 沉默王二
沉默王二




大家好,我是二哥呀。
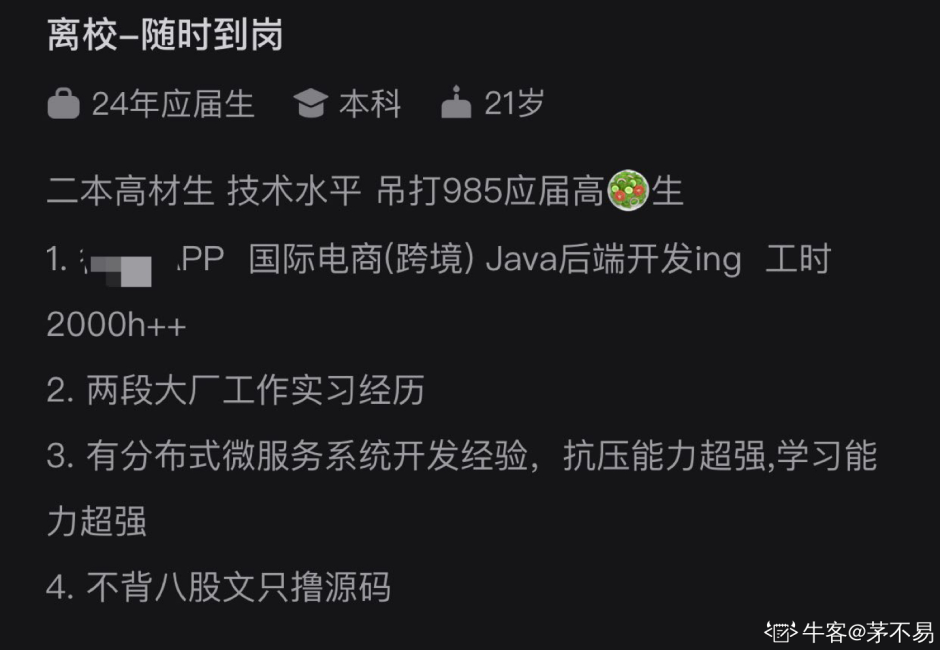
在牛客上看到,一个民办三本的同学把自己的简历改成了下面这样后,连续 OC 两个,甚至一个月前投递的简历 HR 也开始重新联系了。
 图片来源:牛客茅不易
图片来源:牛客茅不易不管大家信不信,反正我信了。这样的描述至少看起来比那些光秃秃的,充满着自卑的强多了。
- 技术吊打 985
- 有实习经历
- 懂分布式
- 超级抗压
- 不背八股只撸源码
这是多少 HR 喜欢看到的一副“自信爆棚”的 diao 样子,反正我就喜欢这样的,与其自卑获取别人的同情,不如自信赢得别人的青睐。
形成鲜明对比的就是,一位球友,学历还很不错,可能是被暑期实习拷打得失去自信了,连续失眠,学不进去,处于一种焦虑、怀疑、煎熬的状态,我好想安慰他,但这个世界上,没有人会因为同情而给你发 offer 的呀。
 球友被暑期实习拷打麻了
球友被暑期实习拷打麻了emo 了,打一把游戏、玩一次篮球、看一场电影、聚一次餐,歇斯底里地嗨一次,把负面的情绪全部排解掉,然后开始新一轮的学习。
无论是暑期实习还是即将到来的秋招提前批,准备的东西不外乎这几样,简历、算法、八股、项目,还有什么,没有了吧?
