 业余草
业余草




来源:juejin.cn/post/6844904122932690958
推荐:https ://t.zsxq.com/cYxgg
前言
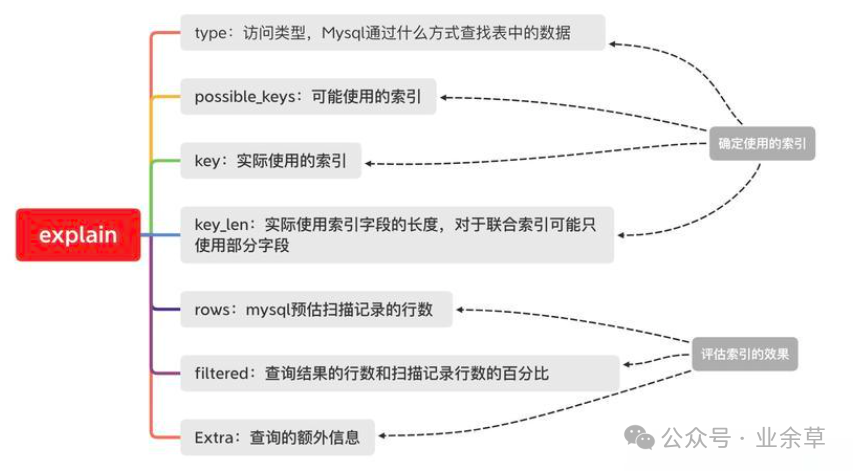
衡量一个SQL语句的表现的方式,大家都知道使用EXPLAIN语句,字段想必大家也知道,但是通过实例我觉得还是更好理解。本文不会对每个字段进行过多地赘述,网上很多大神比我总结得好。本文基于LIKE与正则表达式的实例在EXPLAIN的表现。
-
在分析SQL语句执行时,主要用到的列,分别为
type、Extra,下文的测试用例均为官网提供的sakila数据库,附上下载链接https://dev.mysql.com/doc/index-other.html。 -
film表的情况如下,其实只需要idx_title索引:

- MySQL版本为:8.0+
实例及分析
-
场景:根据
title来匹配相应的电影,从最简单的=开始。 -
注:作为innodb引擎是一个衡量效率的指标,
rows有可能不准确https://dev.mysql.com/doc/refman/8.0/en/explain-output.html。 -
filtered:The filtered column indicates an estimated percentage of table rows that will be filtered by the table condition.The maximum value is 100, which means no filtering of rows occurred. Values decreasing from 100 indicate increasing amounts of filtering. rows shows the estimated number of rows examined and rows × filtered shows the number of rows that will be joined with the following table. For example, if rows is 1000 and filtered is 50.00 (50%), the number of rows to be joined with the following table is 1000 × 50% = 500.
❝译文:是一个多少行会被表条件过滤的百分比估计值,一般与
rows列结合着看,filtered × rows就是被表条件过滤掉的行数。
=
explain select title from film where title= 'ACE GOLDFINGER';
-
结果及分析:索引等于一个常量值,
type为ref,使用的key为idx_title,实际使用索引与'ACE GOLDFINGER'比较(即ref=CONST,由于使用索引查找与常量匹配(读取的行数rows为1),由于是使用覆盖索引,没有回表获取数据行,Extra就是Using index。
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | film | NULL | ref | idx_title | idx_title | 767 | const | 1 | 100.00 | Using index |
explain select * from film where title= 'ACE GOLDFINGER';
-
结果及分析:唯一区别,由于需要回表查询其他字段,就不是覆盖索引了,
Extra就是NULL。
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | film | NULL | ref | idx_title | idx_title | 767 | const | 1 | 100.00 | NULL |
LIKE
-
大家都知道有前缀索引这一说,
LIKE语句的关键之一就在于%位置,就分析下以下4种情况。
%不在前面
explain select title from film where title LIKE 'A%';
-
结果及分析:这里需要注意的是
type和Extra:
1、type:这里把LIKE当成了一个有限制的索引扫描, 不用遍历所有索引,例如,索引BETWEEN 1 AND 100的效果。
2、读取了46行数据
3、Extra:Using where; Using index这两个值同时在一起,到底是什么意思呢?先卖个关子,后续详细说~
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | film | NULL | range | idx_title | idx_title | 767 | NULL | 46 | 100.00 | Using where; Using index |
explain select * from film where title LIKE 'A%';
-
结果及分析:又出现了一个新的
Extra:Using index condition,后面详细说,其他字段倒和前一个语句没区别
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | film | NULL | range | idx_title | idx_title | 767 | NULL | 46 | 100.00 | Using index condition |
%在前面
explain select title from film where title LIKE '%A';
结果及分析:
1、首先,不是有限的索引查找,而是使用索引查询全表,所以type是index。2、读取了1000行,过滤了1000 * 11.11的行数。
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | film | NULL | index | null | idx_title | 767 | NULL | 1000 | 11.11 | Using where; Using index |
explain select * from film where title LIKE '%A';
- 结果及分析:
1、没有使用索引,全表扫描,按照条件过滤。2、Using where:存储引擎检索行后,MySQL server再进行过滤后返回(出自高性能MySQL,附录D EXPLAIN)。
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | film | NULL | ALL | null | null | null | NULL | 1000 | 11.11 | Using where |
REGEXP
explain select title from film where title REGEXP '^A';
- 结果及分析:正则表达式查询使用了索引全表扫描,没有被表条件过滤的行。
