
万字长文!人体姿态估计(HPE)入门教程

极市导读
作者总结了人体姿态估计入门需要学习的一些知识,在学习过程中的一些感悟和踩过的坑,列举主要的工作脉络和一些细节。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
0.前言
自己的研究方向属于人体姿态估计领域,但是学了大概两年了,才感觉刚入门(主要是自己太菜...),一开始对各种各样的名词和网络方法摸不着头脑,没有建立属于自己的研究体系,论文堆积如山,各种方法层出不穷,研究生就这么几年,哪能看的完呢?没有一个指路人,真的太难,而且这个领域的应用和教程属实没有检测和分割多......这里总结一下自己在学习过程中的一些感悟和踩过的坑,列举主要的工作脉络和一些细节,还有前期主要看的论文。主要以帮助后来者入门使用,肯定有一些内容属于自己主观理解,纯属个人经验,若有错误,麻烦一起讨论交流,感谢指正!欢迎留言私信哈~~
1.总述
人体姿态估计按照不同的标准有着各种各样的分类。包括2D/3D/mesh,单人/多人,自顶向下(top-down)/自底向上(bottom-up),图像(image)/视频(video),坐标/热图(heatmap), 检测(detection-based)/回归(regression-based) , 单阶段(single-stage)/多阶段(multi-stage)......等等,各种分类方法之间相互嵌套,每篇文章都有作者按照自己理解划分的类别,真的很让人摸不着头脑。但实际上,很多分类都有着递进的关系,例如:
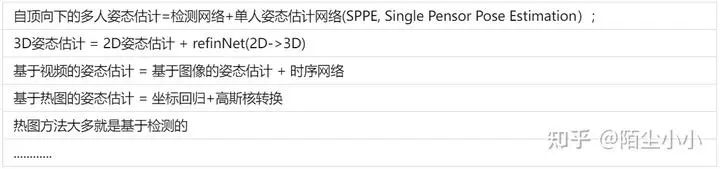
大部分论文在讲述的时候,都是继承之前的论文方法,因此很多细节讲的不是很清楚,一篇参考文献就一笔带过,如果没有完整的体系架构,直接看最新的文献会很乱,发现需要补充的知识越来越多,导致知识体系细碎繁杂,看完了也不知道讲的是什么。这里给出姿态估计的几篇综述文献,里面从各个角度讲述了姿态估计的一些经典方法和分类,有助于建立整个框架体系:
[1] Single Person Pose Estimation: A Survey(2021.09)
https://arxiv.org/abs/2109.10056v1
[2] Monocular human pose estimation: A survey of deep learning-based methods(2020.06)
https://arxiv.org/abs/2006.01423
[3] Deep Learning-Based Human Pose Estimation: A Survey(2020.11) https://arxiv.org/abs/2012.13392v1)
[4] Recent Advances in Monocular 2D and 3D Human Pose Estimation: A Deep Learning Perspective (2021.04)
https://arxiv.org/abs/2104.11536
[5] Recovering 3D Human Mesh from Monocular Images: A Survey(2022.03)
https://arxiv.org/abs/2203.01923v1
在写这篇文章的时候,发现了大神刚出的一篇比较好的总结,链接放到这里,供大家学习参考,可先阅读,对比和本文的异同,以作参考:
人体姿态估计的过去,现在,未来
https://zhuanlan.zhihu.com/p/85506259
还有OpenMMlab有一期卢策吾老师的视频讲解,总结了pose相关的方法,链接如下,建议观看,以作参考:
https://www.bilibili.com/video/BV1kk4y1L7Xb
这里使用上面文献[4]的一张图展示一下相关研究和论文,按照时间顺序展示,清晰明了,推荐阅读这篇综述:
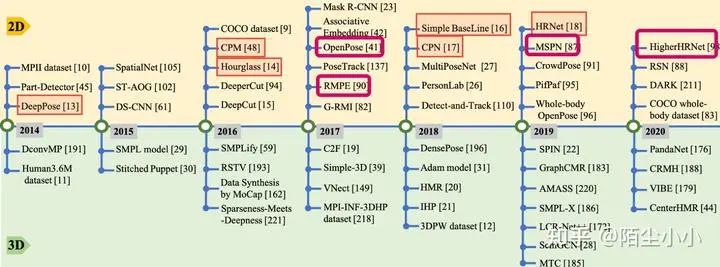
另外上面文献[5]是关于人体Mesh研究的,也是我研究的一个领域,所以把这篇综述也放了上来,同样有一张图:

建立思路:按照时间建立自己的知识体系,个人认为是一个很好的方式,感受这个领域的方法一步一步的推进过程,一点一点构建自己的知识领域框架,后面读论文不再是一行一行读,而是一块一块地读;而且可以在阅读的过程中,从后面的研究者在Related Work中对早期的文章的见解和描述,是一种感受不同人对某一方法的不同见解的过程,幸运的话甚至可以从中得到启发。从一篇文献中追根溯源,并总结流派和方法,然后再继续关注当前的最新进展,逐步完善自己的领域,是我个人认为比较好的一种科研思维。
2. 体系架构
-
本文以如下结构进行介绍,包括人体2D,3D,Mesh;分别介绍每个类别的开山之作,主要流派(其中的经典代表网络和方法),以及最新进展,如果有更新的作品,欢迎大家进行补充。
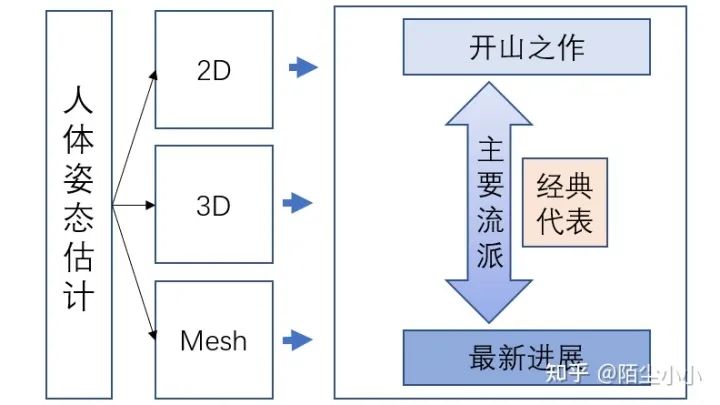
-
这里推荐OpenMMLAB实验室的mmpose项目:上面有很多总结、经典以及最新方法的实现和讲解,有框架,有代码,有教程,可快速复现,而且维护和更新也很块。
https://github.com/open-mmlab/mmpose
3. 2D姿态估计
3.0 必读论文总览
下图是2D姿态估计领域比较经典的论文,也是我认为必读的一些论文,建议按照时间顺序来阅读,可以从中感受2D姿态估计的层层递进。阅读的时候建议大家关注一下作者,因为很多论文包含了同一作者,说明两篇论文之间是有联系的,例如,Openpose的前身就是CPM,MSPN是基于CPN的修改,另外Hpurglass、CPN、SimpleBaseline2D在HRNet论文中做了比较......这些论文之间的异同以及包含关系,也是比较有趣的。所有论文的题目和链接也一起放在了下面,感兴趣的童鞋可以直接下载阅读。每一篇文章的详细讲解,大家可以在各大分享平台找到,很多大佬也都分享过自己的见解,本文仅对部分文章进行简单的介绍,梳理论文逻辑,详细的内容大家可以自行阅读论文或者搜索参考其他作者讲解的内容。
当然,只看论文是不够的,因为论文对网络结构的讲解比较抽象,进一步的学习一定要亲自敲一遍网络结构的代码,这一部分后续有时间也可以整理一下(挖坑1...)。
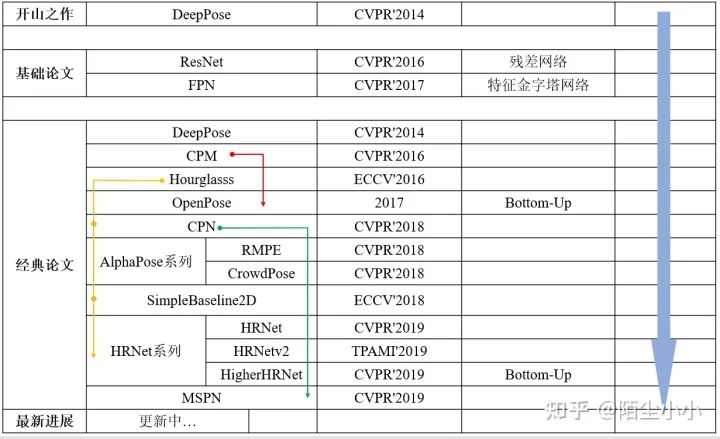
3.1 开山之作(DeepPose)
《[DeepPose: Human Pose Estimation via Deep Neural Networks]》(CVPR'2014)
https://arxiv.org/abs/1312.4659

DeepPose是姿态估估计领域中使用深度学习检测人体关节点的最初的论文,在它之前,很多文章都是基于身体部位(part)检测的。它 (1)继承了AleXNet网络结构,AlexNet 作为 backbone,是第一个DNN姿态估计网络;(2)采用级联(cascade)结构细化(refine)姿态。这对后面的网络结构思想有了很大启发,后续的很多网络也都采用了cascade的这种结构。
这篇文章提出了姿态估计的两个概念:
-
姿态估计的公式化定义

-
级联(cascade)结构
cascade这个单词在后面的很多网络中都会用到,例如Hourglass和CPM,但我一开始并不太明白,后来翻看英文释义,表示“串联,级联”,也就是说,它将一个网络模块重复地使用多次,串在一起,形成multi-stage,相当于加深了层数,第一个stage粗检测,后面逐渐精细,类似于“从粗到细”的策略,逐渐纠正,不断细化。事实证明这种结构的有效性非常好。后续我们也会经常见到这个词,以及这种结构。
与之对应的还有一个词:stacked,堆叠,Hourglass使用了这个词的表述。两个词都表示同样或相似的Block结构多层连接。
论文使用的数据集有两个:FLIC和LSP,评价指标分别为PDJ(=0.9+)和PCP@0.5(=0.61),评价指标和数据集都比较旧了,现在已经很少使用。建议大家看看上面提到的综述论文,里面有数据集和评价指标的详细总结,后期有空,可以单独写一个总结(挖坑2...)。
填坑2:人体姿态估计评价指标见下文。
陌尘小小:【人体姿态估计评价指标】
https://zhuanlan.zhihu.com/p/646159957
3.2 必看论文
-
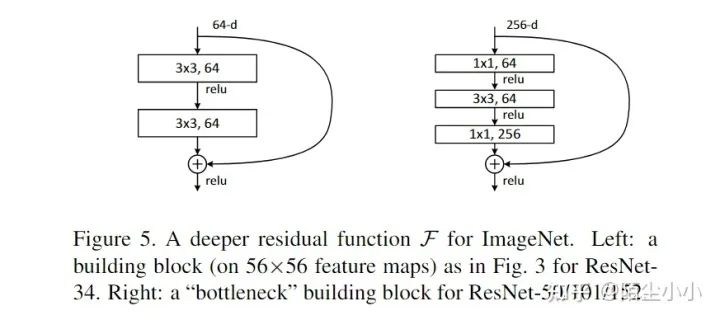
ResNet:
ResNet就不用多说了,源自何恺明论文《Deep Residual Learning for Image Recognition》。它几乎是现在深度学习框架的基石,几乎所有的backbone都用到它或者它的变体,当然,几乎所有的姿态估计的结构代码中都用到了这种残差结构。在使用代码的时候,主要注意三个函数,这也是后续所有网络结构代码经常用到的三个函数:BasicBlock;Bottleneck;_make-layer方法。具体原理大家可看论文或者其他大佬讲解。
具体的代码可以看下面这个博文:
ResNet _make_layer代码理解
https://blog.csdn.net/cangafuture/article/details/113485879
-
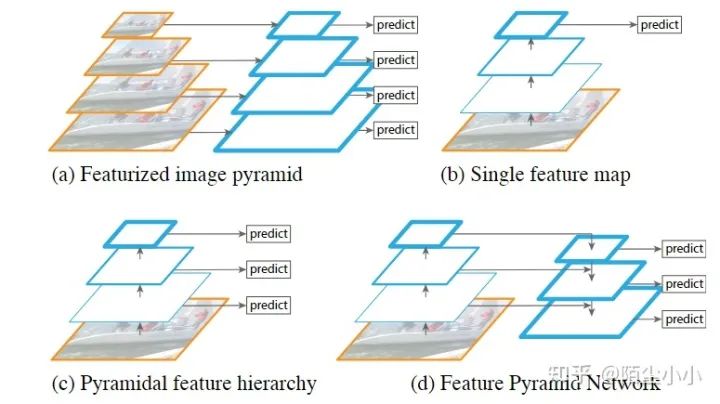
FPN
特征金字塔网络,是常用的Neck网络,后续有它的诸多变体,很多网络会用到它。写到这里大家要注意区分一下:图像金字塔和特征金字塔的概念,从下图(a)就可以很明显地看出来了。
