 crossoverJie
crossoverJie




前两天在推送中看到一条新闻:Stack Overflow Upset Over Users Deleting Answers After OpenAI Partnership。
简单来说就是 SF 与 OpenAI 建立了合作关系,会使用用户的提问以及回答来训练大模型,好处自然是提高开发者使用 OpenAI 的体验。
但用户会担心他们的数据被拿来作为训练后并不会标明出处。
同时数据都由 AI 进行检索后使得个人网站、博客等流量下降。
于是有部分用户开始尝试删除自己的问题或答案,甚至估计修改内容从而想污染 AI 采集到的数据。
现在 SF 发布了公告,对大量删除数据的账号进行了账户限制🚫。
现在互联网上越来越多的都是由 AI 生成的,今后也许会有一些搜索引擎会打上”内容纯人工生成“的标签。
不知道现在大家查问题是更多使用 SF 还是直接问 AI?
以下是一些节选的原文:

在这个用户生成和 AI 生成内容不断发展的世界中,最近 stack overflow 和 OpenAI 的合作遭到了社区的强烈反对。
今天有报告称许多用户尝试删除他们 SF 社区里的内容会有困难,因为 SF 社区不允许这些内容被轻易删除。
因此有些用户决定修改他们的问题或者答案来“污染”这些内容。
While Stack Overflow, and other Stack Exchange websites, are amazingly useful tools for the communities they serve, there are users who are not too excited about their content being used to train AI that will then offer their answers without attribution. This is actually a common reaction today by many of the authors of content across the Internet, not just content posted to Stack Overflow.
SF 和 SE 都是很棒的社区,但是用户对他们的内容被拿来训练 AI 但是并不标明出处表示不满,在如今这实际上是一个如今互联网上许多作者的普遍反应,不仅仅是在 SF 上的内容而已。
stack overflow 的公告: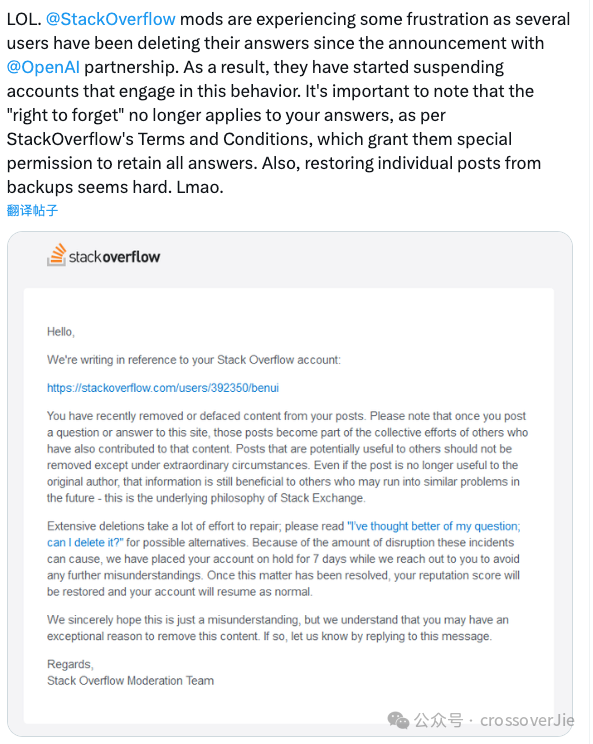
参考链接:
- https://build5nines.com/stack-overflow-upset-over-users-deleting-answers-after-openai-partnership/s
往期推荐
实操 OpenTelemetry:通过 Demo 掌握微服务监控的艺术
OpenTelemetry agent 对 Spring Boot 应用的影响:一次 SPI 失效的调查
自动化测试在 Kubernetes Operator 开发中的应用:以 OpenTelemetry
深入剖析:如何使用Pulsar和Arthas高效排查消息队列延迟问题

点分享

点收藏

点点赞

点在看

