
只用C++和Python,让你的简笔画实时动起来!
共 2193字,需浏览 5分钟
· 2020-06-02
 大数据文摘出品作者:刘俊寰
大数据文摘出品作者:刘俊寰
让蒙娜丽莎笑起来对AI来说已经不是什么新鲜事了。
试想,如果在画纸上创作的图像能够实时地生成动画,达芬奇可能会吓个半死。
没错,文摘菌今天要给大家介绍的,就是捷克技术大学和Snap研究小组合作开发的一种全新的样式转换技术,在论文“使用基于少量补丁的培训进行交互式视频样式化”中,他们提出,该技术将够将某种绘画风格的静态图像实时格转换为动态动画。
效果嘛还是自己看了才知道:
据了解,研究小组利用了深度学习,在将手写样式转换为图像或视频的过程中,仅仅对样式进行转换,内容原型的创作风格丝毫不会受到影响。
同时,与此前的转换方法相比而言,这项技术无需借助庞大的数据集,甚至无需进行预训练,对关键帧进行的样式设置就是训练网络的唯一数据来源。
20万参数设置,每秒17帧进行风格转换
整个实验中,研究人员主要利用的编程语言是C++和Python。
对于选定的评估序列中的帧,研究人员计算了它们的样式化,在有48个Nvidia Tesla V100 GPU环境下模拟3天后就完成了。
整个实验总共抽查了大约200,000个不同设置的超参数(hyperparameters),并在以下区间内进行了对比实验,Wp∈(12,188),Nb∈(5,1000),Nr∈(1,40),α∈(0.0002,0.0032),最终发现最佳的补丁大小(optimal patch size)为Wp=36。
下图比较了不同超参数设置的视觉质量,其中超参数优化一个很有趣的结果是,在左边的图像中,一个批次的补丁Nb=40相对较少,这与选择的基于补丁的训练方案相互作用。虽然常见的策略是尽可能扩大Nb,以利用GPU能力,但在案例中,增加Nb实际上却只会适得其反,因为它将训练方案变成了全帧方案,往往会使网络在关键帧上过度拟合。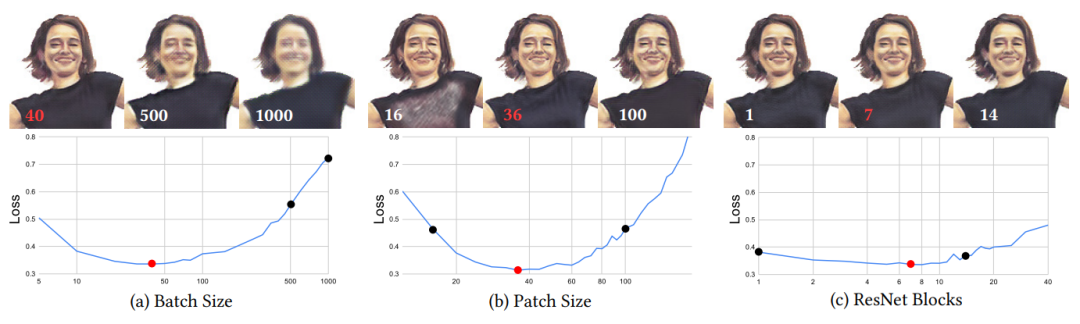
中间的图像即是最佳补丁大小Wp=36,较小的补丁可能无法提供足够的上下文,较大的补丁可能会使网络对目标对象的变形,从而使得网络对目标对象的变形引起的外观变化的抵抗力较差。
但在右图中,令人惊讶的是,ResNet区块数Nr对质量没有明显影响,尽管有一个微妙的鞍点(saddle point),对学习率参数α进行实验也能发现类似的效果。
在将所有的超参数优化后,研究人员发现,对于有效像素10%、分辨率640×640的视频序列,可以以每秒17帧的速度进行风格转换。
研究人员利用了一组分辨率从350×350到960×540的视频序列对系统进行了评估,这些视频包含不同的视觉内容,如人脸、人体等,以及不同的艺术风格,如油画、粉笔画等。