简历是为了获取笔试和面试邀请,算法是为了过笔试,八股是为了应对大多数的面试题,除此之外,就是围绕着项目展开的提问,内核其实还是一些八股,只要自己能够串联业务场景和面试官有来有回就好了。
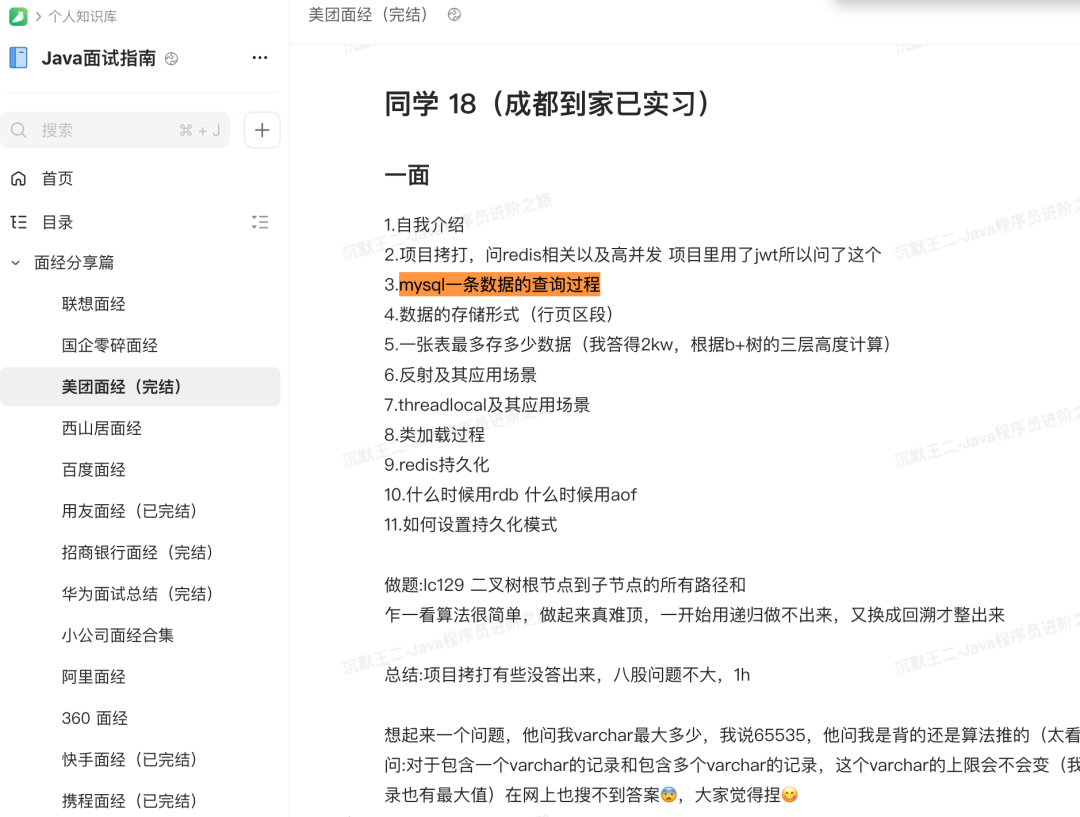
这次我们就以《二哥的 Java 面试指南-美团面经》同学 18 为例, 来看看大厂的面试官都喜欢问哪些问题,好做到知彼知己百战不殆~
 让天下所有的面渣都能逆袭 😁
让天下所有的面渣都能逆袭 😁能看得出,仍然是围绕着二哥一直强调的 Java 后端四大件展开,所以大家在学习的时候一定要有的放矢,效率就会高很多。
- 1、二哥的 Linux 速查备忘手册.pdf 下载
- 2、三分恶面渣逆袭在线版:https://javabetter.cn/sidebar/sanfene/nixi.html
美团面经(经得起拷打)
mysql一条数据的查询过程
 二哥的 Java 进阶之路:SQL 执行
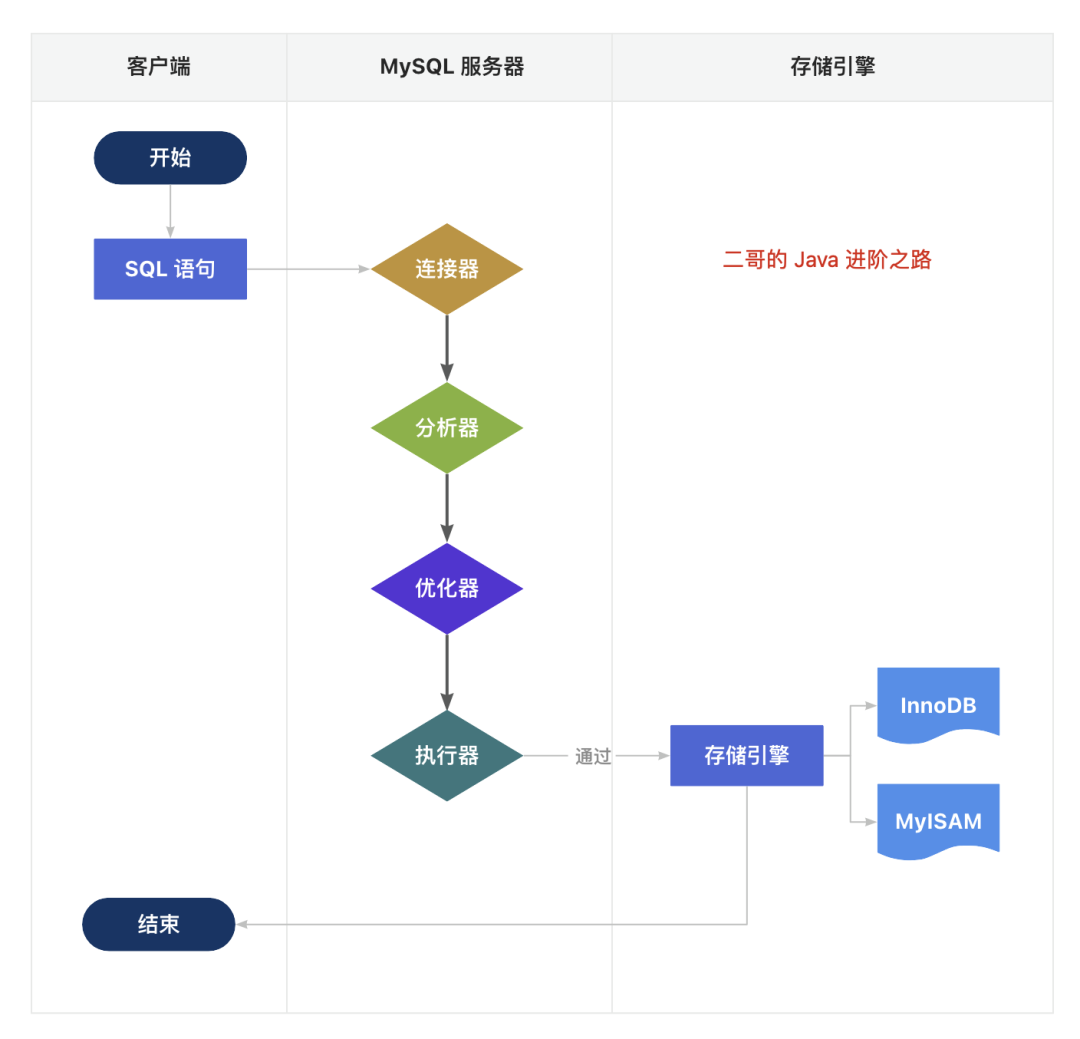
二哥的 Java 进阶之路:SQL 执行第一步,客户端发送 SQL 查询语句到 MySQL 服务器。