具体的代码和讲解可以看这个博文:
FPN网络结构及Pytorch实现
https://blog.csdn.net/qq_41251963/article/details/109398699
下面还有一些方法网络很经典,每一篇都逐渐递进,每一篇都值得去看并且复现其网络结构,例如Hourglass的网络,甚至用了递归的方法构建网络,其中的细节就涉及到算法层面的知识了,但是了解每一种算法的输入输出和整体框架搭建思路,先构建体系,再深入了解细节,注意实际上手和操练,还是很不错的学习过程。这些论文的讲解网上有一大堆,大家可以自行查阅,后续有时间可以对其中的细节进行单独的写作,但是本篇仅作为入门使用。
-
CPM -
Hourglass -
CPN -
MSPN -
HRNet:HRNet很经典,所以推一个B站的学习教程:
HRNet网络详解
https://www.bilibili.com/video/BV1bB4y1y7qP
以上都是经典的人体姿态估计网络,或许称之为经典的单人姿态估计网络,对于多人姿态估计,分为自顶向下和自底向上,代表作分别是AlphaPose和OpenPose。
-
自顶向下(top-down) :AlphaPose -
自底向上(bottom-up) :OpenPose。参考下面唐宇迪的讲解。
openpose教程人体姿态估计网络
https://www.bilibili.com/video/BV1JD4y1W7jZ
3.3 最新进展
看完这些经典的论文之后自然要有所比较,在数据集那个哪个最优,这一部分可以看上文提到的综述[2],里面有每个方法的亮点和每个数据集相应的精度。进一步的精度对比可以看这个网站paperswithcode,里面有所有最新算法在数据集上的精度比较,记录了论文和代码,非常方便来个示例图,:

链接如下:大家可以看最新的精度和效果在MSCOCO、MPII数据集上的榜单,从而对比自己正在阅读的论文和所做的工作有多大差距。
paperswithcode.com
https://paperswithcode.com/area/computer-vision/pose-estimation
截至写本文的时候,最好的是基于Transformer的ViTPose。《ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation》,讲解可参考下文:
论文阅读:ViTPose27
https://zhuanlan.zhihu.com/p/527877998
4. 3D姿态估计
4.0 必读论文总览
问题本质:
3D人体姿态估计是从图片或视频中估计出关节点的三维坐标 (x, y,z),它本质上是一个回归问题。
挑战:
(1)单视角下2D到3D映射中固有的深度模糊性与不适定性:因为一个2D骨架可以对应多个3D骨架,它具有在单视角下2D到3D映射中固有的深度模糊性与不适定性,这也导致了它本身就具有挑战性。
(2)缺少大型的室外数据集和特殊姿态数据集:这主要由于3D姿态数据集是依靠适合室内环境的动作捕捉(MOCAP)系统构建的,而MOCAP系统需要带有多个传感器和紧身衣裤的复杂装置,在室外环境使用是不切实际的。因此数据集大多是在实验室环境下建立的,模型的泛化能力也比较差。
研究方法:3D姿态估计受限于数据集和深度估计,大部分方法还是和2D姿态估计有着非常强的联系。
感兴趣的同学可以看一下这篇CSDN的博客,有个大致了解,下面的部分内容摘自其中。当然这篇里面的分类只是一种,大家参考综述[4]里面的配图9,也可以作为一种分类,不过大家注意每种分类方法,一些重要的文献总是归在同一类别的。
3D人体姿态估计论文汇总(CVPR/ECCV/ACCV/AAAI)
https://yongqi.blog.csdn.net/article/details/107625327
4.1 开山之作:(DconvMP)
《3D Human Pose Estimation from Monocular Images with Deep Convolutional Neural Network》,第一篇用卷及网络直接回归3D姿态的文章。

-
总结:网络框架包含两个任务:(1)a joint point regression task;(2)joint point detection tasks。 -
输入:包含human subjects的bounding box图片。 -
输出:N×3(N=17)关节坐标 -
数据集:Human3.6M; -
结果:MPJPE,使用Pearson correlation 和 LP norm探讨了DNN如何编码人体结构的依赖性与相关性。
4.2 必看论文
基于回归
