
原创丨爬虫神器!用它可以实时处理和保存 Ajax 数据
共 4980字,需浏览 10分钟
· 2020-06-01
“
阅读本文大概需要 5 分钟。
做爬虫的时候我们经常会遇到这么一个问题:
网站的数据是通过 Ajax 加载的,但是 Ajax 的接口又是加密的,不费点功夫破解不出来。这时候如果我们想绕过破解抓取数据的话,比如就得用 Selenium 了,Selenium 能完成一些模拟点击、翻页等操作,但又不好获取 Ajax 的数据了,通过渲染后的 HTML 提取数据又非常麻烦。
或许你会心想:要是我能用 Selenium 来驱动页面,同时又能把 Ajax 请求的数据保存下来就好了。
办法自然是有,比如可以加层代理,用 mitmdump 来实时处理就好了。
但如果不用代理,没有好的办法呢?
这里我们介绍一个工具,叫做 AjaxHook,利用它我们可以把 Ajax 请求的数据都拦截下来,只要发生了一个 Ajax 请求,它就能把请求和响应截获下来,这样我们就能实现 Ajax 数据的实时处理了。
Ajax Hook
Hook 大家估计不陌生了吧,这里我就不再展开讲了,不太明白的可以自行搜索「Hook 技术」就能搜到一把资料。
那 Ajax Hook 顾名思义就是 Hook Ajax 请求了,Ajax 最重要的两个部分?当然就是 Request、Response 了,有了 Hook,我们就能在发起 Request 前和得到 Response 后对二者进行处理了。
其基本作用点如图所示:
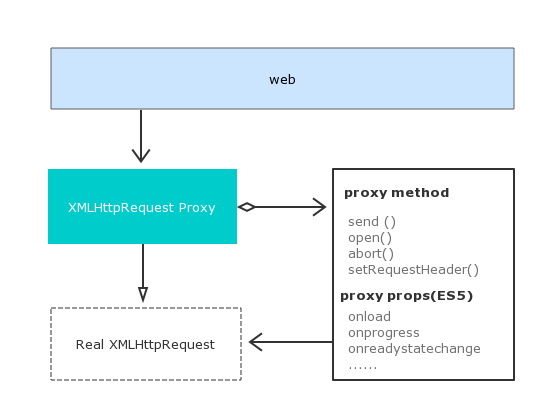
那我们怎么来 Hook Ajax 请求呢?那自然就需要深入到 Ajax 的原生实现了。Ajax 其实就是利用 XMLHttpRequest 这个对象来实现的,要 Hook Ajax 的 Request 和 Response,那其实就是对它里面的一些属性做一些处理,比如 send、onreadystatechange 等等。
听起来似乎很麻烦的样子,不用担心,已经有人把这个写好了,我们直接拿来用就好了,GitHub 地址为:https://github.com/wendux/Ajax-hook。
其实这个内部实现原理非常简单,其实刚才就简单提了一下,要想深入了解的话可以看下这篇文章:https://www.jianshu.com/p/7337ac624b8e。
OK,那这个怎么用呢?
Ajax-hook 的这个作者提供了两个主要方法,一个是 proxy,一个是 hook,起作用都是来 Hook XMLHttpRequest 的。
这里借用一下官方介绍:
proxy 和 hook 方法都可以用于拦截全局XMLHttpRequest。它们的区别是:hook 的拦截粒度细,可以具体到 XMLHttpRequest 对象的某一方法、属性、回调,但是使用起来比较麻烦,很多时候,不仅业务逻辑需要散落在各个回调当中,而且还容易出错。而 proxy 抽象度高,并且构建了请求上下文,请求信息 config 在各个回调中都可以直接获取,使用起来更简单、高效。
