 WxJava
WxJava




时间过得很快啊,一转眼已经到了 2024 年,还记得 15 年刚工作那会掌握个 SSM/H(Spring/Struts2/Mybatis/Hibernate) 框架就能应付大部分面试了。
现在 CS 专业的新同学估计都没听说过 SSM😢
恰好从我刚开始工作时的移动互联网热潮到电商->共享经济->toB 大热->如今我都经历了一遍,技术栈也有由最开始的单体应用+物理机发展到现在的 kubernetes 云原生架构。
当然中途也经历了几个大的阶段:SOA服务化-> 微服务-> 云原生-> 服务网格-> 无服务等几个阶段。
最近一份工作又主要是在做基础架构,我认为了解的还算是比较全面的,所以本文我就以我的视角分享下我们在 2024 年应当使用哪些云原生技术栈,因为涉及到的技术组件比较多,就不过多讨论细节了。
但可以保证的是提到的技术栈都是我所用过的,优缺点都会提到,主打一个真实体验。
操作系统首先是操作系统,这里有别于以往我们传统的操作系统(Linux/Windows Server/MacOS),主要指的是云原生的操作系统,没有太多可以选择的余地,那就是 kubernetes。
不过怎么维护好 kubernetes 是一个难点问题,还记得去年下半年滴滴出过一次事故,网传就是 kubernetes 升级出现的问题。
根据我们的经验来看,对于小团队更建议直接托管给云厂商,维护 kubernetes 是一个非常复杂的工作,小团队通常都是一职多能,自己维护更容易出问题。
当然大团队有专人维护最好,即便是出问题也能快速响应,前提是自己能 cover 住这个风险。
因为我们是小团队,所以考虑到成本和稳定性,我们也只使用了云厂商的 kubernetes 能力,其余的部分可控组件由我们自己维护(具体的后文会讲到)
多云的优势与好处
既然都用了云厂商的容器服务,那也要考虑到云厂商故障可能带来的问题;比如去年的阿里云故障。
所以现在一些中大厂也会选择多云方案,将同一份代码部署再多个云服务商,一旦其中一个出现问题可以快速切换。
但具体的实施过程中也有许多挑战,比如最棘手也是最关键的数据一致性如何保证?
当然我们可以采用一些支持分布式部署的数据库或中间件,他们本身是支持数据同步的;比如消息队列中的 Pulsar,它就可以跨级群部署以及消息同步。
同时多云部署对应的成本也会提升,在这个“降本增效”的大背景下也得慎重考虑;所以对此还有一个折中方案:
我们的技术架构需要具备快速迁移到其他云服务的能力,比如我们内部有一些工具可以定期备份资源,比如 MySQL 的 binlog,一些中间件的元数据,同时可以基于这些元数据快速恢复业务。
一般遇到需要切换云服务时都是一些极端情况,所以允许部分运行时的数据丢失也是能接受的,我们只要保证最核心的数据不会丢失从而不影响业务即可。
这个说起来简单,但也需要我们花时间进行模拟演练;具体是否实施就得看公司是否接受云服务宕机带来的损失以及演练所花的成本了。
DevOps我们是具备恢复元数据能力的,但会丢失部分运行时的数据。
既然我们已经选择 kubernetes 作为我们云原生的操作系统,那我们的持续集成与发布也得围绕着 kubernetes 来做。
