 HBase技术社区
HBase技术社区




1. 背景
随着业务的高速发展,针对HDFS元数据的访问请求量呈指数级上升。在之前的工作中,我们已经通过引入HDFS Federation和Router机制实现NameNode的平行扩容,在一定程度上满足了元数据的扩容需求;也通过引入Observer NameNode读写分离架构提升单组NameSpace的读写能力,在一定程度上减缓了读写压力。但随着业务场景的发展变化,NameSpace数量也在上升至30+组后,Active+Standby+Observer NameNode 的架构已经无法满足所有的元数据读写场景,我们必须考虑提升NameNode读写能力,来应对不断上升的元数据读写要求。
如图1-1 所展示的B站离线存储整体架构所示,随着业务的不断增量发展,通过引入HDFS Router机制实现NameNode的平行扩容,目前NameSpace的数量已经超过30+组,总存储量EB级,每日请求访问量超过200亿次。各个NameSpace之间的读写请求更是分布非常不均衡,在一些特殊场景下,部分NameSpace的整体负载更高。如Flink任务的CheckPoint 场景,Spark和MR任务的log日志上传场景,这两类场景的数据写入要求要远远高于普通场景。此外还有部分数据回刷场景,存在短时间写入请求增加300%以上的情况,极易触发NameNode的写入性能瓶颈,影响其他任务的正常访问。为了应对这个问题,我们针对性的提出了NameNode的读写性能提升方案。
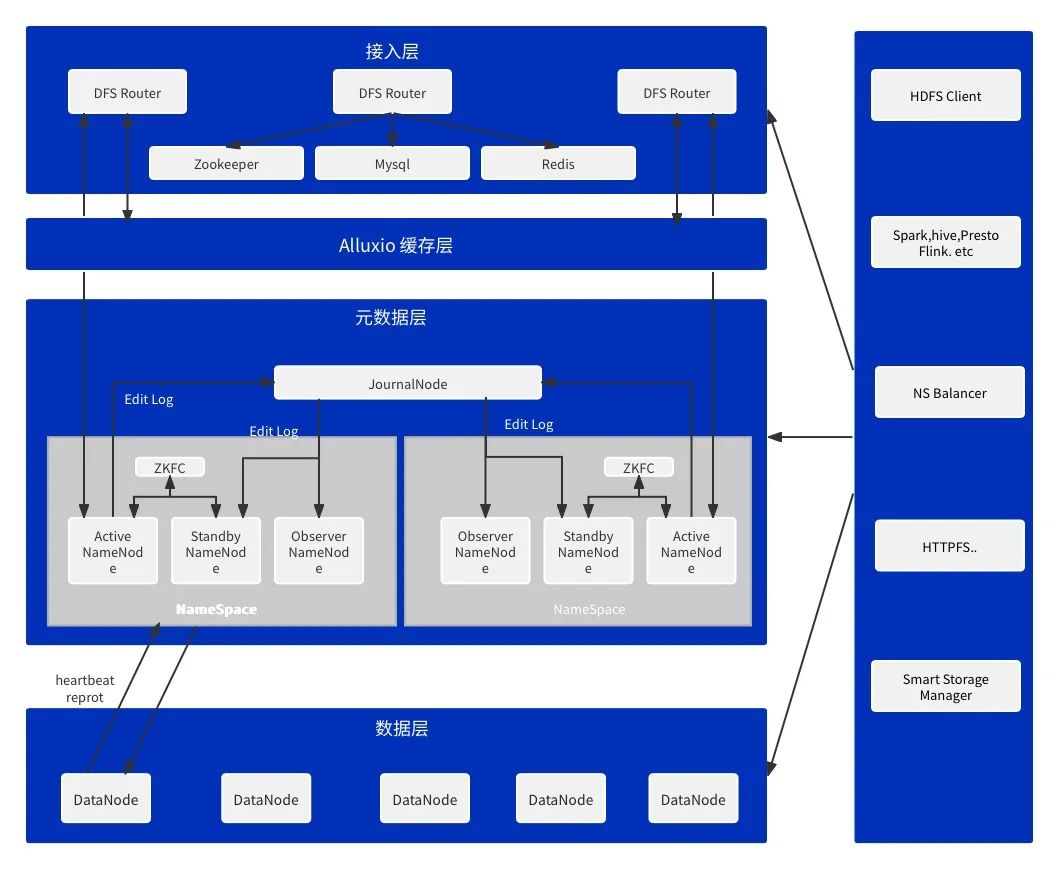
图1-1 B站HDFS整体架构图
2. HDFS 细粒度锁优化整体方案
2.1 面临的问题
NameNode是整个HDFS的核心组件,集中管理HDFS集群的所有元数据,主要包括文件系统的目录树、数据块集合和分布以及整个集群的拓扑结构。HDFS在对NameNode的实现上做了大胆取舍,如图2-1所示,锁机制上使用全局锁来统一来控制并发读写。这样处理的优势非常明显,全局锁进一步简化锁模型,不需要额外考虑锁依赖关系,同时降低复杂度,减少工程量。但是问题比优势更加突出,核心问题就是全局唯一锁制约性能提升。