对于相对简单的序列而言,仅使用一个关键帧就可以进行样式转换,更复杂的序列则需要使用多个关键帧。在训练前,研究人员利用双侧时间滤波器(bilateral temporal filter)对目标序列进行了预滤波,当序列包含有不明确内容时,计算一个辅助输入层利用到了随机有色的高斯混合,以跟踪目标序列中的运动。
在训练阶段,研究人员从所有关键帧k中随机抽取掩码Mk内的补丁,将它们分批反馈给网络来计算丢失和反向传播错误,随后在Nvidia RTX 2080 GPU上进行训练和推理。训练时间与输入补丁数量成正比,例如,对于包含掩码内所有像素的512×512关键帧,训练时间为5分钟。训练完成后,整个序列可以以大约每秒17帧的速度进行风格转换。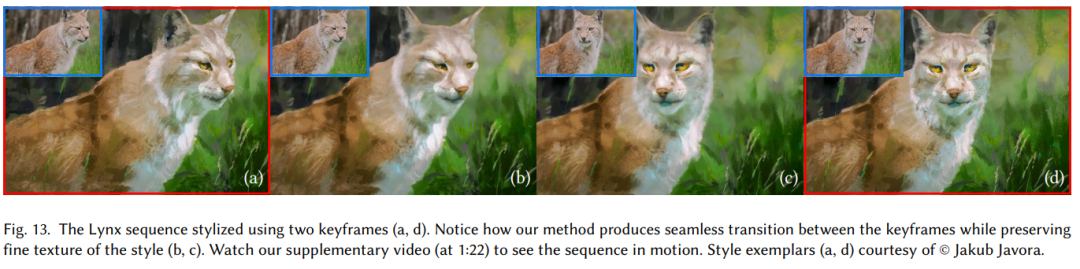
实时样式转换如何炼成?
相关样式转换的技术早在2016年就有人想到了,当时,在一篇名为“使用卷积神经网络进行图像样式转换”的论文中,研究人员提出了一种结合了VGG与CNN的转换技术,能够做到把内容与样式有效区分的同时,保留内容转换样式。
在这之后,出现了一些将该项技术推广到电影或视频领域的应用,其中找到分离图像内容和样式的损失函数是关键。
2019年,有研究人员提出了一种机制更改视频的一个关键帧,并将其传输到另一个序列(整个视频)中的方法,这种基于补丁的输出能够得到高质量的结果输出。
不过,这些转换技术仍然只能针对连续视频进行样式转换,也就是说,它们不支持随机访问、并行处理和实时交互,而这些正是能够实时转换图像的技术核心。
为了实现实时样式转换,研究人员在进行系统设计时对之前的研究进行了一定程度的参考,比如在设计滤波器时,他们采用了一种基于U-net的图像到图像转换框架,这种自定义网络架构能够保留原始风格范例的重要高频细节。
但是在训练过程中,他们发现系统产生的结果质量无法达到标准,这是因为原始网络是基于FaceStyle算法产生的大量风格样本数据集训练,这导致该方法在很多场景下不可使用。同时,原始方法没有考虑到时间的连贯性,生成的序列也包含了明显的时间闪烁。
为此,研究人员改变了网络的训练方式,并提出了一个优化问题,允许对网络的结构和超参数进行微调,以获得与当前最先进的风格化质量相媲美的风格化质量,这样的话,即使只有少量的训练样本也可实现目的,而且训练时间较短。
当然,除了滤波器设计之外,要实现实时样式的转换,研究团队还做出了不少创新,文摘菌在这里就不过多剧透了,想要了解更多细节的小伙伴们快去原文挖宝吧~
论文链接:
https://ondrejtexler.github.io/res/Texler20-SIG_patch-based_training_main.pdf
好文章,我在看❤️