
真的,不要迷信数据分析.
数据森麟
共 2884字,需浏览 6分钟
· 2020-05-27


来源:知乎
作者:Allen Sun
最近有同学问了我一个很致命的问题:数据分析真的有必要做吗?为什么感觉都是伪需求?怎么确定数据分析结论是真的?
其实这个问题我也曾经想过,究竟为什么很多人都在神化数据分析,遇到任何问题不管三七二十一,都要拿出数据来分析一通?
其实,这是过度追求数据分析的表现,数据往往不一定就是真实客观的,做数据分析的人也会被数据给欺骗,所以很多时候太过迷信数据,反而容易出问题。
所以今天从数据来源偏差、数据解读陷阱、人为操控误导这三方面来聊聊数据的“坑”,希望你看完后能了解些套路,再看报告或数据时多个心眼,带着怀疑的精神看数据,不要掉入陷阱。


一、数据来源偏差
1、样本量和代表性
你可能听说过“黑巧克力能减肥”这个说法。2015年约翰波哈诺博士在一篇期刊上登出了这项研究成果,媒体记者们纷纷转载。但其实这个事件都是波哈诺杜撰出来的,他随便找了16个人做样本基数,然后就推导出这么个结论,目的就是想看看谣言怎么变成权威媒体的头条。研究发表后没有一个记者来联系他问他这个实验的样本量是多少、代表性怎么样、过程是否合理,直接就发表和引用了“研究成果”。 所以,样本量和代表性是决定数据结果靠不靠谱的前提条件。
所以,样本量和代表性是决定数据结果靠不靠谱的前提条件。大厂们虽然看起来有“大”数据,但是由于数据孤岛的存在,其实数据也是有偏向的。比如阿里固然有淘宝几亿用户的消费数据,但是也拿不到这几亿用户的微信数据。而且大数据基本都是行为数据,和真实态度、心理预期等等态度数据还有有差别,再有就是用相关性推测因果也有不少坑。作为非专业人士的我们,其实看报告或者看数据时主要还是留个心眼。看看有没有提到数据源,数据源可能带来哪种偏差,带着思考去看报告。如果看到一些数据结论和你的认知有差别、甚至是相反的,不用立刻相信结论,扭转认知,而是先想一想这数据来源靠谱嘛,发数据的机构有目的吗。另外,也不用太纠结于具体数字,而是去看数字背后的趋势、比较、差异。
2、问题缺陷刚才我们也提到大数据更多是行为数据,有时要拿到态度数据,还是要靠用问卷问问题的方式。在用问卷收集数据时,如何问对问题就很有讲究了,比如这几种情况:曾经有个某饮料品牌打算推出新口味的饮品,推出前心里没底,就做调查。他们问了一个问题“我们要推出一款口味更柔和的新产品,你会喜欢吗?”数据收集回来以后,发现喜欢的比例高达90%,结果新品上市以后,消费者恶评如潮。现实和数据体现了如此大的反差,原因就在于问题中有一个很明显的正面诱导词“更柔和”。所以无论是看别人的数据报告,还是自己做问卷,都得注意问的问题是不是客观无偏向,选项是不是合理。选项一般来说要尽可能符合MECE原则。
二、数据解读陷阱
数据解读可以说是遍地是坑,这里我选了比较常见和有意思的几种。1. 相关不等于因果相关和因果是解读数据绕不开的话题,特别是我们要用数据去预测趋势,解决问题,用一件事的情况去推测和判断另一件事,搞混相关和因果,就容易闹笑话。比如:
每年冰淇淋销量一升高,游泳溺亡人数就开始增长。所以禁止销售冰淇淋,有助于挽救生命。
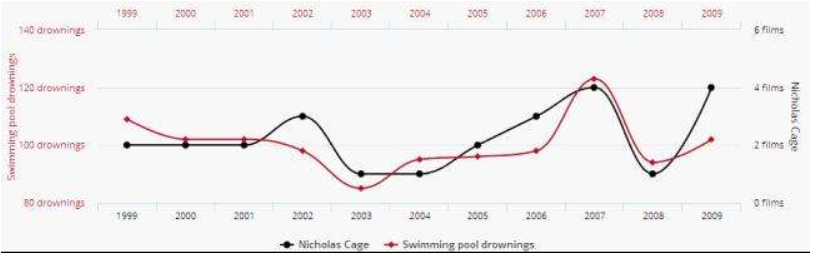 其实,事件A和事件B有相关关系,但可能有因果关系也可能没有因果关系。
其实,事件A和事件B有相关关系,但可能有因果关系也可能没有因果关系。这个道理说起来简单,好像人人也都知道,但是很多时候,甚至经验丰富的分析人员也会在这上面犯错。其实很多时候我们都是带着期待,带着目的在看数据,我们希望数据能告诉我们真相,给我们解答,告诉我们为什么,好让我们做出决策。所以看到两条曲线趋势有规律,看到两组数据有相关,就会开始兴奋,感觉自己好像抓到了答案,但这时候就往往容易过度解读。数据只是数据而已,所谓答案其实不是数据告诉你的,而是你自己推出来的。越是这时候就越应该冷静一下,多思考,不要轻易下判断。
2. 幸存者偏差还有一个特别有名的误读,你可能也听说过,就是大名鼎鼎的幸存者偏差。幸存者偏差是怎么来的呢?二战期间,美军计划在飞机上安装厚钢板来抵抗攻击,提升飞行员生存率。但是因为重量限制,只能给最关键的部位安装。他们仔细检查了所有返航回来的飞机机身上的弹孔分布,发现大部分都位于机翼和飞机尾部。于是大家就热火朝天准备给机翼加钢板。
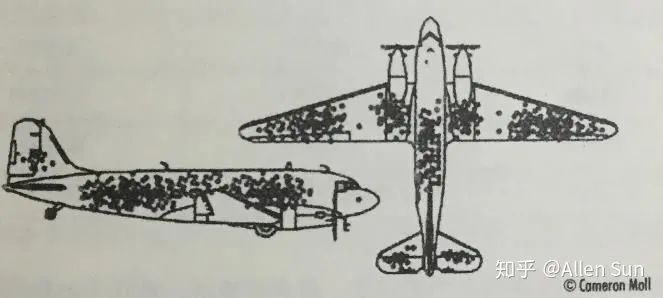 但是这时候,数学家瓦尔德就站出来反对,他说要加强那些没弹孔的位置,比如发动机和驾驶舱。
但是这时候,数学家瓦尔德就站出来反对,他说要加强那些没弹孔的位置,比如发动机和驾驶舱。3. 自选择偏差有时我们自以为找到了支持自己想法的客观数据,但其实我们是先有了想法,再找数据来支持自己的想法,那些不符合我们假设的数据会被忽视掉,这就是“选择偏差”。
4. 辛普森悖论这个就比较神奇了,我们还是先看个故事:话说有个综合大学招生,结果招生数据一公布,男生们都表示反对:因为女生的录取率比男生要高很多!
 而事实上呢,其实明明两类院系都是男生录取率高,但是一加起来,就变成女生录取率高了:
而事实上呢,其实明明两类院系都是男生录取率高,但是一加起来,就变成女生录取率高了: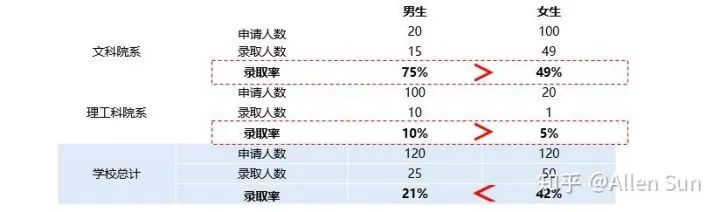 其实是因为文科院的女生录取率拉高了女生整体录取率,而理工科的男生录取率拉低了男生整体录取率。这就是辛普森悖论,两组数据分别看时都满足某种结果/趋势,但加起来就呈现相反结果/趋势。