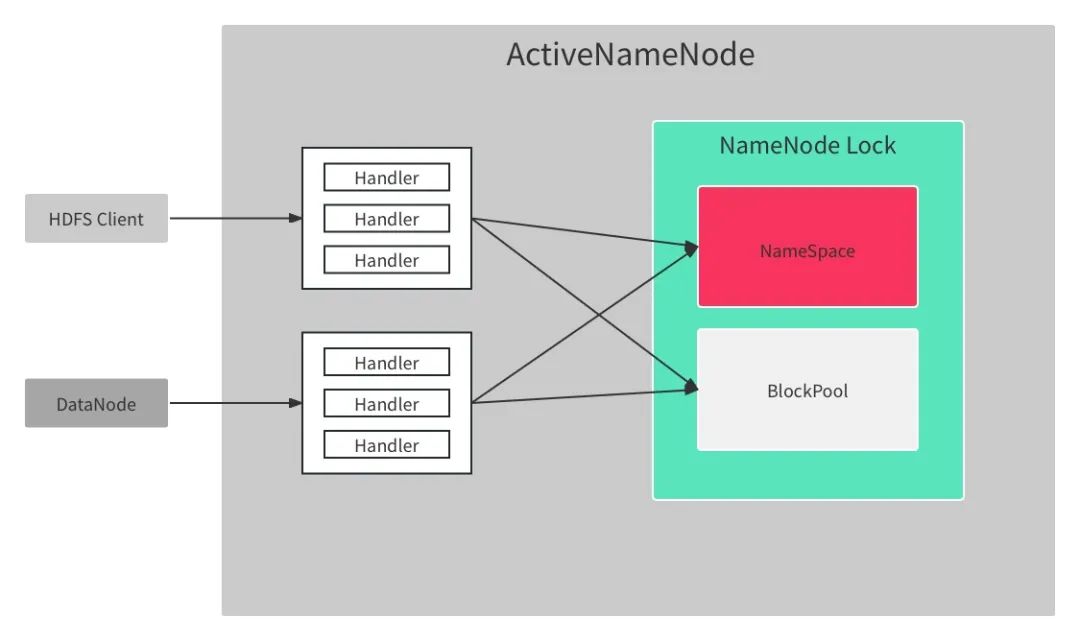
图2-1 B站HDFS整体架构图
在多年的HDFS实践工作中,我们发现NameNode全局唯一的读写锁已经成为NameNode读写性能最大瓶颈之一,社区已经做了很多的工作来优化相关性能,如将一些日志操作异步化,移动日志操作到锁外,针对DU请求采用分段锁,大删除异步化等一系列优化措施,但对于我们这种数据量的HDFS集群来说,仍然难以满足部分生产场景。为了进一步提升HDFS读写性能,满足业务场景,我们计划对全局锁进行细粒度拆分,为此我们也面临着许多困难。
首先是问题复杂度高,Hadoop发展到今天已经超过十年,其中HDFS经过多次迭代演进,架构已经非常复杂。针对NameNode组件来说,架构上模块划分不够清晰,内部核心数据结构和工作线程之间耦合非常严重,实现细节上,还存在大量相互依赖,不一而足。
其次是社区的动力不足,在全局唯一的读写锁的扩展性问题上,社区做过多次尝试,主要就有 HDFS-8966:Separate the lock used in namespace and block management layer 和 HDFS-5453:Support fine grain locking in FSNamesystem 等方面的尝试,但是并没有产出可以进行生产化部署的成果。具体原因还是动力不足,因为NameNode性能针对小规模部署的集群来说大体上已经足够,也有通过Federation和Router机制进行扩展,满足一定的需求。
为了解决这个难题,我们参考了业界的拆锁方案和Alluxio的LockPool实现机制,计划实现针对NameNode全局唯一锁的细粒度拆分。
2.2 设计选型
为了更好地理解使用全局锁存在的问题,首先梳理全局锁管理的主要数据结构,大致分成三类:
-
NameSpace目录树:文件系统的全局目录视图。获取目录树上任一节点的信息必须先拿到全局读锁;目录树上任一节点新增、删除、修改都必须先拿到全局写锁。
-