[1]《3D Human Pose Estimation from Monocular Images with Deep Convolutional Neural Network》 (2014)
[2]《VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera》 (ACM-2017)
[3]《Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose》(CVPR-2017)
[4]《Integral Human Pose Regression》(CVPR-2018)
[5]《Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image》 (ICCV2019)
其中3-4-5是具有相关性的三篇论文
-
上述论文 [3](CVPR 2017)从2D图片中直接得到体素(Volumetric representation),而不是直接回归关节点的坐标,并取最大值的位置作为每个关节点的输出。体素是从2D姿态估计的heatmap学习而来,其实就是3D heatmap。
第一步:ConvNet直接回归生成关节体素(传统是直接回归3D坐标),用到了Hourglass;
第二步:采用从粗到细的Coarse-to-Fine预测策略。
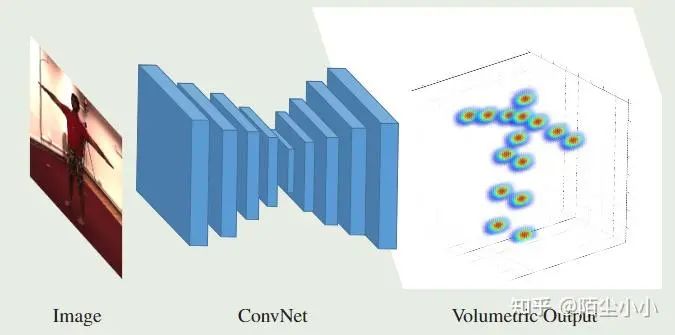
-
上述论文 [4] (ECCV 2018)是论文[3]的扩展工作,引入了积分回归(Integral Pose Regression)模块,也叫soft-argmax,将原先的取heatmap最大值对应的位置改成对heatmap求关节点的期望,使这一过程可微。全文就基于Integral Pose Regression模块做了大量的实验并验证其有效性,在3个数据集上分别实验成文。
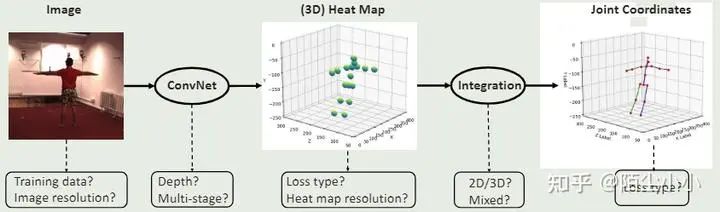
-
上述论文 [5] 是一个Top-Down的多人姿态估计,提出了一个模块化的整体结构:DetectNet+RootNet+PoseNet,DetectNet是目标检测网络,RootNet是本文重点,提出了一个深度估计方法,PoseNet借鉴了上述论文[4]的方法。论文代码在github分别提供了RootNet和PoseNet,便于实际项目应用.
https://github.com/mks0601/3DMPPE_POSENET_RELEASE
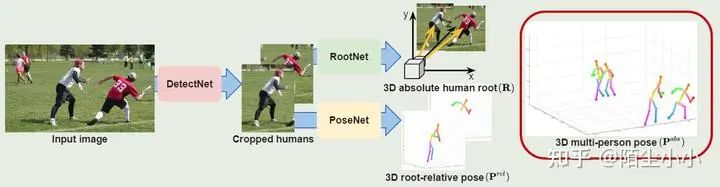
-
积分回归的代码讲解可以看我个人的B站视频,感兴趣的同学可以看一下。
ChatGPT助你理解积分人体姿态估计
https://www.bilibili.com/video/BV1oM411A79c
基于2D->3D
-
《3D Human Pose Estimation = 2D Pose Estimation + Matching》
总结:首先是做2D的人体姿态估计,然后基于Nearest neighbor最近邻的match来从training data中找最像的姿态。2D的姿态估计算法是基于CPM来做的。3D的match方法是KNN(https://blog.csdn.net/u010608296/article/details/120640343)方法,先把training data中的人体3d骨架投射到2D空间,然后把test sample的2d骨架跟这些training data进行对比,最后使用最相近的2d骨架对应的3D骨架当成最后test sample点3D骨架。当training数据量非常多的时候,这种方法可能可以保证比较好的精度,但是在大部分时候,这种匹配方法的精度较粗,而且误差很大。

-
SimpleBasline-3D:《A Simple Yet Effective Baseline for 3d Human Pose Estimation》
https://github.com/weigq/3d_pose_baseline_pytorch
论文动机:论文作者开头就提到,目前最先进的 3d 人体姿态估计方法主要集中在端到端(直接回归)的方法,即在给定原始图像像素的情况下预测 3d 关节位置。尽管性能优异,但通常很难理解它们的误差来源于 2d姿态估计部分过程(visual),还是将 2d 姿势映射到 3d关节的过程。因此,作者将 3d 姿态估计解耦为2d 姿态估计和从2d 到 3d 姿态估计(即,3D姿态估计 = 2D姿态估计 + (2D->3D)),重点关注 (2D->3D)。所以作者提出了一个从2D关节到3D关节的系统,系统的输入是 2d 个关节位置数组,输出是 3d 中的一系列关节位置,并将其误差降到很低,从而证明3D姿态估计的误差主要来源于图像到2D姿态的过程,即视觉理解(visual)的过程。

