
CNN与ViT的完美结合!TransXNet: 结合局部和全局注意力提供强大的归纳偏差和高效感受野

极市导读
本文引入了一种新的混合网络模块,称为D-Mixer,它以一种依赖于输入的方式聚合全局信息和局部细节。该设计可以使网络同时看到全局和局部信息,从而增强了归纳偏差。论文中的实验证明,这种方法在感受野方面表现出色,即网络可以看到更广泛的上下文信息。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

导读
本文依旧从经典的 ViTs 说起,即基于 MHSA 构建远距离建模实现全局感受野的覆盖,但缺乏像 CNNs 般的归纳偏差能力。因此在泛化能力上相对较弱,需要大量的训练样本和数据增强策略来弥补。
针对这个问题,Swin Transformer 率先引入了移位窗口自注意力来引入归纳偏差并减少计算成本。然而,作者认为由于其仍然是基于窗口的局部自注意力机制,因此感受野还是被限制。
为了使 ViTs 具有归纳偏差,后面大部分工作都选择构建了混合网络,如 PVT 等,即融合了自注意力和卷积操作。然而,由于标准卷积在这些混合网络中的使用,性能改进有限。这是因为卷积核是输入无关的,不能适应不同的输入,从而导致了自注意力和卷积之间的表示能力差异。
为了解决上述问题,这篇论文针对性地引入了一种新的混合网络模块,称为Dual Dynamic Token Mixer (D-Mixer),它以一种依赖于输入的方式聚合全局信息和局部细节。具体来说,输入特征被分成两部分,分别经过一个全局自注意力模块和一个依赖于输入的深度卷积模块进行处理,然后将两个输出连接在一起。这种简单的设计可以使网络同时看到全局和局部信息,从而增强了归纳偏差。论文中的实验证明,这种方法在感受野方面表现出色,即网络可以看到更广泛的上下文信息。
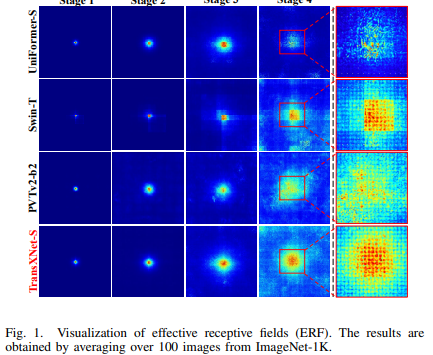