BlockPool层数据块集合:文件系统的全量数据信息。获取其中任一数据块信息必须先拿到全局读锁;新增、删除,修改都必须先拿到全局写锁。
-
集群信息:HDFS集群节点信息的集合。获取节点信息等必须先拿到全局读锁;注册,下线或者变更节点信息请求处理时必须先拿到全局写锁。
具体实现上,NameNode使用了JDK提供的可重入读写锁(ReentrantReadWriteLock),ReentrantReadWriteLock对并行请求有严格限制,支持读请求并行处理,写请求具有排他性。针对不同RPC请求的处理逻辑,按照需要获取锁粒度,我们可以把所有请求抽象为全局读锁和全局写锁两类。全局读锁包括客户端请求(getListing/getBlockLocations/getFileInfo)、服务管理接口(monitorHealth/getServiceStatus)等;全局写锁则包括客户端写请求(create/mkdir/rename/append/truncate/complete/recoverLease)、服务管理接口(transitionToActive/transitionToStandby/setSafeMode)和主从节点之间请求(rollEditLog)等。在一次RPC处理过程中,如果不能及时获取到锁,这次RPC将处于排队等待状态,直到成功获得锁,锁等待时间直接影响请求响应性能,极端场景下如果长时间不能获得锁,将造成IPC队列堆积,TCP连接队列被打满,客户端出现请求卡住,新建连接超时失败等各种异常问题。从全局来看,写锁因为排它对性能影响更加明显。如果当前有写请求正在被处理,其他所有请求都必须排队等待,直到写请求被处理完成释放锁后再竞争全局锁。因此我们希望对全局锁进行细粒度划分,最终实现NameNode服务的大部分的RPC请求都能并行处理。
我们计划通过3步实现 NameNode 锁的细粒度划分,如图2-2所示。
第一步,将NameNode 全局锁拆分为 Namespace层读写锁和 BlockPool层读写锁;
第二部,将NameSpace读写锁拆成颗粒度更细的Inode层的读写锁;