同样,从这个工作的名字可以看出,这个工作提出了一个比较simple的baseline,但是效果还是非常明显。方法上面来讲,就是先做一个2d skeleton的姿态估计,方法是基于Hourglass的,文章中的解释是较好的效果以及不错的速度。基于获得的2d骨架位置后,后续接入两个fully connected的操作,直接回归3D坐标点。这个做法非常粗暴直接,但是效果还是非常明显的。在回归之前,需要对坐标系统做一些操作。
基于时序(视频序列)
-
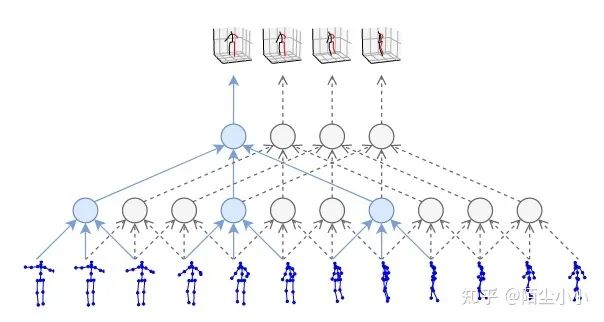
VideoPose3D:《3D human pose estimation in video with temporal convolutions and semi-supervised training》
利用这篇是利用视频做姿态估计的比较经典的论文,使用了多帧的图像来估计姿态,直觉上应该比单帧姿态估计要更加准确。两个贡献:
1. 提出了一种基于2D关节点轨迹的空洞时域卷积方法,简单、有效的预测出视频中的3D人体姿态;
2. 引入了一种半监督的方法,它利用了未标记的视频,并且在标记数据稀缺的情况下是有效的。

4.3 最新进展
关于最新进展,大家同样可以在paperswithcode网站去关注数据集Human3.6的榜单。
下面这个榜单是没使用2DGT数据集的:
monocular-3d-human-pose-estimation
https://paperswithcode.com/task/monocular-3d-human-pose-estimation
下面这个榜单是使用2DGT数据集:
Human3.6M Benchmark (3D Human Pose Estimation)
https://paperswithcode.com/sota/3d-human-pose-estimation-on-human36m
5. 3D形态重建(SMPL)
5.0 必读论文总览
3D形态估计是一个更新的任务,旨在恢复人体的三维网格,我的研究课题正好与此相关。研究这个方向的同学应该并不陌生,但是这里我们只介绍有关于SMPL的内容,再次推荐之前提到的综述论文[5] Recovering 3D Human Mesh from Monocular Images: A Survey(2022.03),里面的总结也是非常全的,截止2022年论文如下图所示:

其论文可以归类为两类型:
-
Optimization-based Paradigm 基于优化: Optimization-based approaches attempt to estimate a 3D body mesh that is consistent with 2D image observations.( 2D keypoints, silhouettes, segmentations.)即根据2D检测结果优化生成3Dmseh。代表作:SMPLify(ECCV'2016).
https://smplify.is.tue.mpg.de/ -
Regression-based Paradigm 基于回归: Regression-based methods take advantage of the thriving deep learning techniques to directly process pixels.即使用深度学习技术直接处理图像像素生成3Dmesh。代表作:HMR(CVPR'2018).
https://akanazawa.github.io/hmr/ -
基于优化+回归。代表作: SPIN(ICCV'2019)(相当于HMR+SMPLify)
https://www.seas.upenn.edu/~nkolot/projects/spin/
5.1 开山之作:《Smpl: A skinned multi-person linear model》
这篇是Michael J. Black实验室的SMPL开山之作,后续的大部分SMPL方法等也是该实验出品,大部分SMPL相关论文均是这个研究所出来的。

-
核心思想就是将通过网络回归输出的姿态参数θ(_∈24×3_)和形态参数β(_∈10×1_)送入一个基础人体模板(Template mesh)T(_∈6480×3_),然后形成各种姿态和体型的人体姿态。 -
姿态参数控制(23+1)个关节点。与之前的3D关节点坐标回归不同,每个关节点由3个旋转参数控制,一共有23个,还有一个控制全局旋转,相当于根关节点(root),所以姿态参数θ共有[(23+1)×3]=72个参数; -