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | film | NULL | INDEX | null | idx_title | 767 | NULL | 1000 | 100 | Using where; Using index |
explain select * from film where title REGEXP '^A';
- 结果及分析:没有使用到索引,全表扫描。
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | film | NULL | ALL | null | null | null | NULL | 1000 | 100 | Using where |
两种情况分析
Using where; Using index 与 Using index condition
- 这里,我参考了官网,然后添加了自己的一些分析,欢迎大家纠错。
-
Using where; Using index:简单来讲,我们可以分开来看,Using where就是 MySQL Server 在存储引擎检索行后,再过滤。Using index就是覆盖索引查询,不需要回表获取行数据。加起来就是:使用覆盖索引检索行后,在MySQL Server进行过滤。
❝Bonus:you may have something wrong in your query if the Extra value is not Using where and the table join type is ALL or index. 译文:如果type为ALL或index,但是Extra不是Using where时,查询语句或许有问题。
-
Using index Condition:官方文档说这个与Index Condition Pushdown Optimization有关,官网简称为ICP,在InnoDB以及MyISAM都可以使用,这里我截取InnoDB关键信息。
1、使用场景:the case where MySQL retrieves rows from a table using an index,索引检索行时使用type为ref、range、index时使用,仅用于range、ref、eq_ref、ref_or_null。
2、背景:Without ICP, the storage engine traverses the index to locate rows in the base table and returns them to the MySQL server which evaluates the WHERE condition for the rows,没有ICP,存储引擎遍历索引检索出行,返回到MySQL Server层进行WHERE条件过滤(眼熟有没有,using where)。
3、原理:With ICP enabled, and if parts of the WHERE condition can be evaluated by using only columns from the index, the MySQL server pushes this part of the WHERE condition down to the storage engine,如果WHERE条件或者其部分,仅使用索引中的列,MySQL server可以将这部分的WHERE子句交给存储引擎处理。(由于交给存储引擎,就是pushdown了 。。。)
4、作用:For InnoDB tables, ICP is used only for secondary indexes. The goal of ICP is to reduce the number of full-row reads and thereby reduce I/O operations. For InnoDB clustered indexes, the complete record is already read into the InnoDB buffer. Using ICP in this case does not reduce I/O,仅可以在二级索引使用,减少回表获取行数据次数,减少MySQL server与存储引擎之间的I/O操作,聚簇索引由于整条数据已经加载进InnoDB 缓冲区了,没有减少I/O操作。
- 其他信息:
1、ICP is used for the range, ref, eq_ref, and ref_or_null access methods when there is a need to access full table rows,仅用于range、ref、eq_ref、ref_or_null的type,且需要回表获取行数据的情况。
2、其他信息,请参考官网https://dev.mysql.com/doc/refman/8.0/en/index-condition-pushdown-optimization.html
- 这就可以解释上述结果:
1、explain select * from film where title LIKE 'A%'; range且需要回表
2、explain select title from film where title LIKE 'A%';不需要回表,没启动ICP
3、explain select title from film where title LIKE '%A'; index,没法用ICP
-
如何开启关闭
ICP:
❝SET optimizer_switch = 'index_condition_pushdown=off'; SET optimizer_switch = 'index_condition_pushdown=on';
- 关闭ICP后运行explain select * from film where title LIKE 'A%':
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | film | NULL | range | idx_title | idx_title | 767 | NULL | 46 | 100.00 | Using where |
结论(在InnoDB中):ICP是一种MySQL针对二级索引在range、ref、eq_ref、ref_or_null数据访问类型且不是覆盖索引(Using index)的一个优化机制,将MySQL server中进行的行数据过滤(二级索引可处理的)下推(push down)到存储引擎处理,减少回表读取行数据的次数,减少MySQL server与存储引擎之间的I/O操作。
小结
本文从实例运行EXPLAIN出发,简单介绍了ICP,并对容易疏忽的LIKE以及正则表达式的结果进行了介绍。
后续,会尽量保持援引官网或者书里的资料,并结合实例分析,希望对大家有所帮助,也欢迎纠错~
参考文章
-
https://dev.mysql.com/doc/refman/8.0/en/explain-output.html - 高性能MySQL