除了D-Mixer,文中还介绍了一个多尺度前馈网络(MS-FFN),它在 Token 聚合过程中探索了多尺度信息。通过堆叠由 D-Mixer 和 MS-FFN 组成的基本模块,最终构建了一种名为 TransXNet 的通用骨干网络,用于视觉识别任务。
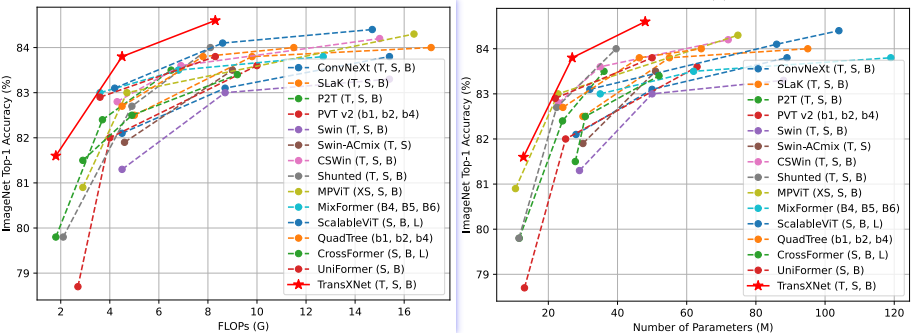
最后,作者在图像分类、目标检测和语义/实例分割任务上进行了大量实验,结果表明,所提方法在性能上超越了以前的方法,同时具有更低的计算成本。
方法
TransXNet
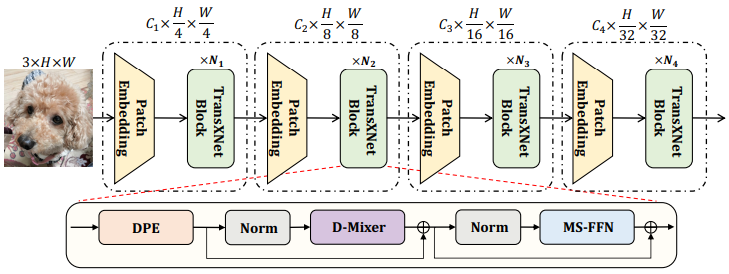
如上图所示,同大多数 Backbone 而言,TransXNet网络采用了一个分层的结构,分为四个stage。每个阶段由一个图像块嵌入层和多个依次堆叠的模块组成。第一个图像块嵌入层使用7x7的卷积层(步长=4),随后是批量归一化(BN),而其余阶段的图像块嵌入层使用3x3的卷积层(步长=2)和 BN。每个模块包括一个Dynamic Position Encoding (DPE)层,一个Dual Dynamic Token Mixer (D-Mixer),以及一个Multiscale Feed-forward Network (MS-FFN)。
Dual Dynamic Token Mixer (D-Mixer)
为了提高Transformer模型的泛化能力并引入归纳偏差,以前的方法已经尝试结合卷积和自注意力来构建混合模型。然而,这些方法中的静态卷积核限制了 Transformer 的输入依赖性。因此,作者提出了一个轻量级的 Token Mixer,称为Dual Dynamic Token Mixer (D-Mixer),它可以动态地利用全局和局部信息,同时注入大的感受野和强大的归纳偏差,而不牺牲输入依赖性。
D-Mixer的工作流程如下图所示。对于一个特征图
,首先将其沿通道维度均匀分为两个子特征图
和
。然后,