第三步,将BlockPool层读写锁也拆成更细粒度的读写锁;
目前我们已经基本完成第一部分和第二部分的工作。
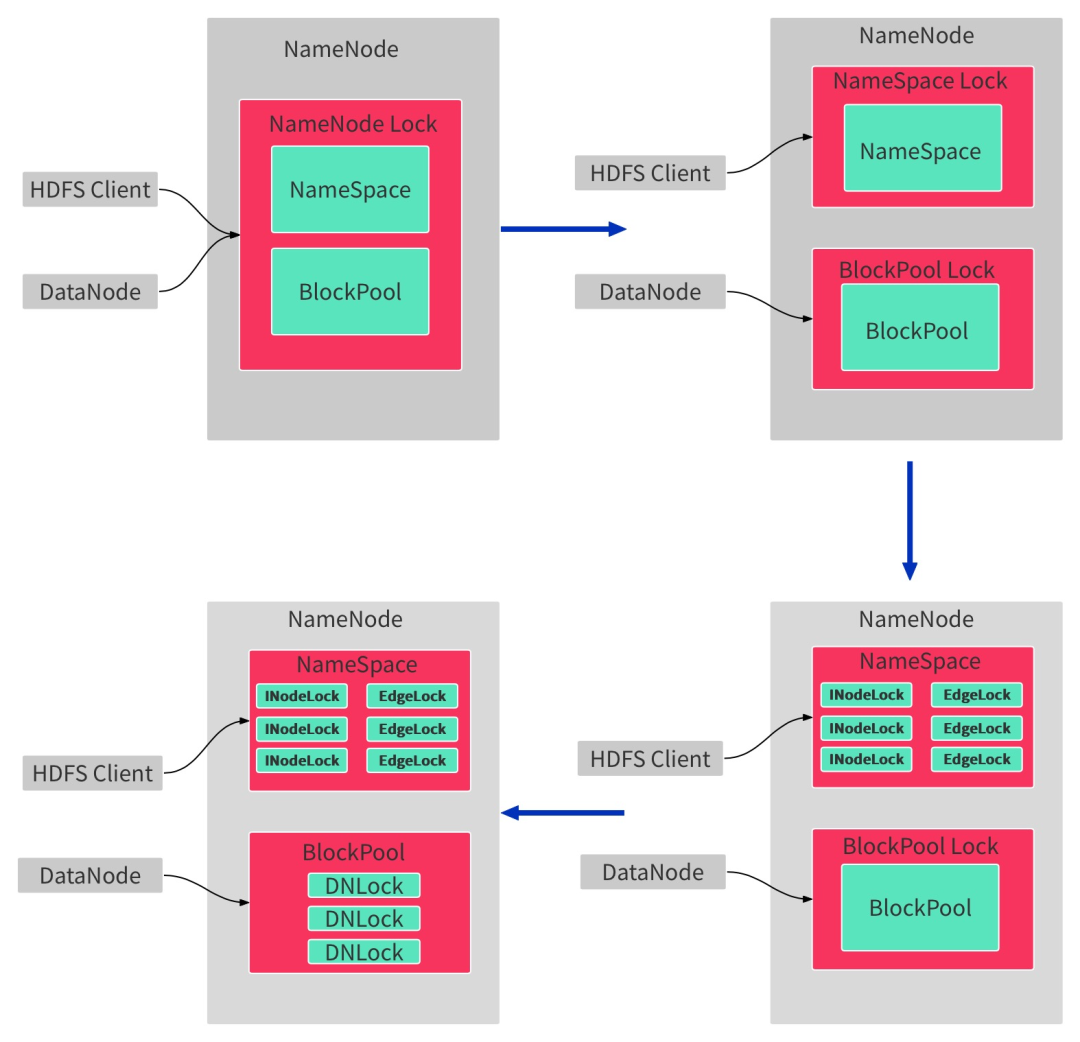
图2-2 NameNode 锁优化过程
3. HDFS 细粒度锁优化实现
3.1 NameNode全局唯一锁拆成
NameSpace层锁和BlockPool层锁
在实践中发现,客户端请求访问NameNode过程中,部分请求需要同时访Namespace层和BlockPool层,有些请求只需要访问 Namespace层,同时服务端请求如DataNode的IBR/BlockReport等请求实际上也只需要访问 BlockPool层,这两层的锁调用可以拆分,实现对两层数据的并行访问。因此拆锁的第一步, 就是将NameNode 全局锁拆分为 Namespace层读写锁和 BlockPool层读写锁,如图2-3所示,通过这种拆分实现访问的这两层数据的RPC请求能够并⾏处理。在实践过程中,我们引入了BlockManagerLock,单独处理BlockPool层锁事件。
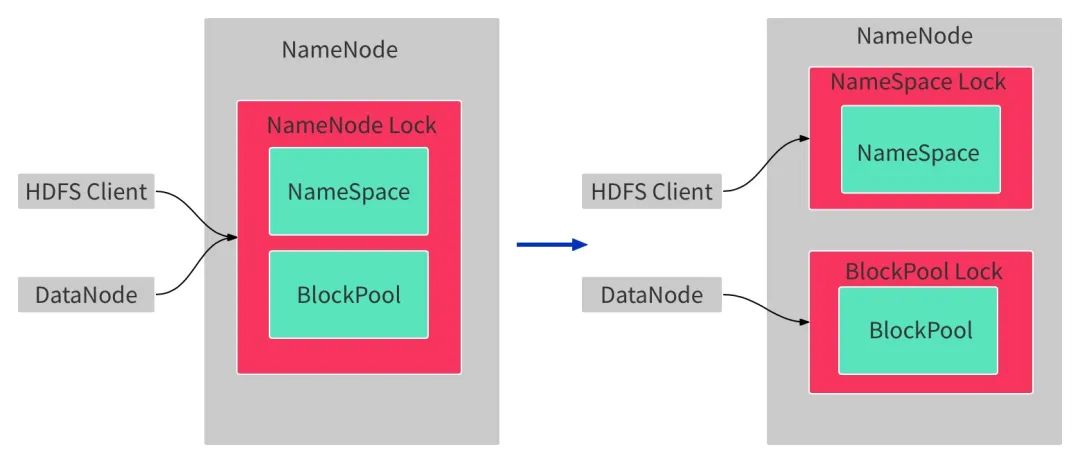
图2-3 NameNode全局唯一锁拆成NameSpace层锁和BlockPool层锁
在实际的拆锁过程中,我们发现NameSpace层和BlockPool层之间有非常多的耦合,这里我们参考了社区的一部分工作HDFS-8966:Separate the lock used in namespace and block management layer, 已经帮助我们解除了部分的依赖,除了社区列出来的这部分依赖之外我们还发现一些BlockPool层对NameSpace层的反相依赖,主要是Block的副本信息和storagePolicy属性信息,这块我们将这部分信息在BlockPool层进行冗余存储,同时确保发生变更时NameSpace层的信息及时同步至BlockPool层。在解除了BlockPool层对NameSpace层的反相依赖后,开始针对不同类型的请求获取何种类型的锁进行区分,如图2-4所示。
-