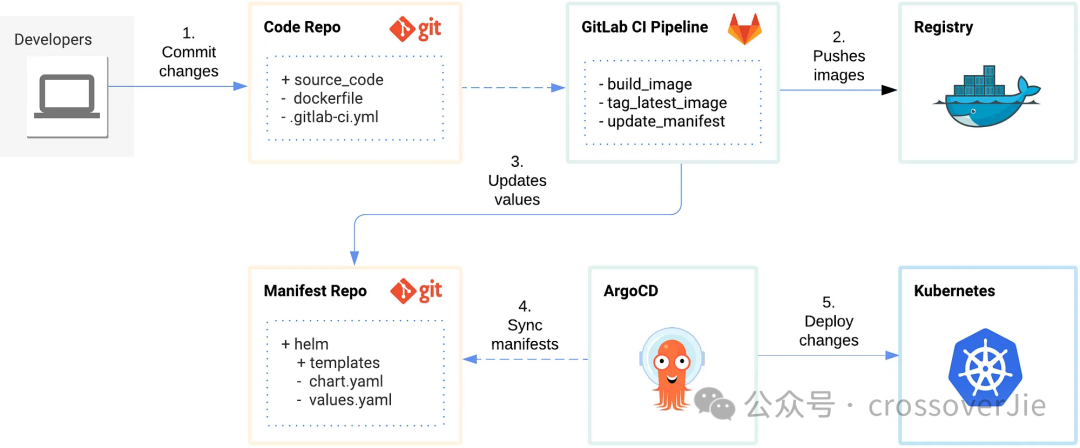
上图是一张使用 Git 配合 gitlab+ArgoCD 的流程图,我们使用 gitlab 来管理源码,同时也可以利用他的 Pipline 帮我们做持续集成,最终使用 Argo 帮我们打通 kubernetes 的流程。
也就是我们常说的
GitOps
同时我们的回滚历史版本,扩缩容都由 kubernetes 提供能力,我们的 DevOps 平台只需要调用 kubernetes 的 API 即可。
当然还有现在流行 FinOps,我的理解主要是做云成本的管理和优化,对应到我的工作就是回收一些不用的资源,在不影响业务的情况下适当的降低一些配置😳。
Service Mesh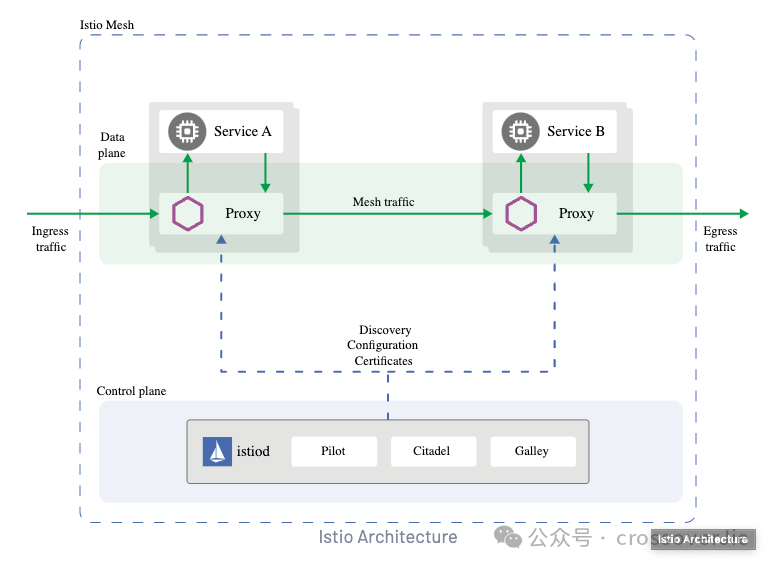
接下来便是我认为最重要的 Service Mesh 环节了,这个的背景故事就多了,本质上我觉得这都是由 RPC(Remote Process Call) 引起的也是分布式所带来的。
由最开始的单机的本地函数调用开始:
local+------>remote +------> micro-service+----->service-mesh
+ | +
v v v
+---+----+ +-----+------+ +----+----+
| motan | | SpringCloud| | Istio |
| dubbo | | Dubbo3.0 | | Linkerd |
| gRPC | | SOFA | | |
+--------+ +------------+ +---------+
主要经历了以上三个重要的阶段,分别是 RPC 框架到微服务再到现在的服务网格。
- RPC 框架主要帮我们简化了分布式通信,只专注于业务本身
- 微服务框架的出现可以更好的帮我们治理大批量的服务,比如一些限流、路由、降级等功能,让我们分布式应用更加健壮。
- 而如今的服务网格让我们的应用程序更加适配云原生,专注于业务研发而不再需要去维护微服务框架;将这些基础功能全部下沉到我们的基础层,同时也带来了不弱于微服务框架的功能性。
但使用 Istio 也有着不低的技术门槛,我觉得如果满足以下条件更推荐使用 Istio:
- 应用已经接入 kubernetes 平台
- 应用之间采用的是 gRPC 通讯框架
- API 网关也迁移到 Istio Gateway
- 公司至少预备一个专人维护 Istio(这里的维护不一定是对代码的了解,但一定要对 Istio 本身的功能和文档足够了解)
除此之外使用 SpringCloud、Dubbo、kratos、go-zero之类的微服务框架也未尝不可。
我之前有写过两篇关于 Istio 的 文章,也可以用做参考:
可观测性 现如今可观测系统也变得越来越重要,个人觉得评价一个技术团队重要指标就是他们的可观测系统做的如何。
现如今可观测系统也变得越来越重要,个人觉得评价一个技术团队重要指标就是他们的可观测系统做的如何。
一个优秀的可观测系统可以清晰得知系统的运行状态、高效的排查问题、还有及时的故障告警。
要实现上述标准就需要我们可观测系统的三个核心指标了:
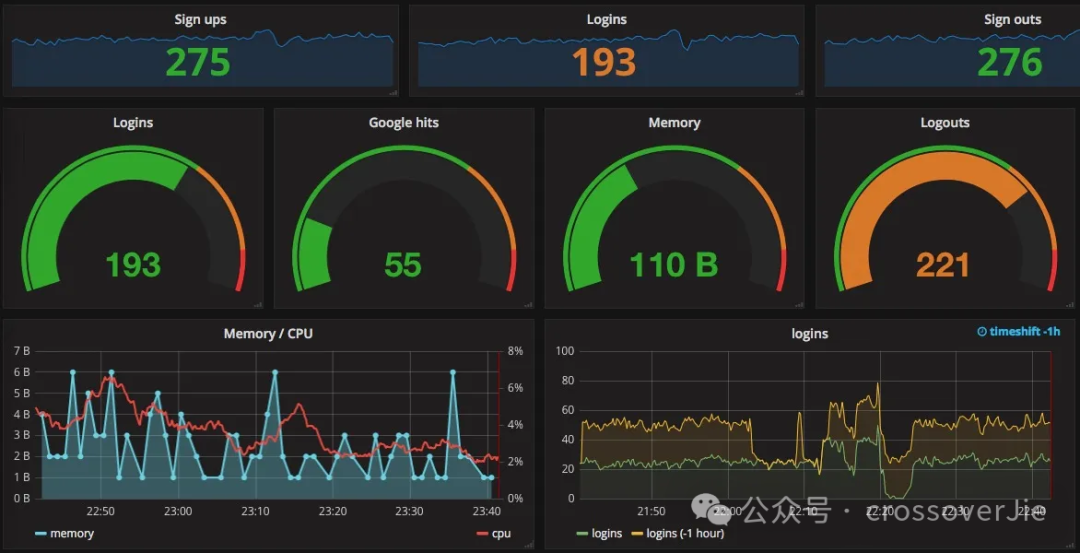
- Metrics,借助它我们可以在 Grafana 中绘制出各种直观的面板,可以更加全面的了解我们系统的运行状态

- Trace则是可以帮助我们构建出系统调用的全貌,通过一个 trace 就可以知道一个请求经历了哪些系统,在哪个环节出了问题。
- Logs 就比较好理解了,就是我们自己在应用里打印的一些日志;只是和以往的开发模式略有不同的是:在云原生体系中更推荐直接输出到标准输出和标准错误流中,一些第三方采集组件可以更方便的进行采集。
我们自己的可观测系统经历过一次迭代,以往的技术栈是:
-
Metrics使用VictoriaMetrics:这是一个完全兼容Prometheus的时序数据库,但相对Prometheus来说更加的节省资源。 -
Trace 选择的是
SkyWalking,这也是 Java trace 领域比较流行的技术方案。 - Logs:使用 filebeat 采集日志然后输出到 ElasticSearch 中,这也是比较经典的方案。
去年底我们做了一次比较大的改造,主要就是将 SkyWalking 换为了 OpenTelemetry,这是一个更加开放的社区,也逐渐成为云原生可观测的标准了。
使用它我们的灵活性更高,不用与某些具体的技术栈进行绑定;目前 logs 还没有切换,社区也还在 beta 测试中,后续成熟后也可以直接用 OpenTelemetry 来收集日志。
我也写的有一篇 SW 迁移到 OpenTelemetry 的文章,感兴趣的朋友可以参考:
这里单独把消息队列拎出来是因为我目前主要是在维护公司内部的消息队列,同时业务体量大了之后消息队列变得非常重要了,通常会充当各个业务线对接的桥梁,或者是数据库同步 MySQL 的渠道,总之用处非常广泛。
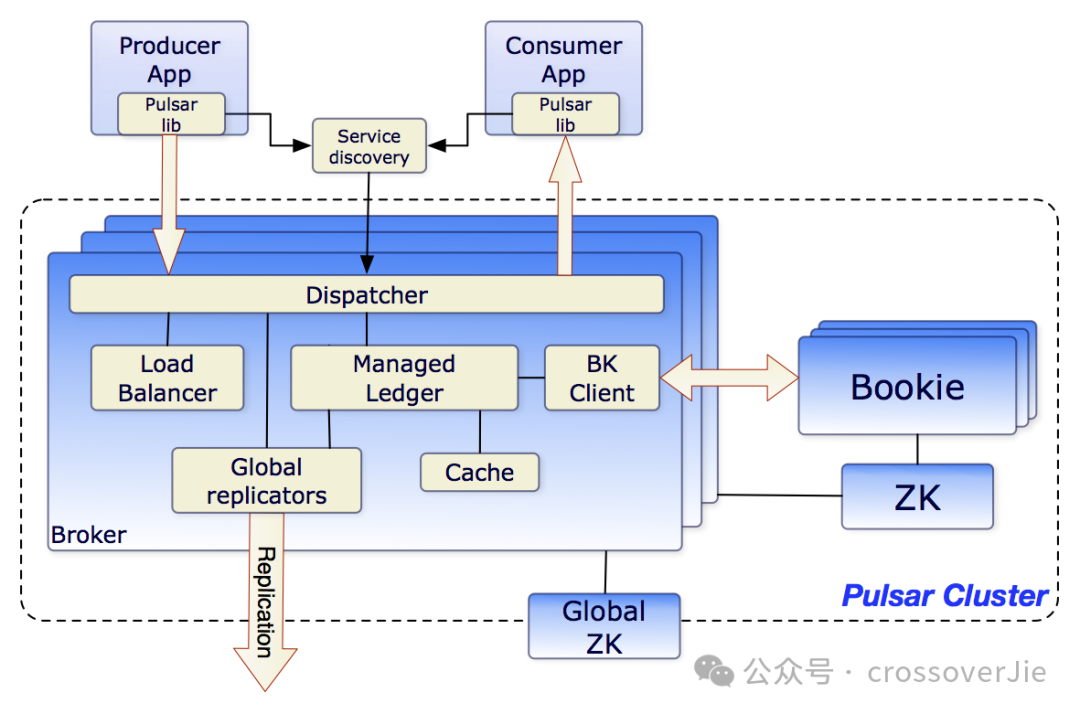
这里还是推荐更贴合云原生的消息队列 Pulsar,由于它存算分离的架构特性,配合kubernetes 的特性可以实现快速的扩缩容,相比 kafka 来说更易维护;同时社区活跃度也非常高,在 Bug 修复和支持新特性方面比较积极。
Pulsar官方支持的客户端也比较全面:
| Language | Documentation | Release note | Code repo |
|---|---|---|---|
| Java | User doc API doc |
Standalone | Bundled |
| C++ | User doc API doc |
Standalone | Standalone |
| Python | User doc API doc |
Standalone | Standalone |
| Go client | User doc API doc |
Standalone | Standalone |
| Node.js | User doc API doc |
Standalone | Standalone |
| C#/DotPulsar | User doc | Standalone | Standalone |