和
分别经过一个全局自注意力模块 (OSRA) 和一个动态深度卷积模块(IDConv),生成相应的特征图然后将它们沿通道维度连接在一起,生成输出特征图
。最后,作者使用 Squeezed Token Enhancer (STE) 来进行有效的局部 token 聚合。
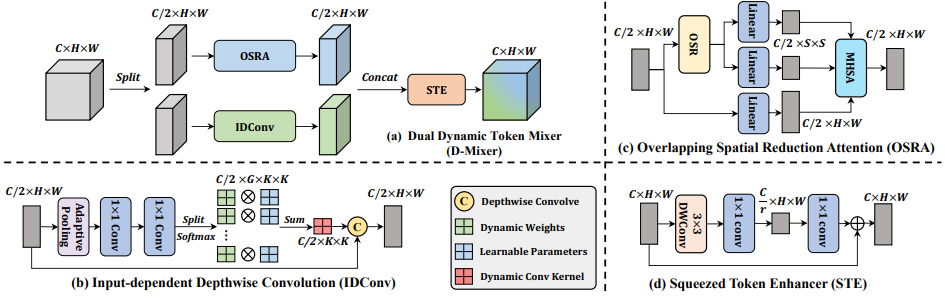
可以看出,D-Mixer的主要特点是,通过堆叠多个D-Mixer,OSRA和IDConv生成的动态特征聚合权重同时考虑了全局和局部信息,从而增强了模型的表示学习能力。
值得一提的是,D-Mixer的其中一个关键组成部分是"Input-dependent Depthwise Convolution"(IDConv),它用于在动态输入依赖方式下注入归纳偏差并执行局部特征聚合。这个 IDConv 通过自适应平均池化来聚合空间上下文,然后通过两个1x1的卷积层产生注意力图,最终生成输入依赖的深度卷积核。与其他动态卷积方法相比,IDConv 具有更高的动态局部特征编码能力,并且在计算开销上较低。
Overlapping Spatial Reduction Attention (OSRA)
下面简单为大家梳理下 OSRA 模块的计算流程:
-
首先,输入特征图 通过 模块进行处理,产生输出特征图 。 -
然后,通过线性变换将 映射为查询 ,并将 映射为键 和值 。 -
接下来,通过 split 操作将线性变换后的 分成多个部分。 -
最后,通过局部细化模块 (LR) 和一个相对位置偏置矩阵 (B) 进行一些后处理。
这个计算流程可以帮助模型更好地捕捉图像中的空间关系,其中引入了 OSR 来改进对图像边界附近空间结构的建模,这有助于提高模型在图像识别任务中的性能。
Squeezed Token Enhancer (STE)