形态参数控制人的体型,每个参数分别控制包括高矮、胖瘦、身体的局部比例等。1.0版本共有10个参数,后来的1.1版本拓展到300个参数,但是影响明显的仍然是前10个; -
基本模板是个固定姿态的人体mesh,也就是[θ=0 和_β=0_ ]的情况,因此这个姿态也被称为“zero pose”[零姿态]。 -
SMPL还训练了一个关节矩阵J ,可以从生成的人体mesh映射得到23个人体关节点坐标(x,y,z),所以基于SMPL的方法通过J 得到关节点坐标和3Dpose的方法对比,例如评价指标MPJPE。 -
后续论文方法均是致力于恢复更准确的3D Human mesh. -
文章总结可参考下面的博文:
SMPL模型学习
https://www.cnblogs.com/sariel-sakura/p/14321818.html
5.2 必看论文
以下必读论文来自商汤OpenMMLAB实验室的mmhuman3d项目,与之前提到的mmpose3d类似:上面有很多总结、经典以及最新方法的实现和讲解,有框架,有代码,有教程,可快速复现,而且维护和更新也很块。
https://github.com/wmj142326/mmhuman3dgithub.com/wmj142326/mmhuman3d
[1] SMPLify(ECCV'2016):《Keep it SMPL: Automatic Estimation of 3D Human Pose and Shape from a Single Image》。
https://smplify.is.tue.mpg.de/
[2]SMPLify-X (CVPR'2019):《Expressive Body Capture: 3D Hands, Face, and Body from a Single Image》
https://smpl-x.is.tue.mpg.de/
[3]HMR(CVPR'2018) :《End-to-end Recovery of Human Shape and Pose》
https://link.zhihu.com/?target=https%3A//akanazawa.github.io/hmr/
[4] SPIN(ICCV'2019):《 Learning to Reconstruct 3D Human Pose and Shapevia Model-fitting in the Loop 》
https://www.seas.upenn.edu/~nkolot/projects/spin/
[5] VIBE(CVPR'2020):《 Video lnference for Human Body Pose and Shape Estimation》
https://github.com/mkocabas/VIBE
[6] HybrIK (CVPR'2021):《HybrIK: A Hybrid Analytical-Neural Inverse Kinematics Solution for 3D Human Pose and Shape Estimation》
https://jeffli.site/HybrIK/
[7] PARE (ICCV'2021):《PARE: Part Attention Regressor for 3D Human Body Estimation》
https://pare.is.tue.mpg.de/
[8] HuMoR (2021) :《3D Human Motion Model for Robust Pose Estimation》
[9] DeciWatch(ECCV'2022):《DeciWatch: A Simple Baseline for 10× Efficient 2D and 3D Pose Estimation》
https://ailingzeng.site/deciwatch
[10] SmoothNet (ECCV'2022):《SmoothNet:A Plug-and-Play Network for Refining Human Poses in Videos》
https://ailingzeng.site/smoothnet
[11] ExPose (ECCV'2020):《Monocular Expressive Body Regression through Body-Driven Attention》
https://expose.is.tue.mpg.de/
[12]BalancedMSE (CVPR'2022):《Balanced MSE for Imbalanced Visual Regression 》
https://sites.google.com/view/balanced-mse/home
对其中的部分论文作简要介绍:
-