NameSpace层请求(getListing/getFileInfo等请求),只需要获取NameSpace层锁;
-
BlockPool层请求(BlockReport/IncrementalBlockReport等请求),只需要获取BlockPool层锁,这块我们发现有块上报过程中,有一段更新Quota的逻辑需要获取NameSpace层锁,我们无法做到完美的适配,考虑到我们的Quota采用的外置计算的方式,所以做了相应的取舍,只获取了BlockPool层的锁;
-
同时访问NameSpace层和BlockPool层的请求(setReplication/getBlockLocation),需要同时获取NameSpace层的锁和BlockPool层的锁。
通过对不同请求按不同类型锁要求划分后,我们基本可以做到访问部分不同层数据的请求的并行执行,但仍然有2个问题需要解决。首先是死锁问题,为此我们确保所有请求的加锁顺序的一致性,所有需要同时获取NameSpace层锁和BlockPool层的请求都是NameSpace层锁在前,BlockPool层的锁在后;其次是一致性问题,NameNode内部本身是写一致性,并发读取场景,针对同时访问NameSpace层和BlockPool层的请求,需要确保NameSpace层加锁范围完全包含BlockPool层加锁范围,防止读取到中间状态。
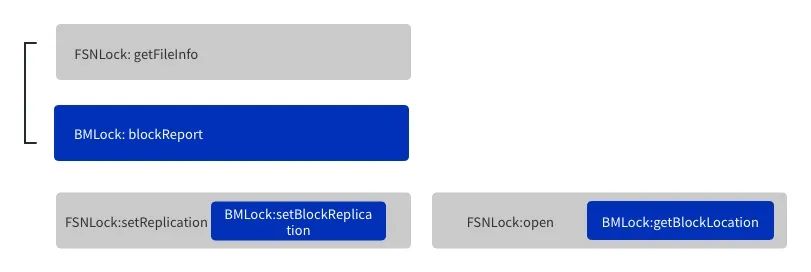
图2-4 不同类型的请求加锁场景
通过上述这种方式,我们基本实现了BlockPool层和NameSpace层的锁拆分,当前这部分优化策略已经在生产环境运行了一段时间,NameNode整体性能大约提升了50%左右。
3.2 NameSpace层锁拆分成INode粒度锁
在实现了FSN层和BP层锁拆分之后,NameNode性能已经有了一定的提升,生产环境中对HDFS的NameNode元数据请求的rpc processtime和queuetime也有明显的下降,但仍然有一些场景无法满足,因此我们继续优化,对NameSpace层的锁进行更细粒度的拆分如图2-5所示,将锁细粒度到INode层,希望能进一步提升NameSpace层RPC并发能力,提升NameNode整体写入能力。