第二步,MySQL 服务器的连接器开始处理这个请求,跟客户端建立连接、获取权限、管理连接。
第三步(MySQL 8.0 以后已经干掉了),连接建立后,MySQL 服务器的查询缓存组件会检查是否有缓存的查询结果。如果有,直接返回给客户端;如果没有,进入下一步。
第三步,解析器开始对 SQL 语句进行解析,检查语句是否符合 SQL 语法规则,确保引用的数据库、表和列都存在,并处理 SQL 语句中的名称解析和权限验证。
第四步,优化器负责确定 SQL 语句的执行计划,这包括选择使用哪些索引,以及决定表之间的连接顺序等。优化器会尝试找出最高效的方式来执行查询。
第五步,执行器会调用存储引擎的 API 来进行数据的读写。
第六步,MySQL 的存储引擎是插件式的,不同的存储引擎在细节上面有很大不同。例如,InnoDB 是支持事务的,而 MyISAM 是不支持的。之后,会将执行结果返回给客户端
第七步,客户端接收到查询结果,完成这次查询请求。
数据的存储形式(行页区段)
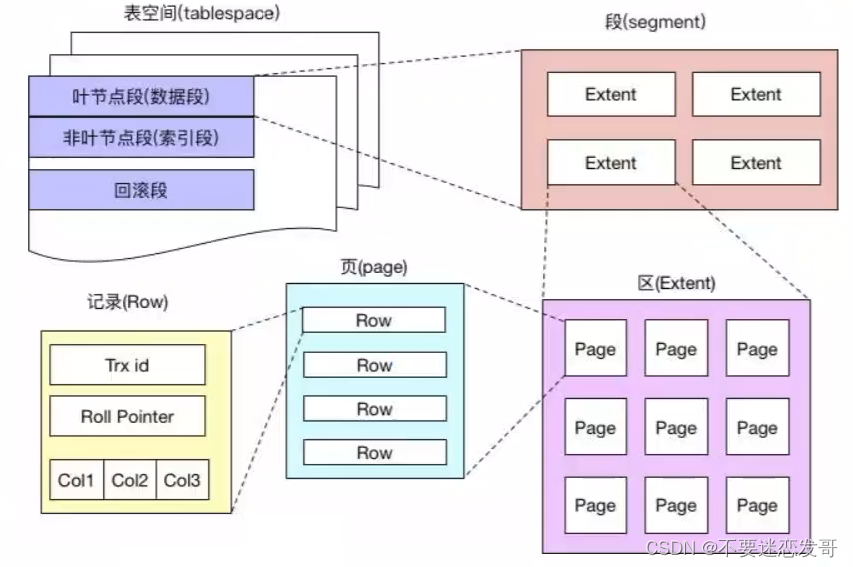
MySQL 是以表的形式存储数据的,而表空间的结构则由段、区、页、行组成。
 不要迷恋发哥:段、区、页、行
不要迷恋发哥:段、区、页、行①、段(Segment):表空间由多个段组成,常见的段有数据段、索引段、回滚段等。