STE 主要用于增强 token 之间的交互,同时降低计算成本。在以前的方法中,为了实现 token 之间的交互,通常会使用1x1卷积层,但这会导致相当大的计算开销。为了降低计算成本而不影响性能,作者引入了该模块。
STE模块的计算流程如下所示:
-
首先,输入特征图 通过 深度卷积 (DWConv3x3) 进行处理,以增强 token 之间的局部关系。 -
然后,使用通道压缩和扩展的 卷积层,降低计算成本。 -
最后,通过残差连接,将上述两个部分相加,以保留表示能力。
Multi-scale Feed-forward Network (MS-FFN)
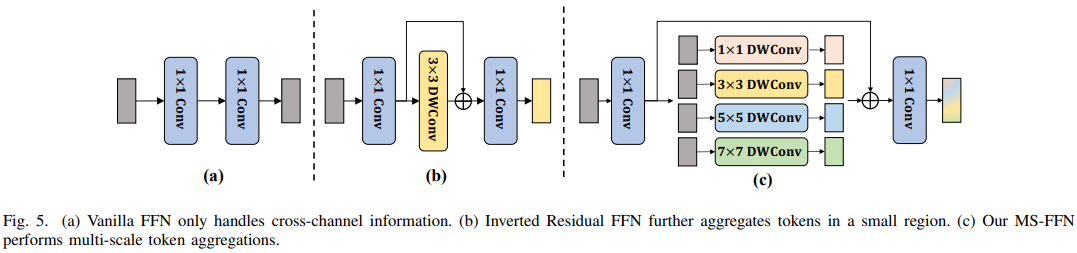
MS-FFN 主要用于在模型的前馈神经网络(Feed-forward Network)中进行多尺度的特征处理。通常,前馈神经网络(FFN)用于对输入特征进行特征提取和变换,以提高模型的表示能力。然而,传统的 FFN 可能会受限于单一尺度的特征提取,难以充分利用多尺度的信息。
为了克服这个问题,本文引入了该模块。与传统的FFN不同,其采用了多尺度的处理方式。具体来说,MS-FFN 模块使用了四个并行的深度可分离卷积 (depthwise convolution),每个卷积核的尺度不同,分别是 。这四个卷积核分别处理输入特征的四分之一通道。这意味着每个卷积核专门负责处理输入特征的一部分通道,以有效地捕获多尺度的信息。此外,还有一个 深度卷积核,用于学习通道方面的缩放因子。这个 深度卷积核的作用是对通道进行加权缩放,以更好地融合多尺度信息。
Architecture Variants
为了控制不同计算成本,以适应不同的应用需求,文本方法同样通过缩放因子设计了几个不同的变种,包括TransXNet-T(Tiny)、TransXNet-S(Small)和TransXNet-B(Base)。为了调整不同变种的计算成本,作者使用了两个可调整的超参数,除了通道数和模块数量之外。这两个超参数如下:
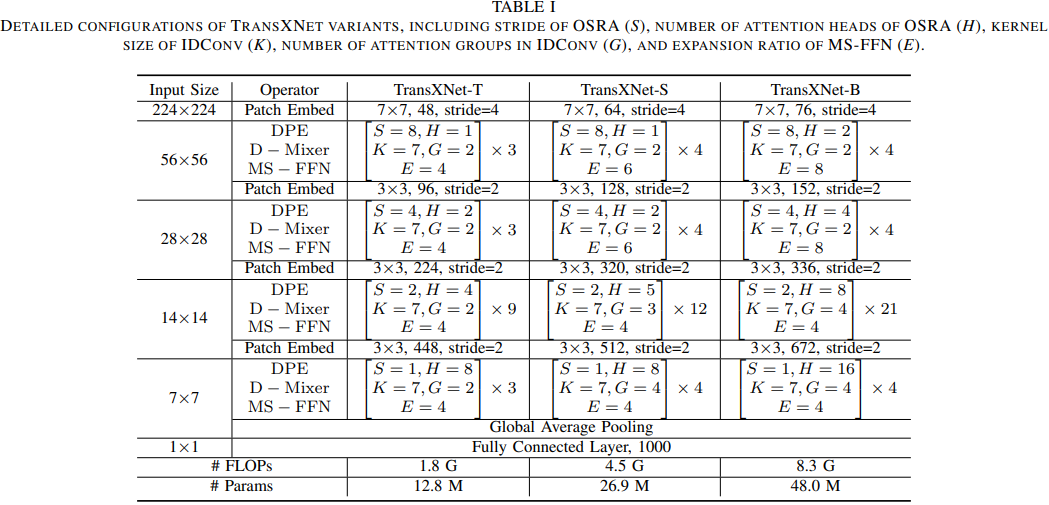
-
Attention Groups(注意力组数):这个超参数控制了 IDConv模块的计算成本。在Tiny版本中,注意力组数固定为2,以确保合理的计算成本。而在更深层的Small和Base模型中,作者逐渐增加了注意力组数,以提高 IDConv 的灵活性。这类似于 MHSA 模块的头数在模型变得更深时逐渐增加的方式。 -
FFN(扩展比率):以前的工作通常将阶段1和阶段2中的 FFN 扩展比率设置为8。但由于这两个阶段的特征图通常具有较大的分辨率,这导致了高的 FLOPs。因此,本文逐渐增加了不同架构变种中的 FFN 扩展比率。
实验
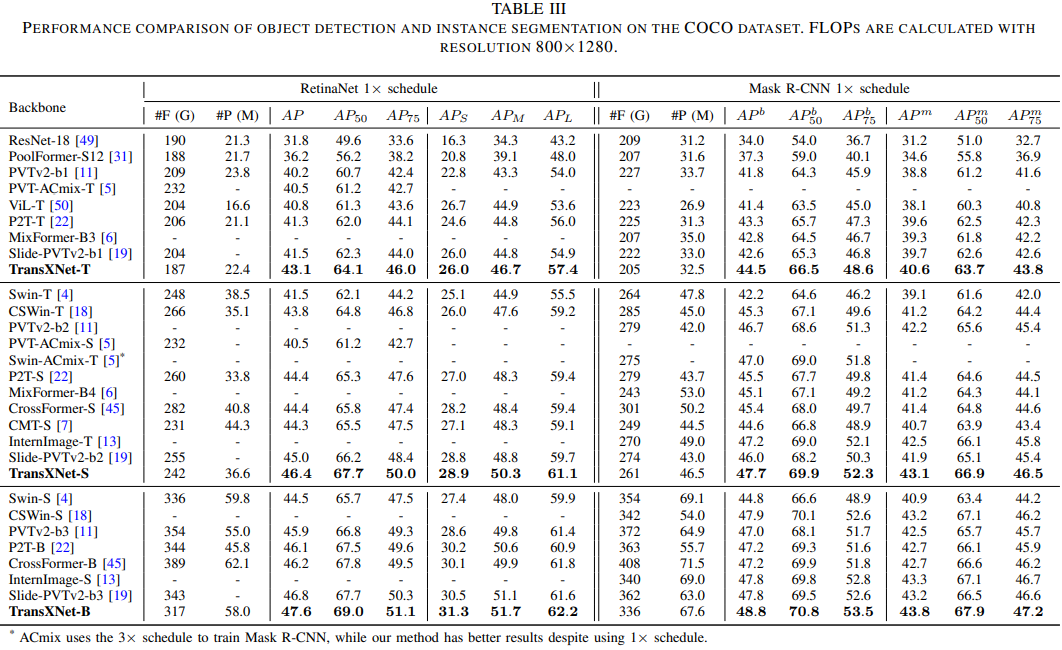
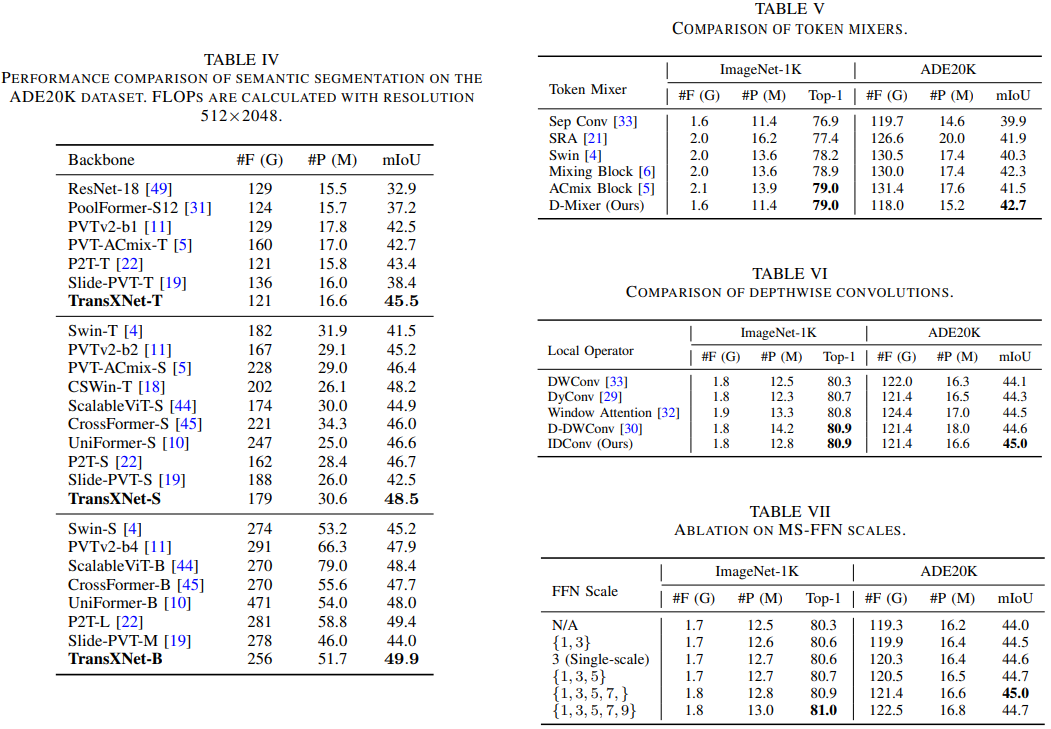
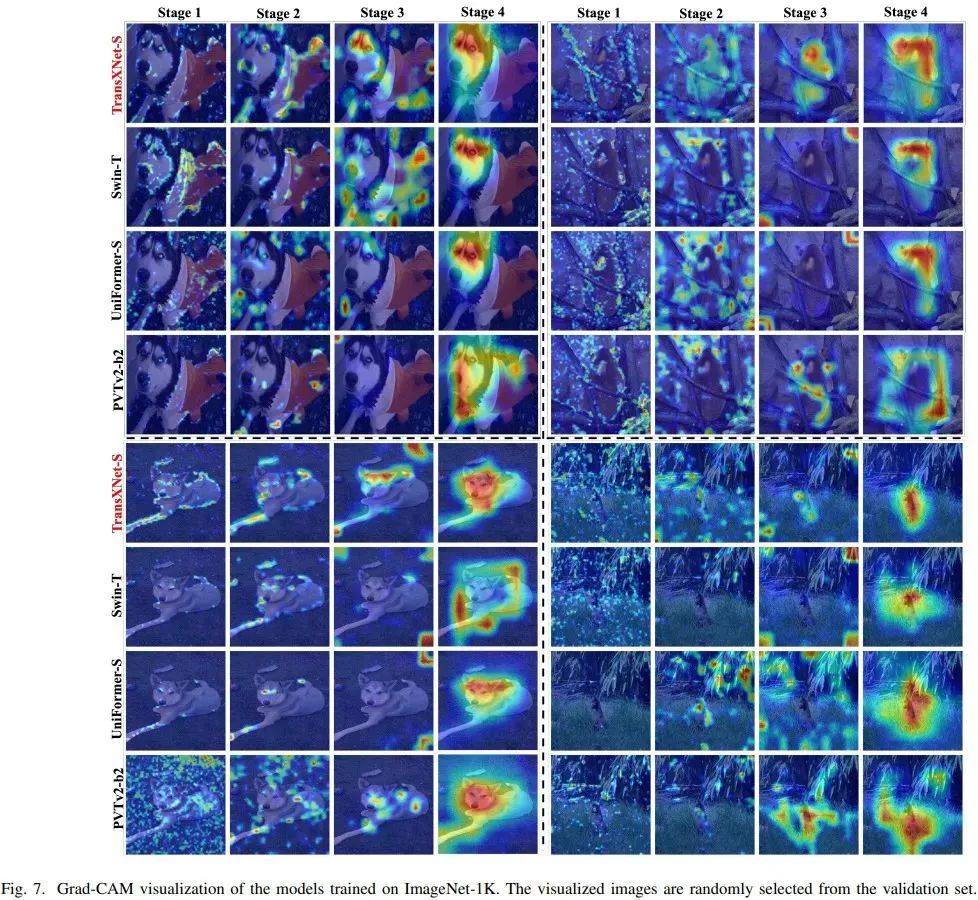
总结
在这项工作中,作者提出了一种高效的D-Mixer,充分利用了OSRA和IDConv提供的混合特征提取。通过将基于D-Mixer的块堆叠到深度网络中,IDConv中的卷积核和OSRA中的注意力矩阵都是动态生成的,使用了前几个块中收集的局部和全局信息,从而增强了网络的表示能力,融入了强大的归纳偏差和扩展的有效感受野。此外,作者还引入了MS-FFN,用于在前馈网络中进行多尺度的Token聚合。通过交替使用D-Mixer和MS-FFN,作者构建了一种新型的混合CNN-Transformer网络,称为TransXNet,该网络在各种视觉任务上表现出了SOTA的性能。总的来说,这项工作提出了一种新颖的网络架构,通过有效利用不同的特征提取方法,提高了网络的表示能力,同时在前馈网络中引入多尺度的特征聚合,为各种视觉任务提供了出色的性能。
公众号后台回复“数据集”获取100+深度学习各方向资源整理
极市干货
点击阅读原文进入CV社区
收获更多技术干货