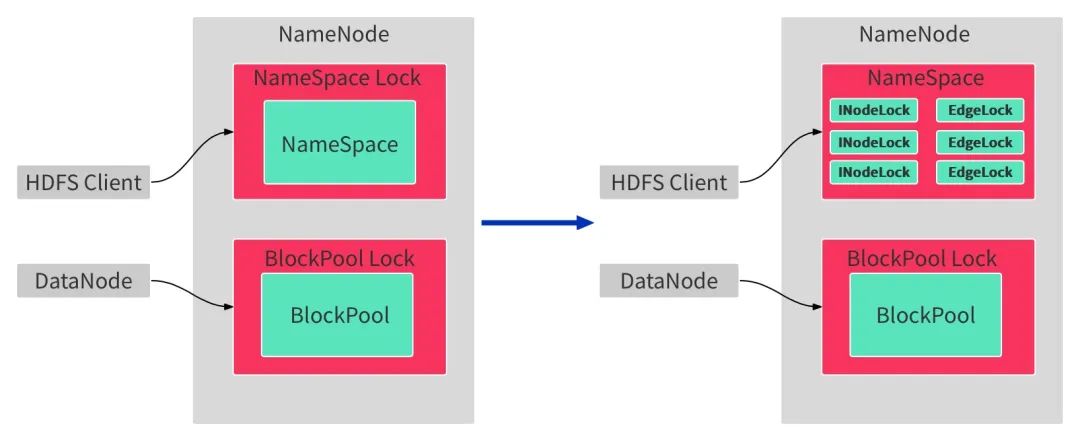
图2-5 NameSpace层锁细粒度拆分
要将NameSpace层锁拆分到INode层级粒度,必然要为对应的INode分配锁对象,在这里我们面临了许多问题。
首先是内存限制,我们目前单组Namespace元数据容量阈值基本在10亿左右,如果每个INode分配一个INode锁,单是INode锁的内存几乎就需要120GB左右的内存,再加上本身NameNode就非常耗费内存,当前的服务器类型很难满足。为了解决这个问题,我们参考了 Alluxio 的LockPool 的概念,也就是有一个锁资源池,每个INode需要Lock加锁的时候,就去资源池里申请锁,同时引用计数会增加,用完之后unlock掉的时候,引用计数会减少,同时配置不同的高低水位,定期清理掉引用计数为0的锁,确保总体内存可控。
其次是锁对象的管理,这方面我们引入了INodeLockManager 用于管理INode和锁对象的之间的映射,我们通过INodeLockManager新增了INode锁的LockPool 和 Edge锁的LockPool,如图2-6所示,管理整个NameSpace层的INode层级的细粒度锁。
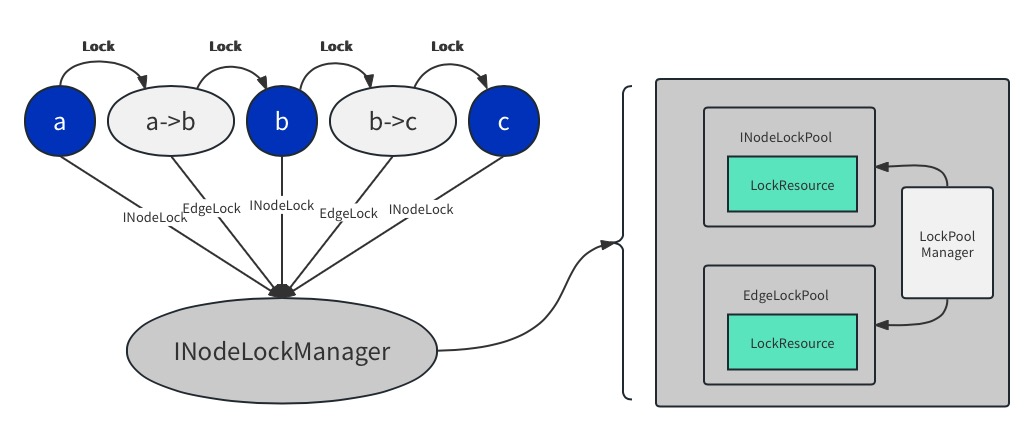
图2-6 NameSpace层的INode层级的细粒度锁管理
完成了锁对象的管理后,Namespace层锁细粒度拆分剩下的问题都是如何预防死锁和数据错乱,因此我们对加锁行为进行规划,总体遵循如下原则。
-
普通Client端的RPC请求采用自上而下的加锁方式,对特殊操作如Rename等操作进行特殊处理;
-
Client端的RPC请求进行全链路加锁,部分请求考虑最后的INode和Edge加写锁;
