 Crossin的编程教室
Crossin的编程教室




大家好,欢迎来到编程教室~
ChatGPT、StableDiffusion的火爆,让很多同学都想在自己的电脑上部署本地大模型,进而学习AI、微调模型、二次开发等等。
然而现在动辄好几万的高算力显卡让很多人望而却步。

但其实还有一种方案,就是使用云主机。比如我最近在用的潞晨云,4090显卡的机器,现在还不到2块钱一小时,甚至还能用上现在一卡难求的H800。
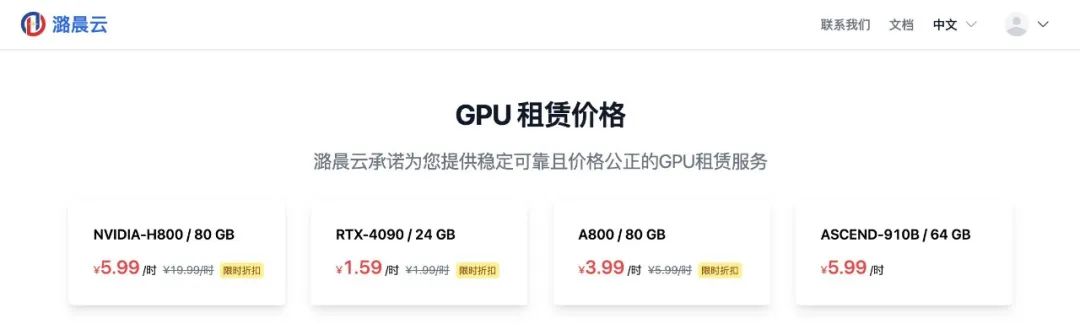
使用云主机也很方便,直接选择你想要的配置,创建新的云主机。
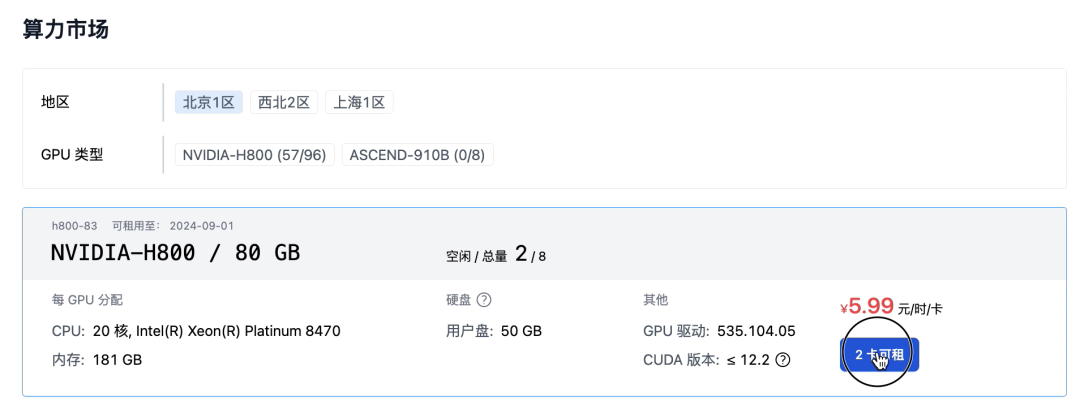