创建索引时会创建两个段,数据段和索引段,数据段用来存储叶子阶段中的数据;索引段用来存储非叶子节点的数据。
回滚段包含了事务执行过程中用于数据回滚的旧数据。
②、区(Extent):段由一个或多个区组成,区是一组连续的页,通常包含 64 个连续的页,也就是 1M 的数据。
使用区而非单独的页进行数据分配可以优化磁盘操作,减少磁盘寻道时间,特别是在大量数据进行读写时。
③、页(Page):页是 InnoDB 存储数据的基本单元,标准大小为 16 KB,索引树上的一个节点就是一个页。
也就意味着数据库每次读写都是以 16 KB 为单位的,一次最少从磁盘中读取 16KB 的数据到内存,一次最少写入 16KB 的数据到磁盘。
④、行(Row):InnoDB 采用行存储方式,意味着数据按照行进行组织和管理,行数据可能有多个格式,比如说 COMPACT、REDUNDANT、DYNAMIC 等。
MySQL 8.0 默认的行格式是 DYNAMIC,由COMPACT 演变而来,意味着这些数据如果超过了页内联存储的限制,则会被存储在溢出页中。
可以通过 show table status like '%article%' 查看行格式。
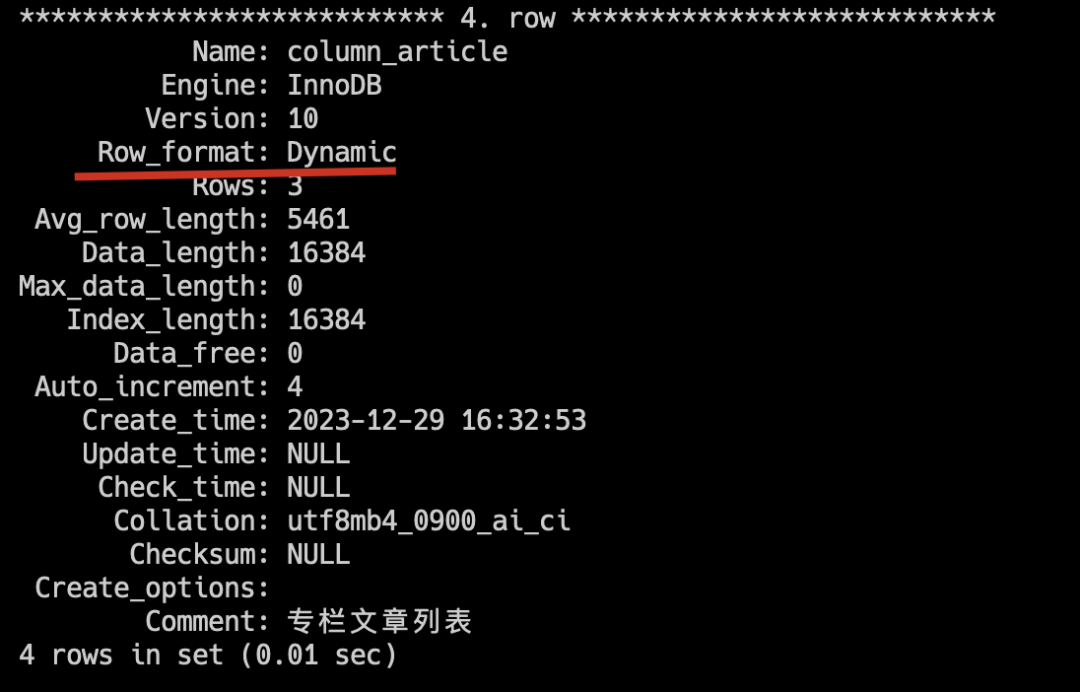 二哥的 Java 进阶之路:行格式
二哥的 Java 进阶之路:行格式一张表最多存多少数据(我答得2kw,根据b+树的三层高度计算)
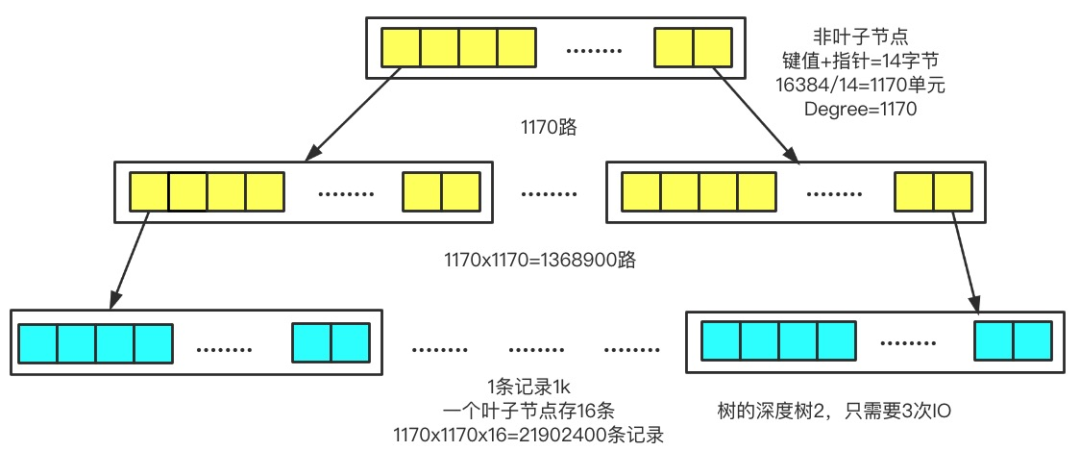 三分恶面渣逆袭:B+树存储数据条数
三分恶面渣逆袭:B+树存储数据条数可以通过 B+树来进行推算。
假如我们的主键 ID 是 bigint 类型,长度为 8 个字节。指针大小在 InnoDB 源码中设置为 6 字节,这样一共 14 字节。所以非叶子节点(一页)可以存储 16384/14=1170 个这样的单元(键值+指针)。
一个指针指向一个存放记录的页,一页可以放 16 条数据,树深度为 2 的时候,可以存放 1170*16=18720 条数据。
同理,树深度为 3 的时候,可以存储的数据为 1170*1170*16=21902400条记录。
理论上,在 InnoDB 存储引擎中,B+树的高度一般为 2-4 层,就可以满足千万级数据的存储。查找数据的时候,一次页的查找代表一次 IO,当我们通过主键索引查询的时候,最多只需要 2-4 次 IO 就可以了。
反射及其应用场景