如图2-7所示,我们配置了3种类型的锁,分别时Read锁,Write_Inode 锁和 WRITE_EDGE锁分别应对不同类型的客户端RPC请求。针对读请求,我们正向遍历INodeTree从ROOT节点开始依次加锁 对对整个路径上的INode和Edge都加读锁;针对addBlock ,setReplication 这类不影响INodeTree的请求,我们也是正向遍历INodeTree从ROOT节点开始依次加读锁,但是对最后一个INode加写锁;针对create ,mkdir请求,我们正向遍历INodeTree ,对最后INode节点和最后的Edge都加写锁,如果最后INode不存在,对最后的Edge也需要加写锁。
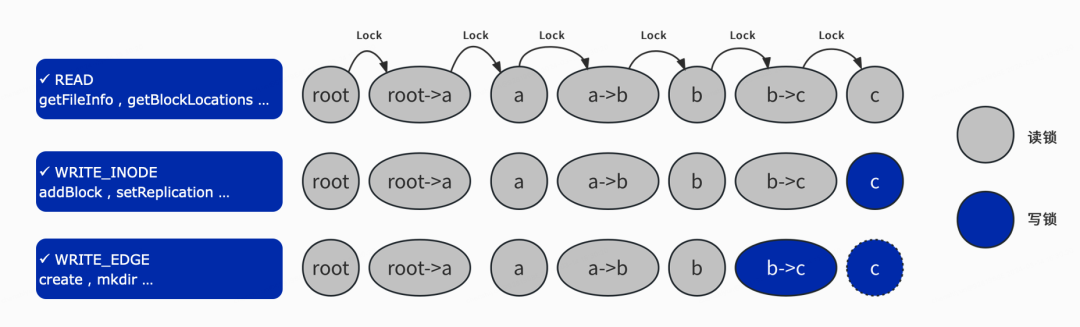
图2-7 INodeLock 加锁方式
除了访问单个路径的请求,还有rename等访问多个路径的rpc请求,如图2-8所示,从 /a/b/c rename 成 /a/b/e,我们对这种场景做了特殊处理。我们首先路径/a/b/c和/a/b/e按字典序确定先后,再自上而下加锁,如图2-8所示,路径/a/b/c排序在前,我们先对/a/b/c 路径加锁,正向遍历INodeTree从ROOT节点开始依次加锁,边b-c,INode c都加上写锁,路径/a/b/e排序在后,我们在对路径/a/b/c加锁完成后,对路径/a/b/e加锁,同样遍历INodeTree,Edge b→e加上写锁,INode e 由于还未存在,则放弃加锁;
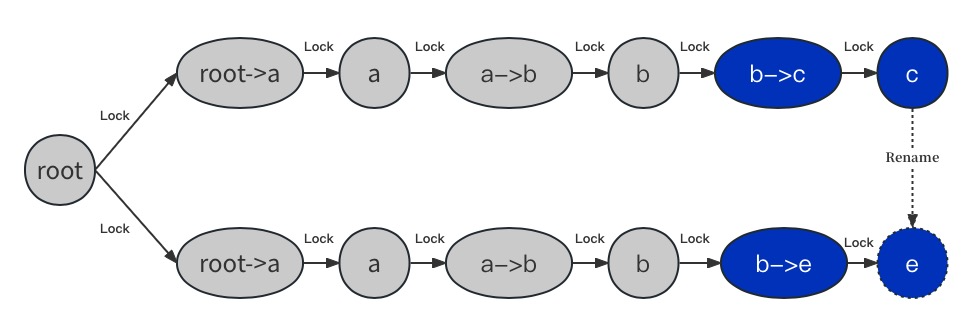
图2-8 Rename RPC操作加锁方式
在上述的工作中,我们完成了不同请求的加锁方式,针对部份加锁场景中存在的INode缺失场景(如文件不存在等场景),如下图2-9所示针对相对典型的是create请求列举了不同RPC类型的加锁逻辑。
-
create 路径/a/b/c文件,如果当前已经存在存在/a/b 路径,则最终会在Edge b->c 加写锁;
-
create 路径/a/b/c文件,如果已经存在/a/b/c路径,则最终会在Edge b→c 和INode c上加写锁;
-
create 路径/a/b/c文件,如果只存在 /a 路径,则会在Edge a->b 这条边上加上写锁。
