



一、TF-IDF回顾
TF-IDF(Term Frequency/Inverse Document Frequency,词频-逆文档频率)算法,可以找出文档中的关键词,
顾名思义,TF-IDF 分数由两部分组成: 第一部分是TF词语频率(Term Frequency), 第二部分是IDF逆文档频率(Inverse Document Frequency)。 其中计算语料库中文档总数除以含有该词语的文档数量,然后再取对数就是逆文档频率。
TF(t)= 该词语在当前文档出现的次数 / 当前文档中词语的总数 IDF(t)= log_e(文档总数 / 出现该词语的文档总数)即:
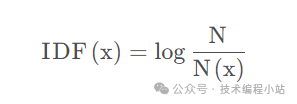
IDF反应了一个词在所有文本中出现的频率,如果一个词在很多的文本中出现,那么它的IDF值应该低,比如I come to China to travel中的“to”。而反过来如果一个词在比较少的文本中出现,那么它的IDF值应该高。一个极端的情况,如果一个词在所有的文本中都出现,那么它的IDF值应该为0。
二、Pyspark注意事项
如果之前跑过数据,需要删除缓存中的rdd数据再跑:normalized_document_tfidf_rdd.unpersist()。
三、具体代码
from pyspark import SparkConf, SparkContext
import math
#以下为计算过程中需要用到的几个函数
# 该函数主要是统计一个文档中包含哪些单词
def word_contains(words_list):
words_set=set(words_list)#将列表转为set,去除重复的单词
return list(words_set)#再将set转为列表返回
# 计算每个单词的逆文档频率idf
def computeIDF(word_df_tuple,num_document):
word=word_df_tuple[0]
df=word_df_tuple[1]
#根据逆文档频率计算公式计算idf值
word_idf = math.log(float(num_document+1) / float(df+1), 2)
return (word, word_idf)#以一个元组tuple的形式返回一个单词的dif值
# 计算每个文档中单词的tf值,并将文档转成向量
def computeTF(words_list, all_words_list):
words_num=len(words_list)#获取文档中出现的单词的个数
words_dic={<!-- -->}
for word in words_list:#统计文档中每个单词出现的次数
if word in words_dic.keys():
words_dic[word]+=1
else:
words_dic[word]=1
tf_vector=[]
for word in all_words_list:#将文档转为一个tf值向量并返回
if word in words_dic.keys():
tf=float(words_dic[word])/words_num
tf_vector.append(tf)
else:
tf_vector.append(0)
return tf_vector
# 计算每个文档向量中每个单词的tfidf值
def computeTFIDF(tf_vector, words_idf_dic,all_words_list):
i=0
tfidf_vector=[]
for word in all_words_list:#将每个单词的tf值和idf值相乘
tfidf=tf_vector[i]*words_idf_dic[word]
tfidf_vector.append(tfidf)
i+=1
return tfidf_vector
# 对每个tfidf向量进行归一化
def nomoralize(tfidf_vector):
new_vector=[]
sum=0
for item in tfidf_vector:
sum+=math.pow(item,2)
sqrt_sum=math.sqrt(sum)
for item in tfidf_vector:
new_item=item/sqrt_sum
new_vector.append(new_item)
return new_vector
#主程序
if __name__ == "__main__":
#conf = SparkConf().setAppName("tfidf")
#sc = SparkContext(conf=conf)
# 删除缓存中的rdd数据
# normalized_document_tfidf_rdd.unpersist()
#示例文档数据,每个文档是一个单词列表
documents_list=[["hello","world","china","good","spark","good"],
["hello","china","china","great","love","china"],
["love","spark","spark","good","hello","spark"]]
#documents_list=[["hello","friends","today","is","my","holiday"],
# ["hello","china","china","great","love","china"],
# ["love","spark","spark","good","hello","spark"]]
#创建RDD并进行缓存
tokenized_document_rdd=sc.parallelize(documents_list).cache()
print ("*************************** compute idf************************************")
#这个阶段的主要操作是计算单词的idf值
#获取文档的个数用来计算逆文档频率
num_document=tokenized_document_rdd.count()
#计算每个单词的文档支持度
#实现思路是,针对每个文本文档,通过将单词列表转成set来获取每个文档中出现的单词,然后
#通过flatMap操作,将每个文档出现的单词合并成一个新的集合。在新的集合中,一个单词出现
#的次数即是其文档支持度。因此,我们可以在flatMap操作之后应用map和reducebykey操作来统
#计每个单词的文档支持度。
words_df_rdd=tokenized_document_rdd.flatMap(lambda words_list:word_contains(words_list)) \
.map(lambda word:(word,1)) \
.reduceByKey(lambda a,b:a+b)
#根据单词的文档频率和文档的总数计算每个单词的idf