大多数情况下,我们建议使用 proxy 方法,除非 proxy 方法不能满足你的需求。
那我们就来看看 proxy 方法的用法吧,其用法如下:
proxy({//请求发起前进入onRequest:(config, handler)=>{console.log(config.url)handler.next(config);},//请求发生错误时进入,比如超时;注意,不包括http状态码错误,如404仍然会认为请求成功onError:(err, handler)=>{console.log(err.type)handler.next(err)},//请求成功后进入onResponse:(response, handler)=>{console.log(response.response)handler.next(response)}})
很清楚了,Ajax-hook 给我们提供了三个方法供复写,onRequest、onResponse、onError 分别是在请求发起前的处理、请求成功后的处理、发生错误时的处理。
那我们如果要做数据爬取的话,其实就是为了截获 Response 的结果,那其实实现 onResponse 方法就好了。
再仔细看看,这个 onResponse 方法接收两个参数,为 response 对象和 handler 对象,这都是 Ajax-hook 为我们封装好的,其实这里我们只需要用 response 里面的内容就好了,比如把 Response Body 打印出来,其实就是把 Ajax 得到的结果打印出来了。
行,那我们就来试试吧。
案例介绍
下面我们就拿一个我自己的案例来讲吧,链接为:https://dynamic2.scrape.center/,界面如下:
这个网站是一个电影数据网站,其数据都是通过 Ajax 加载的,但是这些 Ajax 请求都带着加密参数 token,如图所示:
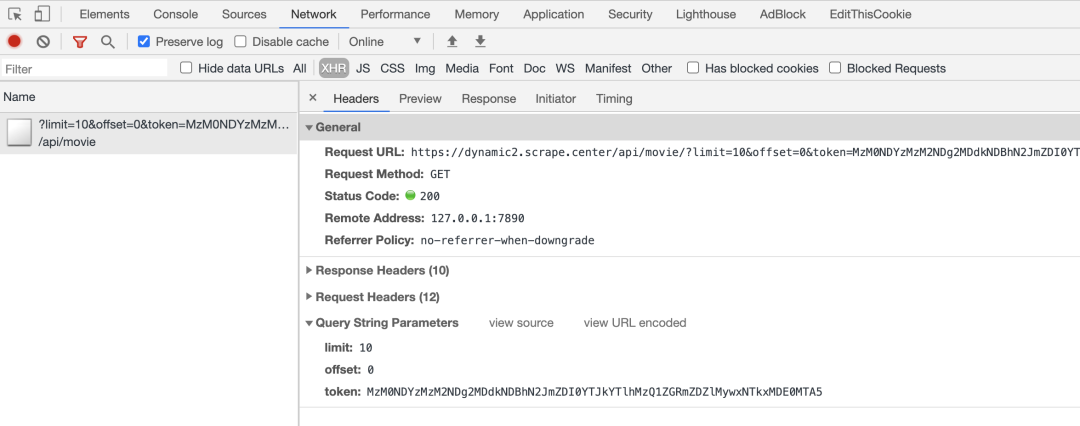
其实这个参数你要解的话倒不是很难,不过也得费点时间。
然后再看下 Ajax 的返回结果,如图所示:
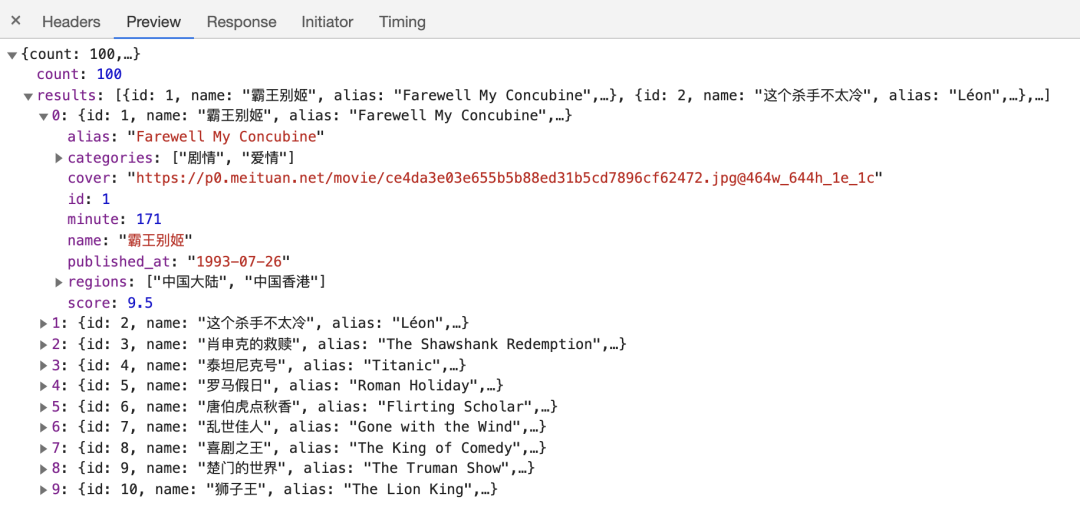
很纯很清晰!所以我们如果能够在得到 Ajax Response 的时候就把这些数据直接拿到,那就美滋滋了。
怎么办?自然是用刚才所说的 Ajax-hook 了。
所以,我们这里就用上这个 Ajax-hook 来对这些数据进行实时处理吧。
实战操作
首先,第一步那我们得能用上 Ajax-hook,怎么用呢?那肯定得需要引入一下这个 Ajax-hook 库,浏览器里的这个页面又怎么引入呢?
答案有很多,比如复写 JavaScript、Tampermonkey、Selenium 等等。
这里我们就用最简单的方法,Selenium 自动执行一下 Ajax-hook 的源代码就好了。
那这时候我们就需要找到 Ajax-hook 的源码了,去 GitHub 一找就有了,链接为:https://raw.githubusercontent.com/wendux/Ajax-hook/master/dist/ajaxhook.min.js,如图所示:
看,代码量真不多吧。
我们把这个代码复制,粘贴到 https://dynamic2.scrape.center/ 这个网站的控制台里。
这时候我们会得到一个 ah 对象,代表 Ajax-hook,我们就能用它里面的 proxy 方法了。
怎么用呢?就直接实现 onResponse 方法,打印 Response 的结果就好了,实现如下:
ah.proxy({//请求成功后进入onResponse:(response, handler)=>{if(response.config.url.startsWith('/api/movie')){console.log(response.response)handler.next(response)}}})
把这段代码也放在控制台运行下,这时候我们就实现了 Ajax Response 的 Hook 了,只要有 Ajax 请求,Response 的结果就会被输出出来。
这时候如果我们点击翻页,触发一个新的 Ajax 请求,就可以看到控制台输出了 Response 的结果,如图所示:
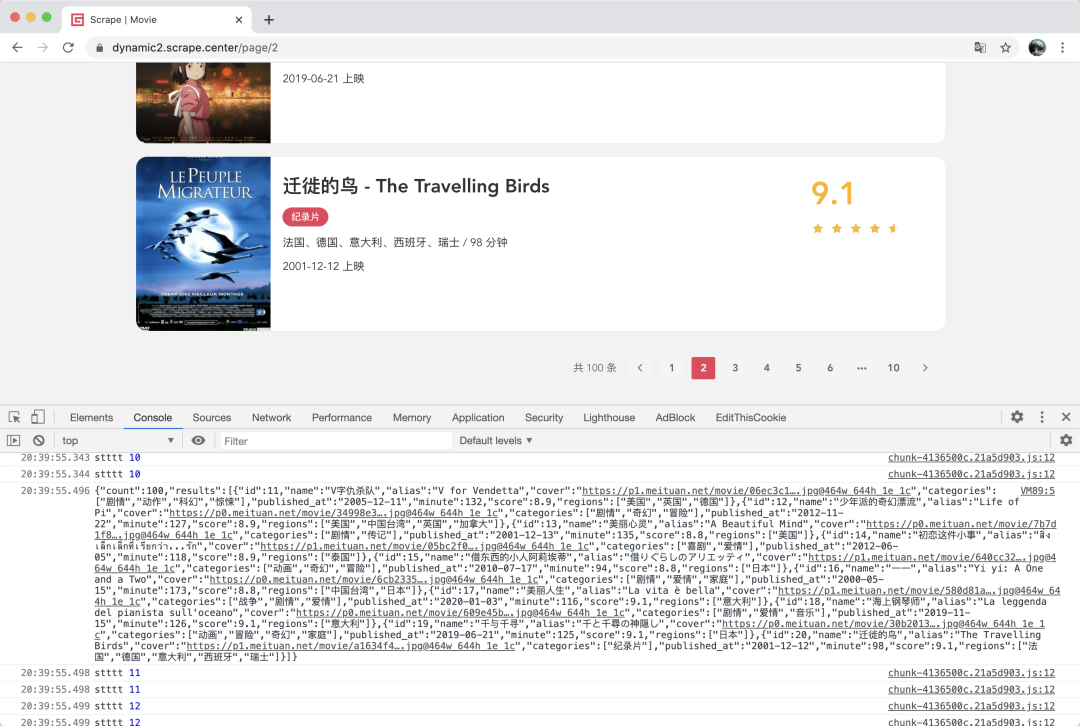
嗯,这下我们就能获取到 Ajax 的数据了。
数据转发
那现在数据在浏览器里面啊,我们怎么存下来呢?