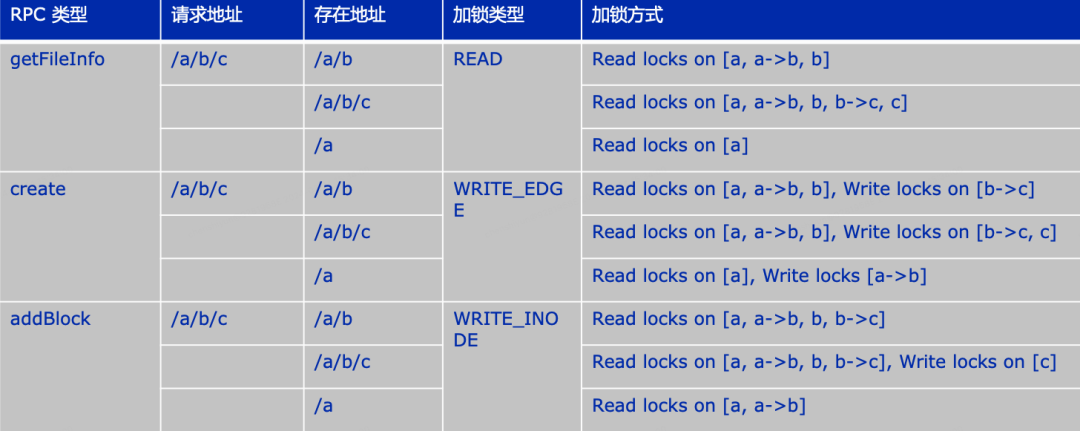
图 2-9 不同RPC类型的加锁逻辑举例
通过实现上述2步拆锁过程,NameNode性能已经有了很大提升,如图2-10展示了我们在测试环境中的性能对比,经过Namespace层读写锁和BlockPool层读写锁拆分后,相比于社区版本,单NameSpace的写性能大约提升了50% ,经过Namespace层细粒度锁拆分后,写性能相比于社区版本有3倍左右的提升,此时NameNode性能瓶颈已经集中在Edits和审计日志同步以及BlockPool层的本身的锁竞争上。在实际生产过程中,我们把之前需要2组NameSpace支持的任务日志采集路径收归为一组NamesSpace支持,在写入QPS上升3倍的场景下,整体rpc queue time 下降了90%,整体性能有很大的提升。
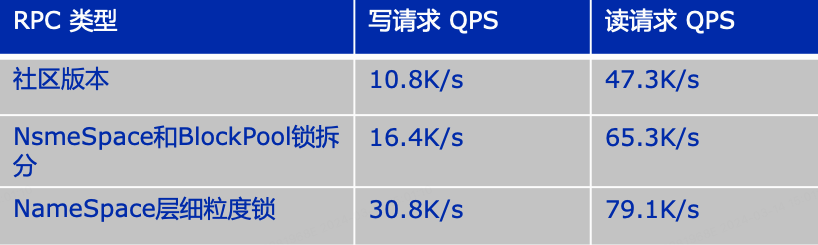
图2-10 锁优化性能对比
四. 总结与展望
NameNode的性能优化已经告一段落了,第一步和第二部的拆锁已经在我们的生产集群上稳定运行了一段时间,整体性能提升明显,整体RPC Queue Time相比于拆锁之前有数量级的下降,当前已经可以支持绝大多数应用场景,包括之前的描述的任务日志聚合和Flink CheckPoint 路径等场景,在接下来计划中,我们也正在考虑是否将BlockPool层锁做进一步细粒度拆分,进一步提升NameNode的性能。
同时考虑到NameNode元数据都存储在内存中,限制了NameNode元数据总量的扩展,特别是小文件场景,我们也将在未来规划引入Ozone或者将NameNode的元数据信息持久化至RocksDB或者KV中,进一步提升单组Namespace的承载量彻底解决小文件问题。
-End-
作者丨云镜
开发者问答
你认为存储系统元数据访问性能和承载能力哪个更重要?欢迎在留言区告诉我们。转发并留言,小编将选取1则最有价值的评论,送出哔哩哔哩幻星集马克杯一个(见下图)。4月30日中午12点开奖。如果喜欢本期内容的话,欢迎点个“在看”吧!

往期精彩指路