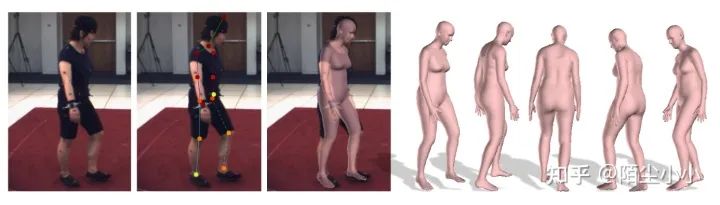
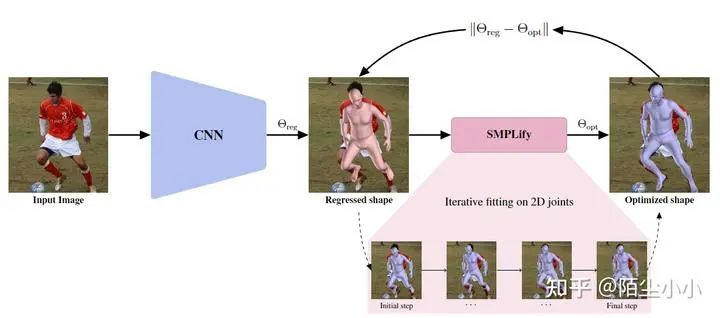
SMPLify:基于优化的方法。给定一个图像,使用基于 CNN 的方法来预测 2D 关节位置。然后将 3D 身体模型拟合到此,以估计 3D 身体形状和姿势。
https://smplify.is.tue.mpg.de/ -
SMPLify奠定了SMPL重建算法的基石,它从单张图像中重建人体的SMPL姿态; -
流程分为两步:1)单张图像经过DeepCutc恢复人体的2D关键点,2)然后利用2D关键点恢复SMPL姿态(这有点类似于2D->3D的提升); -
提出了SMPL重建的损失函数(objective function),由5部分组成,包括:a joint-based data term and several regularization terms including an interpenetration error term(这个互穿项在SPIN中舍弃了,因为它使得拟合变慢,而且性能并没有提高多少), two pose priors, and a shape prior.后续的方法基本都使用该损失函数或对其进行改进。
-
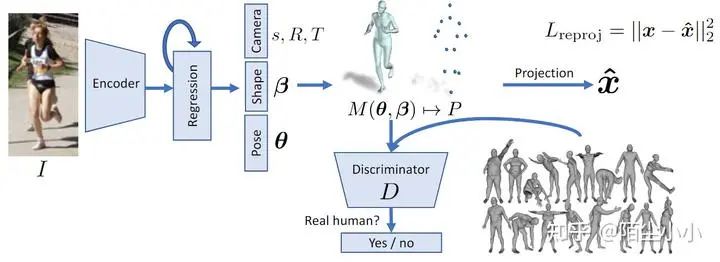
HMR:基于回归的方法。图像 I 通过卷积编码器传递。输入到迭代 3D 回归模块,该模块推断人类的潜在 3D 表示,以最小化联合重投影误差。3D 参数也被发送到鉴别器 D,其目标是判断这些参数是来自真实的人类形状和姿势。这里用到了GAN对抗生成网络。
https://akanazawa.github.io/hmr/
-
SPIN:基于优化+回归的方法。这篇文章主要是将基于迭代优化的方法(SMPLify)和基于网络回归的方法(HMR)进行结合。网络预测的结果作为优化方法的初始值,加快迭代优化的速度和准确性;迭代优化的结果可以作为网络的一个强先验。两种方法相互辅助,使整个方法有一种自我提升的能力,称之为SPIN(SPML oPtimization IN the loop)。
https://www.seas.upenn.edu/~nkolot/projects/spin/ -
SPIN算是HMR和SMPLify的结合,分别作为回归网络和优化网络,与SMPLify的区别(改进)如下:
-
SPIN舍弃了损失函数中的互穿项; -
SPIN使用HMR的回归结果作为初始化结果,然后迭代优化一次;SMPLif使用0姿态初始化,迭代优化了4次; -
SPIN使用HMR回归的相机参数,SMPLify使用了三角形相似; -
SPIN的2D关节点使用了OpenPose, SMPLify使用了DeepCut; -
SPIN提供了GPU并行处理图片,SMPLify延时较高不适合处理单张图像。
-
VIBE:[参考文章:https://zhuanlan.zhihu.com/p/397553879]基于视频帧的方法。提出了一个利用视频进行动作估计的新方法,解决了数据集缺乏和预测准确率不佳的问题。本文的主要创新之处在于利用对抗学习框架来区分真实人类动作和由回归网络生成的动作。本文提出的基于时间序列的网络结构可以在没有真实3D标签的情况下生成序列级合理的运动序列。这一思想借鉴了2018年提出的HMR模型,这项工作从单张图片重建人体模型,而本文则将这一模型由图片扩展到了视频,在原有模型基础上加入了GRU和motion discriminator。
https://github.com/mkocabas/VIBE

-
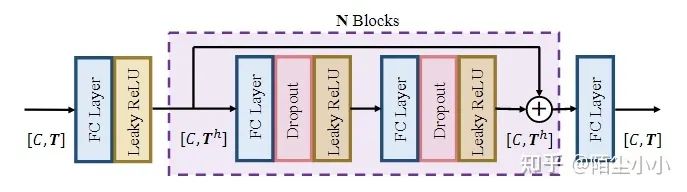
SmoothNet:解决姿态抖动问题。爱玲姐姐的佳作,解决3Dmesh的视频抖动问题。属于一个后处理操作,去抖动明显,只用了一个简单的全连接层设计,从位置、速度和加速度的三个量进行建模,进行了大量的试验证明其有效性。https://ailingzeng.site/smoothnet

作者有过一期视频讲解,链接放在这里,大家可以进一步听听,爱玲姐姐还讲了一些姿态的总结知识(人美声甜的大佬~):
【社区开放麦】第 14 期 从时间序列角度破解姿态估计中的两大问题
https://www.zhihu.com/zvideo/1534485957927075840
5.3最新进展:
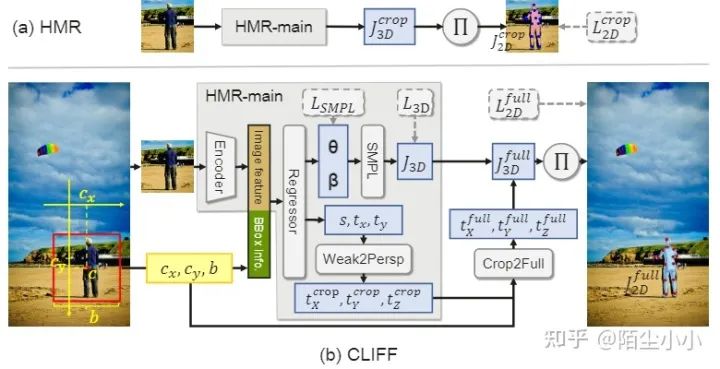
CLIFF(2022):《CLIFF: Carrying Location Information in Full Frames into Human Pose and Shape Estimation》