创建一个对象是通过 new 关键字来实现的,比如:
Person person = new Person();
Person 类的信息在编译时就确定了,那假如在编译期无法确定类的信息,但又想在运行时获取类的信息、创建类的实例、调用类的方法,这时候就要用到反射。
反射功能主要通过 java.lang.Class 类及 java.lang.reflect 包中的类如 Method, Field, Constructor 等来实现。
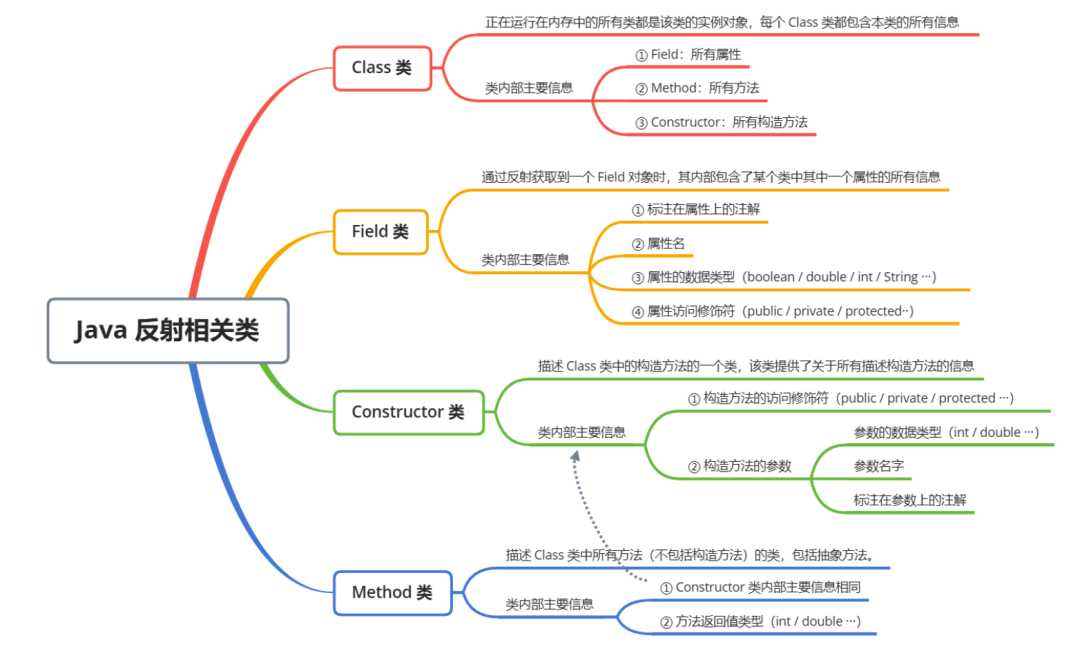 三分恶面渣逆袭:Java反射相关类
三分恶面渣逆袭:Java反射相关类反射有哪些应用场景?
一般我们平时都是在在写业务代码,很少会接触到直接使用反射机制的场景。
但是,这并不代表反射没有用。相反,正是因为反射,你才能这么轻松地使用各种框架。像 Spring/Spring Boot、MyBatis 等等框架中都大量使用了反射机制。
像 Spring 里的很多 注解 ,它真正的功能实现就是利用反射。
就像为什么我们使用 Spring 的时候 ,一个@Component注解就声明了一个类为 Spring Bean 呢?为什么通过一个 @Value注解就读取到配置文件中的值呢?究竟是怎么起作用的呢?