# computeIDF函数实现的是具体计算idf的值
words_idf_rdd=words_df_rdd.map(lambda word_df_tuple:
computeIDF(word_df_tuple, num_document))
print ("*********************************** compute tf *******************************")
#计算每个文本中每个单词出现的频次,进而计算tf值
#返回包含所有单词的列表
#flatMap是将所有文档中的单词合并成一个大的列表,distinct是将列表中重复的单词去除
all_words_list= tokenized_document_rdd.flatMap(lambda words_list:words_list) \
.distinct() \
.collect()
#考虑到单词可能很多,我们将包含所有单词的all_words_list变量做出广播变量,使得一个executor
#上的多个Task可以共享该变量
all_words_broadcast=sc.broadcast(all_words_list)
#计算单词的tf,得到文档的tf向量
document_tf_rdd= tokenized_document_rdd.map(lambda words_list:
computeTF(words_list, all_words_broadcast.value))
print ("******************************* compute tfidf*********************************")
#提取从rdd中提取每个单词的idf值,并将提取的列表变量转成字典变量,进而转成广播变量,以
#供发送给各个executor计算每个文档中每个单词的tfidf值
words_idf_list= words_idf_rdd.collect()
words_idf_dic={<!-- -->}
for item in words_idf_list:#将单词的idf值列表转为字典易于获取每个单词的idf值
words_idf_dic[item[0]]=item[1]
words_idf_broadcast=sc.broadcast(words_idf_dic)
#计算每个文本中每个单词的tfidf值
document_tfidf_rdd= document_tf_rdd.map(lambda words_tf_list:computeTFIDF(words_tf_list,
words_idf_broadcast.value,all_words_broadcast.value))
#将每个文本对应的列表向量进行归一化
normalized_document_tfidf_rdd= document_tfidf_rdd.map(lambda tfidf_vector:
nomoralize(tfidf_vector))
print ("************************** print tfidf vectors*********************************")
#打印输出每个tfidf向量
tfidf_vectors= normalized_document_tfidf_rdd.collect()
num = 0
for item in tfidf_vectors:
print (item)
num = num + 1
print("第%d条文本:" % num)
print("当前文本的tfidf向量: \n", item)
print(documents_list[num - 1])
print("最大值是:", p.max(item), "所在的下标是:", item.index(p.max(item)))
# tf-idf值最大的单词
print("tfidf值最大的单词", documents_list[num - 1][ item.index(p.max(item)) ], "\n")
四、结果分析
每条句子(文档)的tf-idf最大的单词也打印出来了:
*************************** compute idf************************************
*********************************** compute tf *******************************
******************************* compute tfidf*********************************
************************** print tfidf vectors*********************************
[0.5820915838854853, 0.0, 0.29104579194274266, 0.0, 0.29104579194274266, 0.7012517964002163, 0.0]
第1条文本:
当前文本的tfidf向量:
[0.5820915838854853, 0.0, 0.29104579194274266, 0.0, 0.29104579194274266, 0.7012517964002163, 0.0]
['hello', 'china', 'china', 'great', 'love', 'china']
最大值是: 0.7012517964002163 所在的下标是: 5
tfidf值最大的单词 china
[0.0, 0.0, 0.0, 0.6060537877905645, 0.7546051455392007, 0.0, 0.2515350485130669]
第2条文本:
当前文本的tfidf向量:
[0.0, 0.0, 0.0, 0.6060537877905645, 0.7546051455392007, 0.0, 0.2515350485130669]
['hello', 'china', 'china', 'great', 'love', 'china']
最大值是: 0.7546051455392007 所在的下标是: 4
tfidf值最大的单词 love
[0.30151134457776363, 0.0, 0.9045340337332908, 0.0, 0.0, 0.0, 0.30151134457776363]
第3条文本:
当前文本的tfidf向量:
[0.30151134457776363, 0.0, 0.9045340337332908, 0.0, 0.0, 0.0, 0.30151134457776363]
['hello', 'china', 'china', 'great', 'love', 'china']
最大值是: 0.9045340337332908 所在的下标是: 2
tfidf值最大的单词 china