取个名字,选择显卡数量。
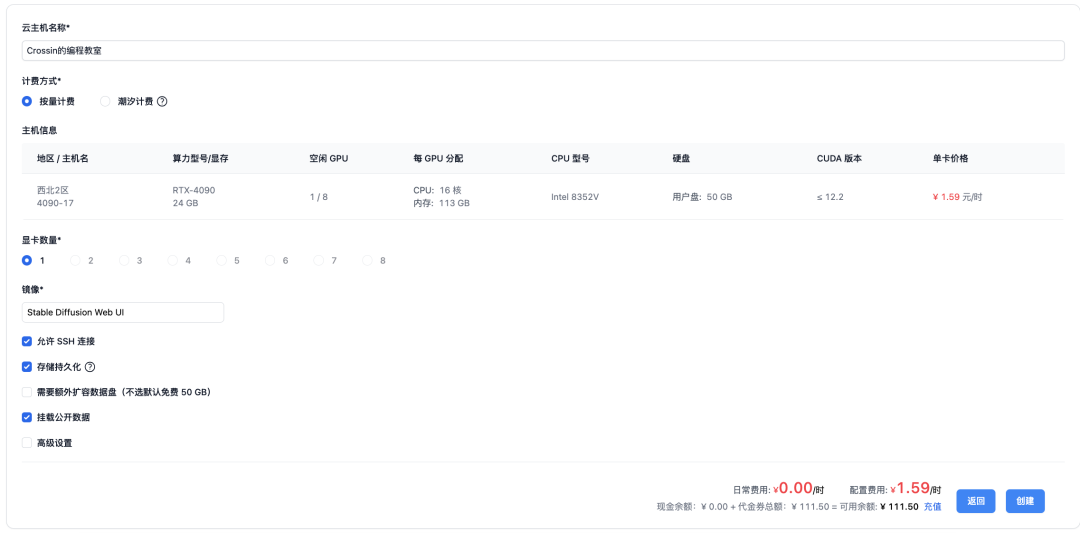
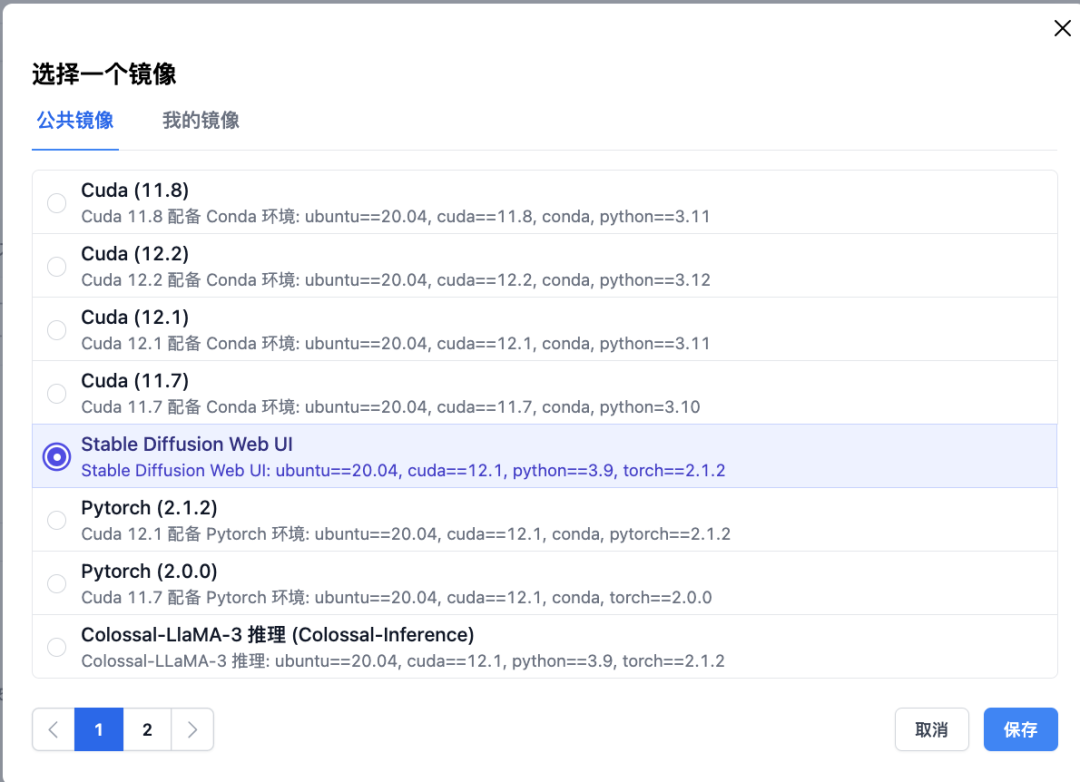
潞晨云提供了很多预先配置好的公共镜像,以满足一些常用开发场景。省去了配置环境的麻烦,开箱即可用。还提供一些公开的模型数据可挂载使用。
创建主机,等待初始化完成开机后,可以直接通过控制台提供的JupyterLab访问,也可在添加SSH公钥后,通过本地控制台,或者VSCode远程连接等方式操作主机和编写代码。
建议先添加SSH公钥,再创建主机,这样 SSH 公钥会自动生效。