其实是因为文科院的女生录取率拉高了女生整体录取率,而理工科的男生录取率拉低了男生整体录取率。这就是辛普森悖论,两组数据分别看时都满足某种结果/趋势,但加起来就呈现相反结果/趋势。三、人为操作误导
前面讲的那些坑很多时候都是无意的。这部分就不太一样了,很多数据其实稍加修饰,就成了一个个陷阱。1. 放大尺度比如你看下面这张图,是不是增长势头非常猛?要是当成业绩汇报给老板岂不是分分钟要升职加薪走上巅峰。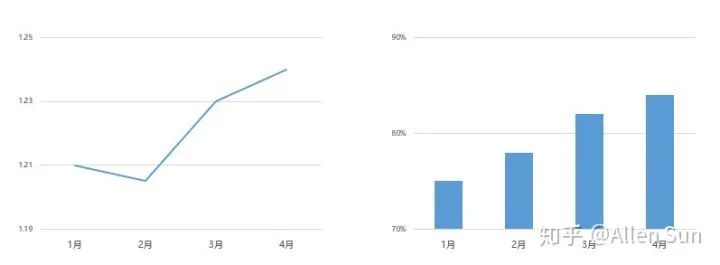 但其实注意Y轴,这种差异只是被人为的放大了,一旦回归正常尺度……
但其实注意Y轴,这种差异只是被人为的放大了,一旦回归正常尺度……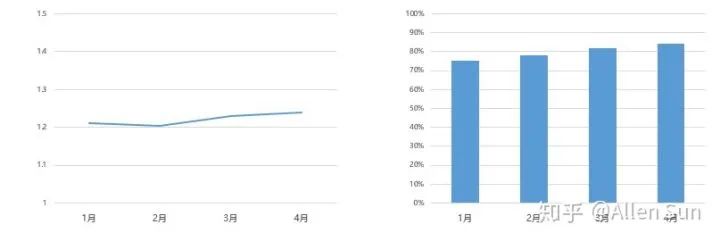
2. 重新定级川普做了民调,发现30-39岁的刁民们对自己很不友善:
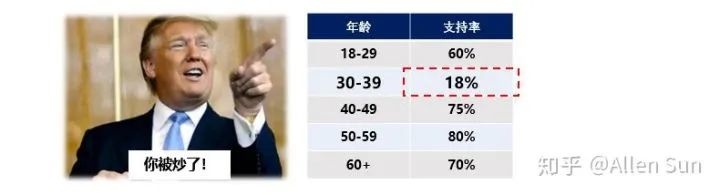 这要公布出去,岂不是要在推特上被喷爆,于是将两个层次进行合并:
这要公布出去,岂不是要在推特上被喷爆,于是将两个层次进行合并: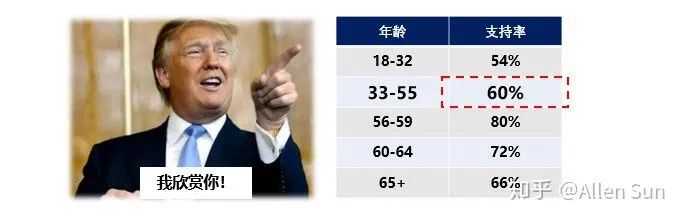 这样一看,就好看多了。
这样一看,就好看多了。3. 提自己,不做对比。购买A类产品的用户中80%都是甲类用户,是不是就应该给甲类用户推荐更多A类产品?这个结论乍一看没有问题,但是如果B类产品的用户中90%都是甲类用户呢?如果B类产品只有20%是甲类用户,但是B类产品基数远大于A类呢?
很多时候,数据还是要对比才有意义。
4. 自定标准只要你敢加的标签足够多,你就永远是名列前茅。虽然小明考试考了班里的40名,但是他在第四列所有身高1.7以上的学生中排第2。所以再看到有广告声称自己产品排名怎么怎么样,可以想一想这排名是怎么排出来的。
5. 片面释放为什么每次平均收入一公布,大家都觉得自己拖后腿了?其实数据分布情况不一样,平均数有时并不能描述“平均情况”。还有中位数、众数呢。
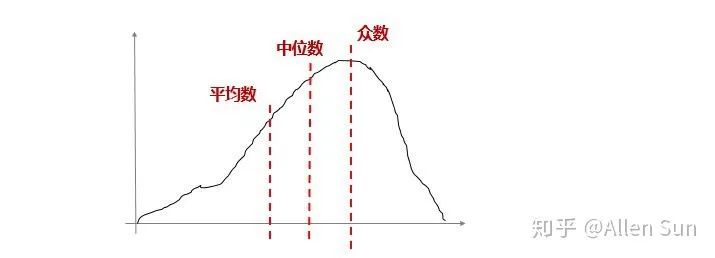 总而言之,数据也只是数据,它来帮助我们理解复杂世界中的庞大信息,但是不是万能的,是来帮我们解释,而不是替我们思考的,所以“尽信数据,还不如无数据”。
总而言之,数据也只是数据,它来帮助我们理解复杂世界中的庞大信息,但是不是万能的,是来帮我们解释,而不是替我们思考的,所以“尽信数据,还不如无数据”。◆ ◆ ◆ ◆ ◆
长按二维码关注我们
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
评论