这些都是因为我们可以基于反射操作类,然后获取到类/属性/方法/方法的参数上的注解,注解这里就有两个作用,一是标记,我们对注解标记的类/属性/方法进行对应的处理;二是注解本身有一些信息,可以参与到处理的逻辑中。
threadlocal及其应用场景
ThreadLocal 是 Java 中提供的一种用于实现线程局部变量的工具类。它允许每个线程都拥有自己的独立副本,从而实现线程隔离,用于解决多线程中共享对象的线程安全问题。
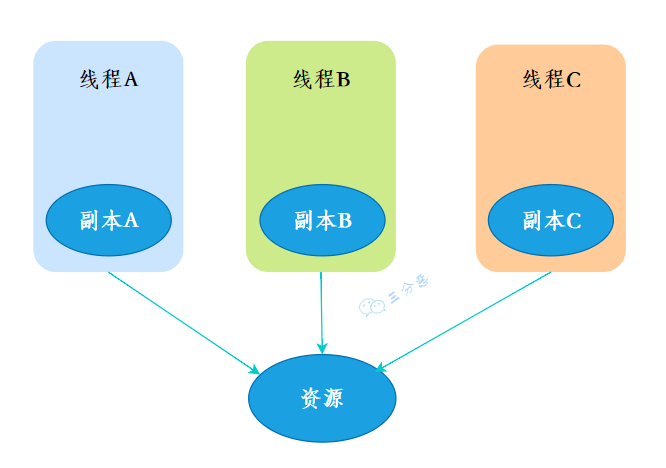 三分恶面渣逆袭:ThreadLocal线程副本
三分恶面渣逆袭:ThreadLocal线程副本类加载过程
类加载过程有:载入、验证、准备、解析、初始化。这 5 个阶段一般是顺序发生的,但在动态绑定的情况下,解析阶段会发生在初始化阶段之后。
载入过程中,JVM 需要做三件事情:
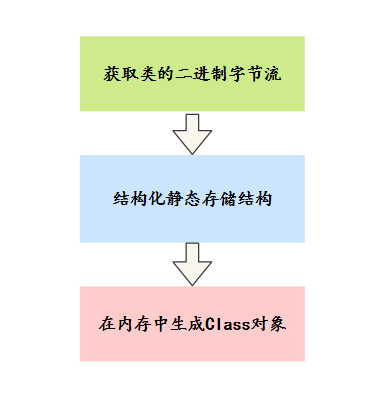 三分恶面渣逆袭:载入
三分恶面渣逆袭:载入- 1)通过一个类的全限定名来获取定义此类的二进制字节流。
- 2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
-
3)在内存中生成一个代表这个类的
java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
载入阶段结束后,JVM 外部的二进制字节流就按照虚拟机所设定的格式存储在方法区(逻辑概念)中了,方法区中的数据存储格式完全由虚拟机自行实现。
JVM 会在验证阶段对二进制字节流进行校验,只有符合 JVM 字节码规范的才能被 JVM 正确执行。
JVM 会在准备阶段对类变量(也称为静态变量,static 关键字修饰的变量)分配内存并初始化,初始化为数据类型的默认值,如 0、0L、null、false 等。
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、成员方法等。
初始化阶段是类加载过程的最后一步。在准备阶段,类变量已经被赋过默认初始值了,而在初始化阶段,类变量将被赋值为代码期望赋的值。
换句话说,初始化阶段是执行类的构造方法(javap 中看到的 <clinit>() 方法)的过程。
redis持久化
Redis 支持两种主要的持久化方式:RDB(Redis DataBase)持久化和 AOF(Append Only File)持久化。这两种方式可以单独使用,也可以同时使用。
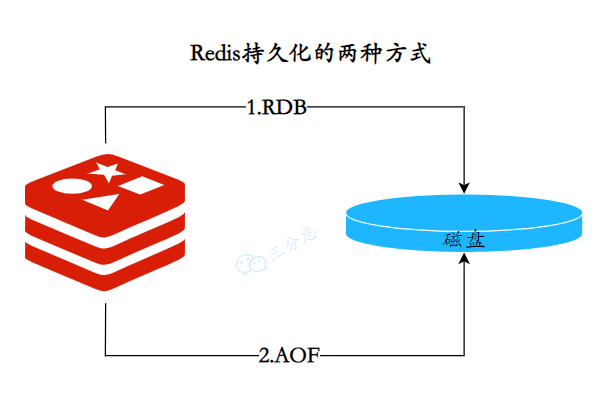 三分恶面渣逆袭:Redis持久化的两种方式
三分恶面渣逆袭:Redis持久化的两种方式什么时候用rdb 什么时候用aof
如果需要尽可能减少数据丢失,AOF 是更好的选择。尤其是在频繁写入的环境下,设置 AOF 每秒同步可以最大限度减少数据丢失。
如果性能是首要考虑,RDB 可能更适合。RDB 的快照生成通常对性能影响较小,并且数据恢复速度快。
如果系统需要经常重启,并且希望系统重启后快速恢复,RDB 可能是更好的选择。虽然 AOF 也提供了良好的恢复能力,但重写 AOF 文件可能会比较慢。
