
为什么说大模型微调是每个人都必备的核心技能?
架构之美
共 3634字,需浏览 8分钟
· 2023-11-01
▼最近直播超级多,预约保你有收获
近期直播:《基于开源 LLM 大模型的微调(Fine tuning)实战》
0 —
为什么要对 LLM 大模型进行微调(Fine tuning)?
— 1 —
如何对 LLM 大模型进行微调(Fine tuning)?
从参数规模的角度,对大模型进行微调(Fine tuning)有两条技术路线:
— 2 —
主流部分参数 PEFT 微调(Fine tuning)方案剖析
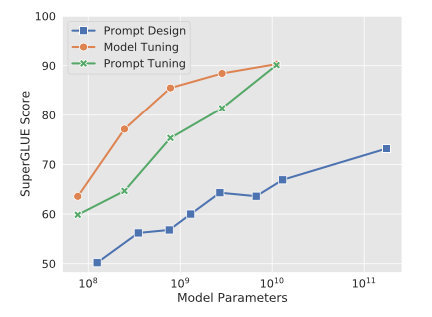
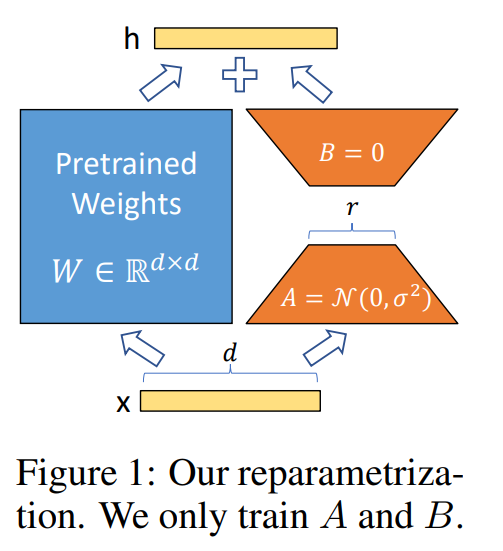
— 3—
免费超干货 LLM 大模型直播
为了帮助同学们掌握好 LLM 大模型的微调技术,本周日晚8点,我会开一场直播和同学们深度聊聊大模型的技术、分布式训练和参数高效微调,请同学点击下方按钮预约直播,咱们本周日晚8点不见不散哦~~
END
评论
【第129期】程序员的新宠:三款终端工具,让你告别Xshell!
概述 WindTerm:跨平台的SSH利器 首先介绍的是WindTerm,这是一款使用C语言开发的跨平台SSH客户端。它不仅完全免费,而且没有商业使用的限制。WindTerm支持SSH v2、Telnet、Raw Tcp等协议,而且性能出色,甚至超过了FinalShell和Electerm。功能
前端微服务
0
上班的时候,有一群摸鱼搭子非常重要...
上班的时候,有一群摸鱼搭子非常重要!一到上班时间,他们就从四面八方涌进群里冒泡...从八卦聊到股市、从职场聊到乌X兰局势,偶尔还会复读、相亲、battle...然后,下午6点钟准时消失不见...所以你要不要加入我们一起摸鱼?我们有北京、上海、深圳、广州、杭州、武汉、成都、南京等8个城市的摸鱼群,还有
产品经理日记
0
周四002 瑞超:同样落寞的境遇——北雪平vs埃尔夫斯堡
上赛季最终排名联赛第9的北雪平本赛季伊始表现不佳,4轮战罢他们仅以1胜1平2负的战绩排在倒数第三,这支历史上曾夺得13次联赛冠军、6次杯赛冠军老牌劲旅,正如英格兰赛场上的一众百年俱乐部,在低谷中不断探索着出路。球队主教练安德烈亚斯·阿尔姆曾是AIK索尔纳及赫根队的主教练,他于今年年初刚刚拿起球队教鞭
产品与体验
0
知乎高问:程序员有必要知道为什么做某个功能吗?
将Python客栈设为“星标⭐”第一时间收到最新资讯前言知乎上有一个提问:程序员有必要知道为什么做某个功能吗?↓↓↓今天,我们就这个话题一起来做个讨论。不知道程序员的你,在接到产品经理提的一个需求后,是习惯马上动手开始撸代码呢?还是会先暂停一下,认真思考一会如下一些问题,比如这个需求产生的背景是什么
Python客栈
0
日本影山优佳最新杂志照,展现充满透明感的美丽
今天的图文分享的是影山优佳的杂志写真。元日向坂46的影山优佳,登上了写真杂志《周刊FLASH》5/7和5/14合并号的封面。影山优佳是日本艺人、女演员、前偶像。身高155厘米。2001年5月8日出生于东京都。2023年7月从组合日向坂46毕业,之后作为演员活跃的影山优佳,在《周刊FLAS
python教程
0
盘点一个使用超级鹰识别验证码并自动登录的案例
点击上方“Python共享之家”,进行关注回复“资源”即可获赠Python学习资料今日鸡汤江上几人在,天涯孤棹还。大家好,我是皮皮。一、前言前几天在Python钻石交流群【静惜】问了一个Python实现识别验证码并自动登录的问题,提问截图如下:验证码的截图如下所示:二、实现过程这里大家激烈的探讨,【
IT共享之家
0
朋友,你也不想一个人孤孤单单的上班吧?
上班的时候,有一群摸鱼搭子非常重要!一到上班时间,他们就从四面八方涌进群里冒泡...从八卦聊到股市、从职场聊到乌X兰局势,偶尔还会复读、相亲、battle...然后,下午6点钟准时消失不见...所以你要不要加入我们一起摸鱼?我们有北京、上海、深圳、广州、杭州、武汉、成都、南京等8个城市的摸鱼群,还有
产品经理日记
0