存还不简单,最简单的,把这个数据转发给自己的一个接口保存下来就好了。
那我们就用 Flask 简单弄一个接口吧,记得解除跨域限制,实现如下:
import jsonfrom flask importFlask, request, jsonifyfrom flask_cors import CORSapp =Flask(__name__)CORS(app)@app.route('/receiver/movie', methods=['POST'])def receive():content = json.loads(request.data)print(content)# to somethingreturn jsonify({'status':True})if __name__ =='__main__':app.run(host='0.0.0.0', port=80, debug=True)
这里我就简单写了个示例,写了一个能接收 POST 请求的 API,地址为 /receiver/movie,然后把 POST 的数据打印出来再返回一个响应。
当然这里你可以做很多操作了,比如把数据切割,存储到数据库等都是可以的。
好的,那现在服务器有了,我们就在 Ajax-hook 这边把数据发过来吧。
这里我们借助于 axios 这个库,其库地址为 https://unpkg.com/axios@0.19.2/dist/axios.min.js,也是放在浏览器执行就能用。
引入 axios 之后,我们把之前的 proxy 方法修改为如下内容:
ah.proxy({//请求成功后进入onResponse:(response, handler)=>{if(response.config.url.startsWith('/api/movie')){axios.post('http://localhost/receiver/movie',{url: window.location.href,data: response.response})console.log(response.response)handler.next(response)}}})
其实这里就是调用了 axios 的 post 方法,然后把当前 url 和 Response 的数据发给了 Server。
到现在为止,每次 Ajax 请求的 Response 结果都会被发给这个 Flask Server,Flask Server 对其进行存储和处理就好了。
自动化
OK,那现在我们已经可以实现 Ajax 拦截和数据转发了,最后一步自然就是把爬取自动化了。
自动化就分为三部分:
•打开网站。•注入 Ajax-hook、axios、proxy 的代码。•自动点击下一页翻页。
最关键的就是第二步了,我们把刚才 Ajax-hook、axios、proxy 的代码都放在一个 hook.js 文件里面,用 Selenium 的 execute_script 来执行就好了。
其他的几步很简单,最后实现如下:
from selenium import webdriverimport timebrowser = webdriver.Chrome()browser.get('https://dynamic2.scrape.center/')browser.execute_script(open('hook.js').read())time.sleep(2)for index in range(10):print('current page', index)btn_next = browser.find_element_by_css_selector('.btn-next')btn_next.click()time.sleep(2)
最后,运行一下。
可以发现浏览器先打开了页面,然后模拟点击了下一页,再回过头来观察下 Flask Server 这边,可以看到 Ajax 的数据就接收到了,如图所示:
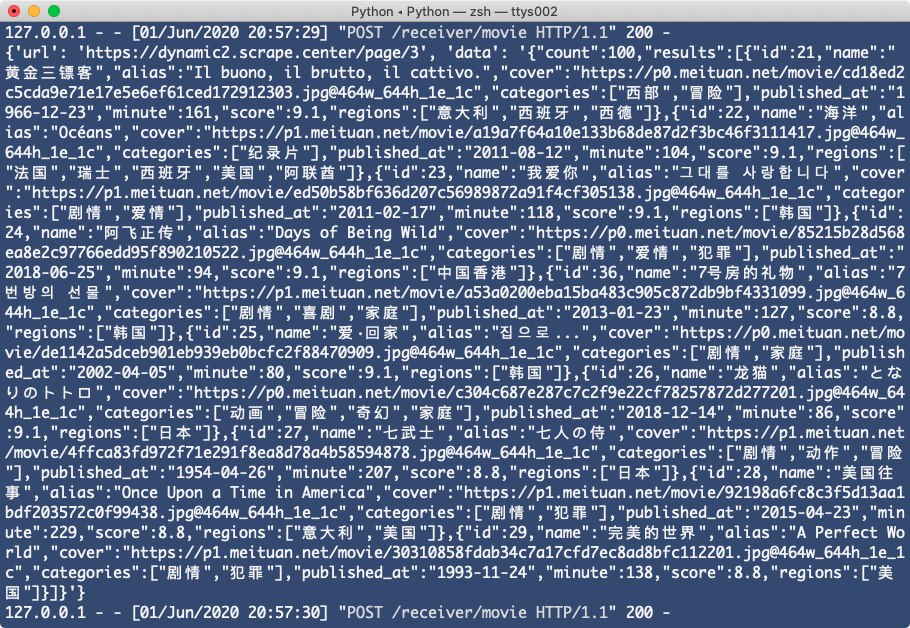
OK,到此为止。
总结
至此,我们就完成了:
•Ajax Response Hook•数据转发与接收•浏览器自动化
以后我们再遇到类似的情形,也可以用同样的思路来处理了。
本节代码:https://github.com/Python3WebSpider/AjaxHookSpider。
崔庆才丨静觅
隐形字
同名公众号「崔庆才丨静觅」
在这里分享自己的一些经验、想法和见解。


长按识别二维码关注
好文和朋友一起看~