在许多生产环境中,同时启用 RDB 和 AOF 被认为是最佳实践:
- 使用 RDB 进行快照备份。
- 使用 AOF 保证崩溃后的最大数据完整性。
如何设置持久化模式
可以通过编辑 Redis 的配置文件 redis.conf 来进行设置,或者在运行时通过 Redis 命令行动态调整。
RDB 持久化通过在配置文件中设置快照(snapshotting)规则来启用。这些规则定义了在多少秒内如果有多少个键被修改,则自动执行一次持久化操作。
save 900 1 # 如果至少有1个键被修改,900秒后自动保存一次
save 300 10 # 如果至少有10个键被修改,300秒后自动保存一次
save 60 10000 # 如果至少有10000个键被修改,60秒后自动保存一次
AOF 持久化是通过在配置文件中设置 appendonly 参数为 yes 来启用的:
appendonly yes
此外,还可以配置 AOF 文件的写入频率,这是通过 appendfsync 设置的:
appendfsync always # 每次写入数据都同步,保证数据不丢失,但性能较低
appendfsync everysec # 每秒同步一次,折衷方案
appendfsync no # 由操作系统决定何时同步,性能最好,但数据安全性最低
为了优化 AOF 文件的大小,Redis 允许自动或手动重写 AOF 文件。可以在配置文件中设置重写的触发条件:
auto-aof-rewrite-percentage 100 # 增长到原大小的100%时触发重写
auto-aof-rewrite-min-size 64mb # AOF 文件至少达到64MB时才考虑重写
手动执行 AOF 重写的命令是:
redis-cli bgrewriteaof
如果决定同时使用 RDB 和 AOF,可以在配置文件中同时启用两者。
save 900 1
appendonly yes
还可以在运行时动态更改:
redis-cli config set save "900 1 300 10 60 10000"
redis-cli config set appendonly yes
redis-cli config set appendfsync everysec
参考链接
- 三分恶的面渣逆袭:https://javabetter.cn/sidebar/sanfene/nixi.html
- 二哥的 Java 进阶之路:https://javabetter.cn
ending
一个人可以走得很快,但一群人才能走得更远。二哥的编程星球已经有 5300 多名球友加入了,如果你也需要一个良好的学习环境,戳链接 🔗 加入我们吧。这是一个编程学习指南 + Java 项目实战 + LeetCode 刷题的私密圈子,你可以阅读星球专栏、向二哥提问、帮你制定学习计划、和球友一起打卡成长。

两个置顶帖「球友必看」和「知识图谱」里已经沉淀了非常多优质的学习资源,相信能帮助你走的更快、更稳、更远。
欢迎点击左下角阅读原文了解二哥的编程星球,这可能是你学习求职路上最有含金量的一次点击。

最后,把二哥的座右铭送给大家:没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟。共勉 💪。