[参考链接:https://zhuanlan.zhihu.com/p/556885801]这篇是华为诺亚方舟出品。3D Human mesh中采用Top-Down策略的多人姿态估计。以极其优雅的方式,将原图的信息融合到人体姿态估计的神经网络的输入中,巨大提升了估计的准确度,刷到了3dpw的rank 1,并赢得了ECCV 2022的oral。正如参考的博文所说,他的处理方式极其优雅:
-
大部分的多人姿态估计都是对图像中的人体目标作裁剪然后运行单人姿态估计方法,这就缺失了每个人体目标在图像中的全局坐标信息; -
CLIFF在以HMR作为baseline的基础上,仅仅增加了3个输入, ,分别为bbox的中心相对于原图中心的距离以及bbox的大小; -
即考虑了人体目标在全局图像的信息作为监督,直觉上自然会有更多的监督信息,自然也就会得到更高的精度。最重要的是,这种处理方式就是看起来相当的......优雅! -
原论文提供的Github源码貌似只有demo,不过好在mmlab代码仓库已经支持支持了CLIFF,可前往查看Train源码。
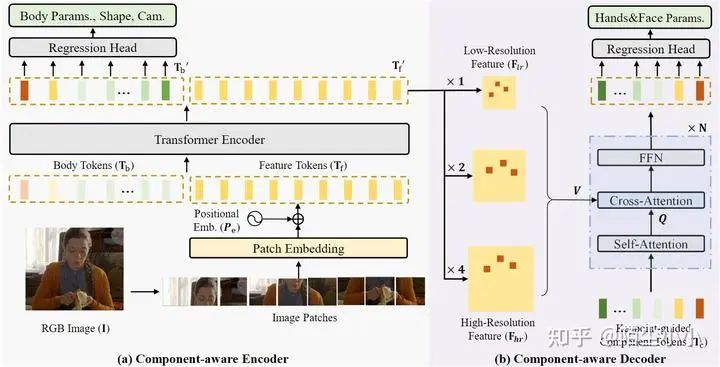
OSX(CVPR2023-IDEA)《One-Stage 3D Whole-Body Mesh Recovery with Component Aware Transformer》, 2023年CVPR的最新文章,提供了一个Ubody上身数据集。个人感觉,这是个“大团队+工作量+SOTA”的结果。
-
大团队包括“清华大学和IDEA研究院”,也有港中文大学参与,二作是我前面提到的女神曾爱玲姐姐; -
工作量包括全身关节点和mesh网格,而且制作了一个大数据集; -
SOTA结果,里面用到的算法主要是ViTPose, 基于Transformer的,算是最先进的算法了,当然本论文也取得了SOTA。

其他的最新进展,大家可以关注3DPW这个数据集的paperswithcode榜单。
https://paperswithcode.com/sota/3d-human-pose-estimation-on-3dpw?metric=MPJPE
6. 应用
那么,问题来了,关于HPE的方法,论文已经这么多了,最终它的应用场景是什么?学习这个领域,最终的目的也是工作,再好的方向跟不上工业界的需要也是瞎扯,闭门造车!这里写一些本人在学习和实习中的一些发现。
前情提要:本人硕士[现在是"菜博"了~:(],没有工作。但是有过相关实习,另外实验室也有相关的师兄弟从事这个方向,简单写一些所见所闻和个人感受,就当交流了,简单滴发表一些个人看法,后期发现说的不对了,再改hhhh~~。
6.1 学术研究
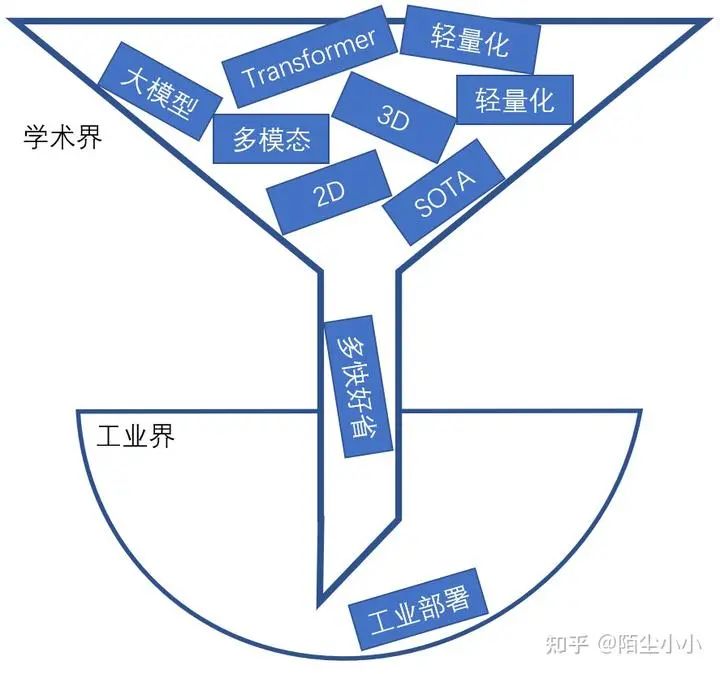
单纯的看姿态估计,它是一个基础任务,目的是从图像中获得信息,更重要的是如何利用这一部分信息,或者说用这一信息可以用在什么地方,所以这一任务在学术界是为其他任务提供数据支撑的,追求的是更高的精度,更快的速度,俗称“打榜”,更注重于方法研究。
现在的方法,层出不穷,但是个人认为,工业界的落地还是不多。学术界与工业界就像是一个狭窄的漏斗的两边,大量的方法研究堵在上头,却因为种种原因难以落地~
6.2 行为识别
自动驾驶的感知领域,行人行为识别、手势识别等是可以看得见的应用。但是,目前的自动驾驶好像并没有做到这一块,因为目前的自动驾驶还在“躲避障碍物”的阶段,检测任务还是应用的主流,行人的行为识别还存在比较远的路,精度、速度都是限制。
6.3 虚拟驱动
数字人、数字驱动、游戏建模,AR,VR,游戏和动画是目前的应用主流,这种限制场景下的姿态有实现的硬件基础;但是,单目的姿态估计感觉还是没有多视角的应用多,因为多一个摄像头不会花很多钱,还能提高精度;但是少一个摄像头的精度下降可能会带来体验感的下降。
6.4 感知皆可,格局打开
其实,人体姿态估计只是深度学习的一个任务罢了,它的基础知识,学习流程和其他的任务没有本质的区别,一通百通,手势的关节点不也是关键点吗?动物的关键点不也是关键点吗?只会一种任务适应不了时代的发展,我们学习的主要是一个领域,不要只把目光限制在“人体”和“姿态”,感知任务,皆可!
7. 总结
这些大概就是关于人体姿态估计入门需要学习的一些知识了,相信看完这些,HPE的体系架构可以建立个七七八八了,其他具体的一些算法层面的知识,大家可以基于这个框架体系流程逐步完善,网上的大佬教程也是相当之多,写此篇的目的:
一算整理,避免资源过多,学习凌乱;
二来帮助后人少走坑,尽量节省时间快速掌握;
三来也算自己的笔记整理,方便日后查询;
撰写过程中参考了很多平台、很多大佬的博文,部分可能没有参考引用,如有侵权,请及时联系我。其中不乏错误之处,也欢迎大家批评指正,私信交流!
公众号后台回复“数据集”获取100+深度学习各方向资源整理
极市干货
点击阅读原文进入CV社区
收获更多技术干货