还有一个问题是:如何部署我们的 Pulsar 集群,是私有化部署还是购买云服务(目前 Pulsar的商业公司 streamnative 和国内的腾讯云都有类似的服务)
我们之前有咨询过价格,相对来说还是自己部署性价比最高;和前文讲的一样,只使用云厂商的 kubernetes 服务,在这基础上部署我们的自己的服务。
因为得益于 Pulsar 社区的活跃,即便是自己维护出现问题也可以及时得到反馈;同时自己平时踩的坑也可以反哺社区。
之前也写过一些关于 Pulsar 的系列文章,感兴趣的可以查阅:
- 在 kubernetes 环境下如何优雅扩缩容 Pulsar
- Pulsar3.0新功能介绍
- Pulsar负载均衡原理及优化
- 白话 Pulsar Bookkeeper 的存储模型
- Pulsar压测及优化
最后是业务框架的选择,决定这个的前提是我们先要确定选择哪个语言作为主力业务语言。
虽然这点对于 kubernetes 来说无关紧要,下面以我比较熟悉的 Java 和 Golang 进行介绍。
Java
Java 可选的技术方案就比较多了,如果我们只是上了 kubernetes 但没有使用服务网格;那完全可以只使用 springboot 开发 http 接口,就和开发一个单体应用一样简单。
只是这样会缺少一些服务治理的能力,更适用于中小型团队。
如果团队人员较多,也没使用服务网格时;那就推荐使用前文介绍的微服务框架:比如 Dubbo、SpringCloud 等。
当有专门的云原生团队时,则更推荐使用服务网格的方案,这样我们就能综合以上两种方案的优点:
- 代码简洁,只是需要将 http 换为 gRPC。
- 同时利用 Istio 也包含了微服务框架的能力。
Golang
Golang 其实也与 Java 类似,中小团队时我们完全可以只使用 Gin 这类 http 框架进行开发。
而中大型团队在 Golang 生态中也有对标 Dubbo 和 SpringCloud 的框架,比如 kratos和 go-zero 等。
得益于 Golang 的简洁特性,我觉得比使用 Java 开发业务更加简单和“无脑”。
同样的后续也可以切换到服务网格,直接采用 gRPC 和 Golang 也非常适配,此时团队应该也比较成熟了,完全可以自己基于 gRPC 做一个开发脚手架,或者也可以使用 Kratos 或者是 go-zero 去掉他们的服务调用模块即可。
总结以上就是个人对目前流行的技术方案的理解,也分别对不同团队规模进行了推荐;确实没有完美的技术方案,只有最合适的,也不要跟风选择一些自己不能把控的技术栈,最终吃亏的可能就是自己。
参考链接:
- https://levelup.gitconnected.com/gitops-in-kubernetes-with-gitlab-ci-and-argocd-9e20b5d3b55b
- https://grpc.io/
往期推荐
实战:如何优雅的从 Skywalking 切换到 OpenTelemetry
在 kubernetes 环境下如何优雅扩缩容 Pulsar

点分享

点收藏

点点赞

点在看

