray image
Return:
Transformation matrix of size 3xK """
batch_size = point_cloud.get_shape()[0].value
num_point = point_cloud.get_shape()[1].value
input_image = tf.expand_dims(point_cloud, -1)
net = tf_util.conv2d(input_image, 64, [1,3],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv1', bn_decay=bn_decay)
net = tf_util.conv2d(net, 128, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv2', bn_decay=bn_decay)
net = tf_util.conv2d(net, 1024, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='tconv3', bn_decay=bn_decay)
net = tf_util.max_pool2d(net, [num_point,1],
padding='VALID', scope='tmaxpool')
net = tf.reshape(net, [batch_size, -1])
net = tf_util.fully_connected(net, 512, bn=True, is_training=is_training,
scope='tfc1', bn_decay=bn_decay)
net = tf_util.fully_connected(net, 256, bn=True, is_training=is_training,
scope='tfc2', bn_decay=bn_decay)
with tf.variable_scope('transform_XYZ') as sc:
assert(K==3)
weights = tf.get_variable('weights', [256, 3*K],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
biases = tf.get_variable('biases', [3*K],
initializer=tf.constant_initializer(0.0),
dtype=tf.float32)
biases += tf.constant([1,0,0,0,1,0,0,0,1], dtype=tf.float32)
transform = tf.matmul(net, weights)
transform = tf.nn.bias_add(transform, biases)
transform = tf.reshape(transform, [batch_size, 3, K])
return transform
 维度,并reshape成
维度,并reshape成  ,得到transform matrix
,得到transform matrixdef get_loss(pred, label, end_points, reg_weight=0.001):
""" pred: B*NUM_CLASSES,
label: B, """
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=pred, labels=label)
classify_loss = tf.reduce_mean(loss)
tf.summary.scalar('classify loss', classify_loss)
# Enforce the transformation as orthogonal matrix
transform = end_points['transform'] # BxKxK
K = transform.get_shape()[1].value
mat_diff = tf.matmul(transform, tf.transpose(transform, perm=[0,2,1]))
mat_diff -= tf.constant(np.eye(K), dtype=tf.float32)
mat_diff_loss = tf.nn.l2_loss(mat_diff)
tf.summary.scalar('mat loss', mat_diff_loss)
return classify_loss + mat_diff_loss * reg_weight
5 conclusion
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿 
▲长按关注公众号
▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款 
圈里有高质量教程资料、可答疑解惑、助你高效解决问题 觉得有用,麻烦给个赞和在看~ 