最近经常刷到一些AI制作的绘本故事短视频。下面我就用云主机上部署的AI工具,来仿制一个这样的视频。
我打算做一个简单的四格漫画。
1. 脚本
首先要创作故事脚本。我的想法是用Meta前阵子刚刚发布的开源大语言模型Llama 3,让它来帮我写。这里我选择ollama这个框架,它可以很方便地调用llama3模型。
安装ollama只需要一行命令,然后等待自动下载安装:
curl -fsSL https://ollama.com/install.sh | sh
安装完成后启动服务:
ollama serve
运行 llama3 并与之对话:
ollama run llama3
第一次运行时,程序会去下载模型文件。
如果要使用 llama3-70b,就改一下命令中的模型名:
ollama run llama3:70b
但因为70B的模型有40G,默认地址下的空间不足的话,需要修改环境变量 OLLAMA_MODELS,将模型路径设到 /root/dataDisk,然后再启动ollama
export OLLAMA_MODELS=/root/dataDisk/.ollama/models
告诉llama3,帮我写一个四格卡通连环画的剧本,主角是一只想学做饭的猫,让它提供配图的中文说明和英文提示词。

2. 绘图
有了剧本和提示词,接下来就可以绘制插画了。潞晨云默认提供了StableDiffusionWebUI的镜像,选择此镜像创建主机后(建议选择1卡H800机器),就可以通过一行命令直接启动网页版的StableDiffusion。
cd /root/stable-diffusion-webui
bash webui.sh -f
控制台输出中看到如下地址说明运行成功,记录下端口号:

因为限制了公网端口访问,我们在本地做一个ssh端口转发,就能在本地浏览器通过 http://127.0.0.1:7860 打开了。
sh -CNg -L 本地端口:127.0.0.1:7860 root@云主机地址 -p 端口号
把llama3生成的提示词贴进去稍作修改,设定下出图的数量,就能得到与剧情配套的插图。调节参数多试几次,从中选择你满意的图。就可以拿来制作视频了。
3. 视频
假如你觉得静态的图片太过单调。还可以尝试用AI生成视频片段。之前OpenAI发布的文生视频大模型Sora火爆全网,可惜目前我们还没法用上它。
而潞晨团队开源的 Open-Sora 项目,尝试对Sora的效果进行了复现,尽管在时长和效果还有差距,但还是很值得期待的。目前Open Sora在 github 上已有1万7千多star。

同StableDiffusion一样,潞晨云也提供了OpenSora的镜像。创建主机之后(建议选择1卡H800机器),配置一下环境路径,就可以使用了。注意:一定要选择“挂载公开数据”。
mkdir -p /root/.cache/huggingface/hub
ln -s /root/notebook/common_data/OpenSora-1.0/models--stabilityai--sd-vae-ft-ema /root/.cache/huggingface/hub/models--stabilityai--sd-vae-ft-ema
ln -s /root/notebook/common_data/OpenSora-1.0/models--DeepFloyd--t5-v1_1-xxl /root/.cache/huggingface/hub/models--DeepFloyd--t5-v1_1-xxl
我们把提示词替换到项目的配置文件 assets/texts/t2v_samples.txt 中,执行程序:
cd Open-Sora/
python -m torch.distributed.run --standalone --nproc_per_node 1 scripts/inference.py configs/opensora/inference/16x512x512.py --ckpt-path /root/notebook/common_data/OpenSora-1.0/OpenSora-v1-HQ-16x512x512.pth --prompt-path ./assets/texts/t2v_samples.txt
稍等片刻,就会在 samples/samples 文件夹中得到生成的视频。
4. 配音
最后,还需要给故事增加一个朗读旁白。这个可以通过语音合成技术实现。这里我用的是Coqui-TTS。
通过pip命令就可以安装,支持包括中文在内的多种语言:
pip install TTS
用 tts 命令把 llama3 生成的配图说明转成语音:
tts --text "需要转换为语音的文字内容" --model_name "tts_models/zh-CN/baker/tacotron2-DDC-GST" --out_path speech.wav
这里 tts_models/zh-CN/baker/tacotron2-DDC-GST 为中文语音模型。
再同前面生成的视频整合到一起。
来看看最终的效果。 (参见文章开头的视频)

这个演示中,我用的都是些基础模型和默认配置,大家还可以在此基础上进一步微调和优化。虽然这几样功能,市面上都有现成产品可以实现。但对于学习AI的人来说,是要成为AI的产生者而不是消费者,所以还是得靠自己动手部署和开发。
这种情况下,尤其对学生党来说,云服务的性价比就很高了。假设只有3000块的预算,买台带4090显卡的电脑就别想了,但在潞晨云上,4090的云主机按2块钱一小时,平均每天使用4小时来算,就能用上375天了。而且还能根据你的需求快速升级和扩容,这点上比自己的电脑还要方便。
最近潞晨云还有活动可以领取代金券:
-
【百万补贴】优质线上算力资源百万补贴等你来薅,随开随用。
-
【企业认证】企业用户参与潞晨云企业认证可得500元代金券。
-
【分享有礼】:用户在社交媒体和专业论坛(如知乎、小红书、微博、CSDN等)上分享使用体验并带上“#潞晨云”,有效分享一次可得100元代金券。
了解详情可关注潞晨云官方公众号:潞晨科技
最后提醒一下,用完记得及时关机,节省点费用哦。
参考网址: 潞晨云:https://cloud.luchentech.comollama:https://ollama.com/download/linux coqui-tts:https://github.com/coqui-ai/TTS
添加微信 crossin123 ,加入编程教室共同学习 ~


