GonFreecss
GonFreecss




- 微软研究院 2024年4月
- 论文:https://arxiv.org/pdf/2404.16130
- 油管两分钟介绍:https://youtu.be/jCjyaQL-7mA
如何一步步引出GraphRAG?🤔
首先聊一下问题背景,当前很多所谓RAG应用,实际上无法处理面向整个长文本的全局性问题。针对该问题,作者认为,不能只是“显式的检索任务”,而应该是QFS任务,即对关注Query的文档内容进行摘要总结。摘要的方法很多,大体分类就是抽象式摘要(abstractive)或提取式摘要(extractive),比如:
用户提出的查询是“公司去年的财务状况如何?”为了回答这个问题,系统不仅需要分析去年的年度报告,还可能需要参考公司在不同时间段的财务新闻、市场分析报告以及其他相关的文档。
如果是抽象式,那就直接seq2seq;如果是抽取式,就先确定哪些句子或段落和query更相关,然后打分(比如根据词频、位置、长度、实体等),最后将候选集按照一定规则、逻辑去组合构建。额,要是加上llm做语义连贯生成,不就是navie 的 navie rag?😶反正对于现在的大模型而言,抽象式摘要已经不是什么事了。但是由于上下文窗口限制问题以及长文本中“loss in the middle”问题的存在,针对全局语料的抽象式QFS依然存在挑战。那作者就觉得,即使navie RAG的分块策略无法满足QFS任务,按道理应该有其他专门针对全局摘要的新型RAG,且应该有另一种格式的预索引(pre-indexing)。
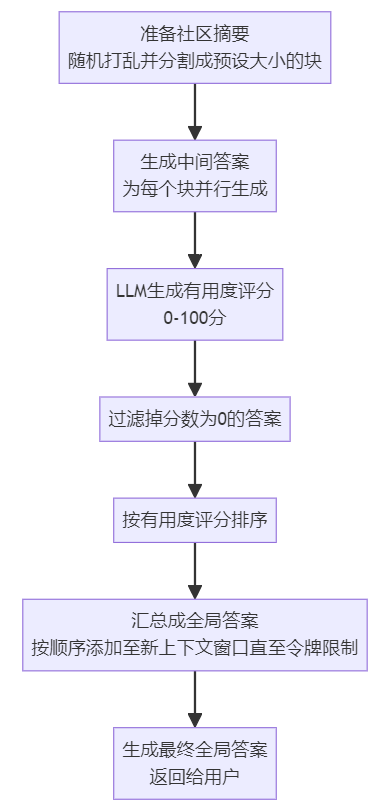
GraphRAG步骤拆解 🚀
1. 源文档分块处理
主要还是得关注老问题——文本块大小的权衡。当文本块过长时,单独处理的数量下降了,但由于上下文窗口限制导致无法充分理解和处理大块信息,从而导致召回率下降。后续要做实体抽取,且作者在HotPotQA数据集实验发现,chunk大小在600 tokens时,会比在2400 tokens时,能提取出多1倍的有效实体数量。
2. 实体和关系提取(文中用“元素实例”的概念包含两者)
通过大模型结合提示工程,从每个分块中抽取实体及其关系来构建图谱。作者设计成一个多阶段的迭代过程,要求LLM评估是否所有实体都被提取出来,那这就是一个二分类问题。作者为了让模型有个更明确的判断,加了一个比较大的logit正偏差(100),来调整模型输出的概率分布,使之对特定类别产生偏好。如果LLM响应说遗漏了实体,那么加入一个声明在上次提取中遗漏了“许多”实体,继续鼓励LLM收集这些缺失的实体。
举例:在一些风险敏感应用中,可能更关注模型在负类别(如疾病、欺诈等)上的准确性,那就可以增加负的logit偏差
3. 实体、关系和社区的总结
作者认为,从源文档中“提取”实体、关系和声明的描述,本身已经是一种抽象性摘要的形式。但这还不够,还需要用LLM对这些“元素”做进一步的总结。但这里还需做实体消歧,不然图谱中可能出现很多重复的元素。作者用了社区检测算法(比如Leiden)来检测图中的社区结构,将紧密两联的实体归纳到同一个社区。通过这种方式,即使LLM在提取过程中未能一致地识别实体的所有变体,社区检测也能够帮助识别出这些变体之间的关联性。归纳到一个社区后,意味着变体都指向同一个实体内涵,只是不同表述或异名词罢了。有了这些基础后,就可以对两种粒度的图结构生成描述性文本,一个是元素(实体、关系)摘要,一个是针对社区的摘要。前者是捕捉图中每个元素的详细信息;后者是对图中较大结构单元的整体理解。我给出一个生成社区摘要的伪代码,
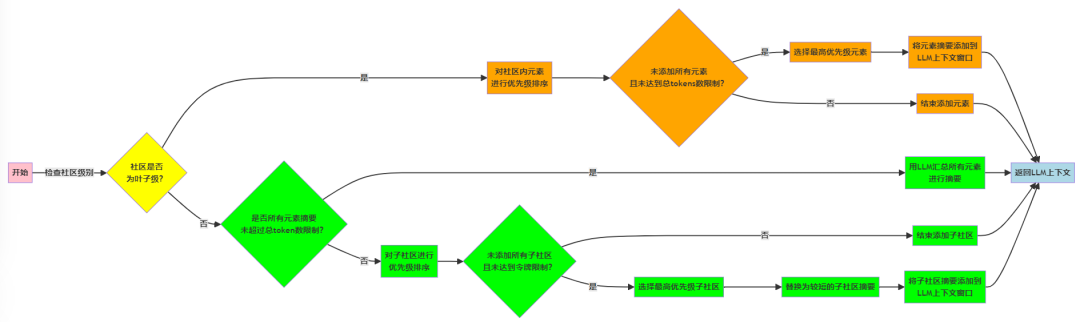
Function 生成社区摘要:
输入:社区, 当前LLM上下文, token数限制长度
输出:添加社区摘要后LLM上下文
{
IF 社区级别 == 叶子级 THEN
对社区内元素进行优先级排序
IF 未添加所有元素 AND 未达到总token数限制 THEN
1. 按以下要求选择元素
(1)最高优先级
(2)添加元素后上下文总长度未超过总token数限制
2. 将元素摘要添加到LLM上下文窗口
END
ELSE {
// 更高级别社区
IF 所有元素摘要未超过总token数限制 THEN
用LLM汇总所有元素进行摘要
ELSE
对子社区进行优先级排序
IF 未添加所有子社区 AND 未达到总token数限制 THEN
1. 选择最高优先级的子社区
2. 如有必要,用较短的子社区摘要替换较长的元素摘要
3. 将子社区摘要添加到LLM上下文窗口
END
END
END
RETURN 添加社区摘要后的LLM上下文
}
4. 最终LLM生成回复(Global Answer)
基于上述阶段生成的社区摘要,最后再生成一次最终答案。LLM可以使用不同层次的社区摘要进行生成回答。这引出另一个问题,有这么多层级的社区摘要,哪个层次的社区摘要能平衡细节与覆盖面,也就好比售前工程师面对客户的时候,除了要细致讲述核心技术,同时也要以点带面,说说相关的落地场景。但如果说得太细或者太泛,都会让客户觉得不专业。所以论文通过后续的评估,强调了在Graph RAG方法中,社区结构的层次性允许系统根据query的需求,选择最合适的抽象层次来生成摘要,这需要考虑摘要的详细程度和覆盖范围之间的平衡。(评估就不展开了😩)在给定社区级别时,全局性问题生成的流程图如下: