
使用Python指定列提取连续6位数据的单号(中篇)
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是皮皮。
一、前言
前几天在Python最强王者交流群【哎呦喂 是豆子~】问了一个Python数据提取的问题,一起来看看吧。
大佬们请问下 指定列提取连续6位数据的单号(该列含文字、数字、大小写字母等等),连续数字超过6位、小于6位的数据不要,这个为啥有的数据可以提取 有的就提取不出来?
上一篇文章大家激烈探讨,但是暂时还没有找到更好的思路,这一篇文章我们继续沿着上篇文章的讨论,来看看吧!
二、实现过程
这里【猫药师Kelly】给了一个思路,使用C老师帮忙助力,每次只提取一种模式,然后update合并。
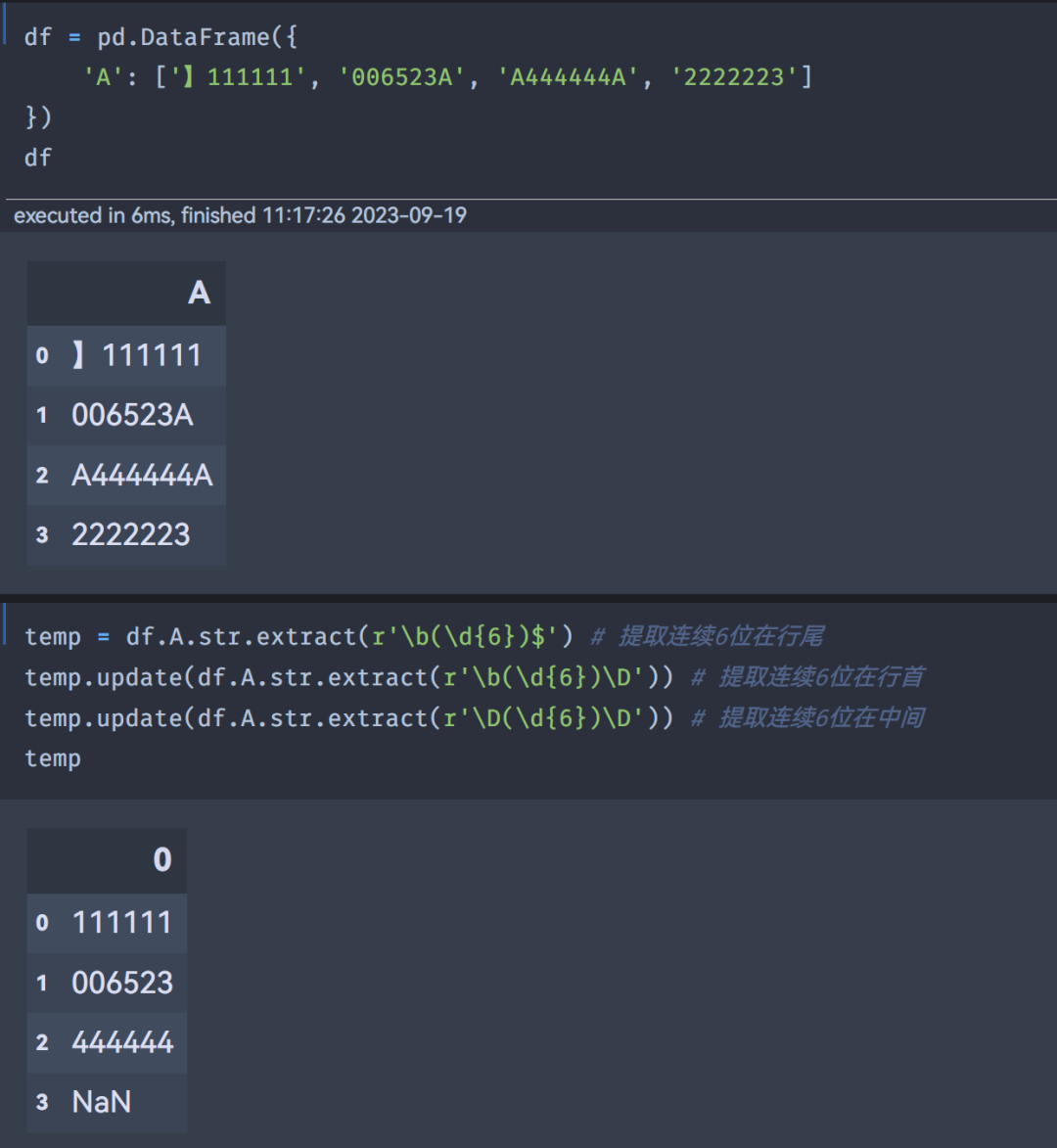
相当于把每行所有可能列出来,之后再合并。
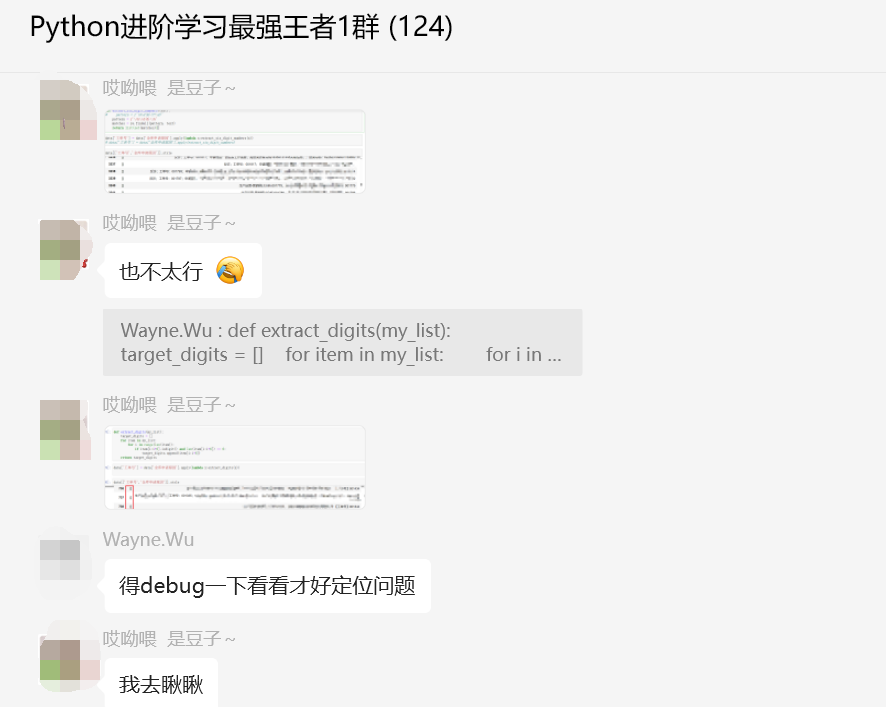
后来【Wayne.Wu】给了一个代码,如下所示:
def extract_digits(my_list):
target_digits = []
for item in my_list:
for i in range(len(item)):
if item[i:i+6].isdigit() and len(item[i:i+6]) == 6:
target_digits.append(item[i:i+6])
return target_digits
my_list = ['abc123', '123456', 'xyz789', '9876543', '12qw345', '12345678']
target_digits = extract_digits(my_list)
print(target_digits)
不过看上去也还差了一点点,需要改进下。
后来【郑煜哲·Xiaopang】也给了一个思路,如下所示:
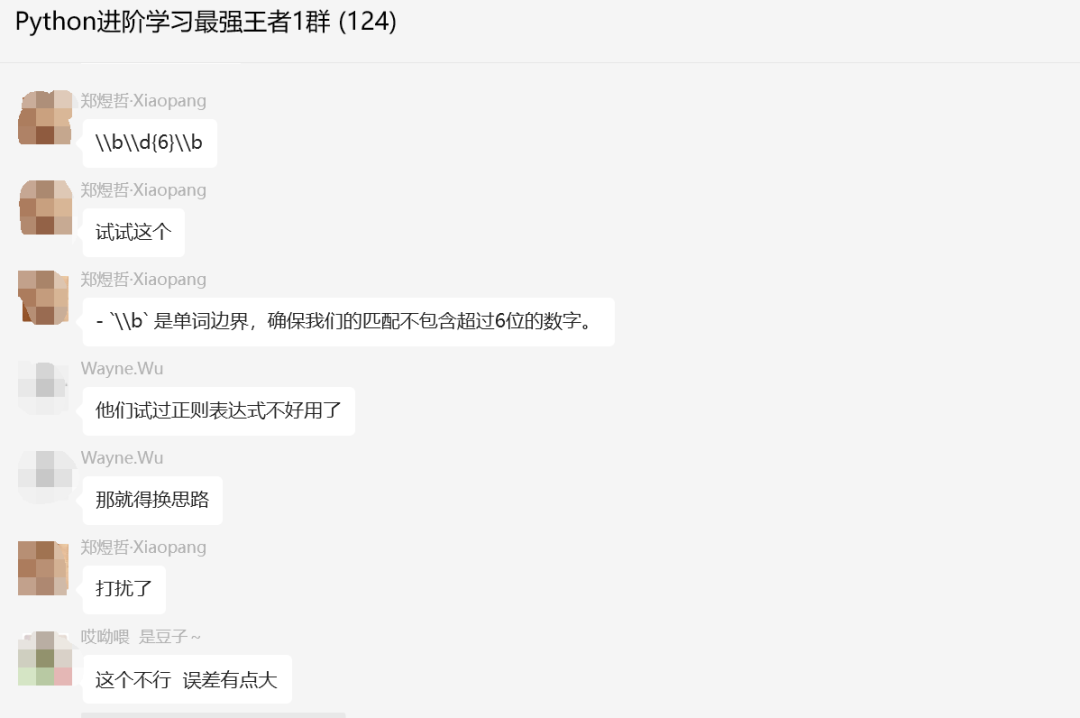
不过可惜的是正则表达式不太好用,误报比较大,现在得换思路。【Wayne.Wu】提出多正则表达式匹配规则助力。
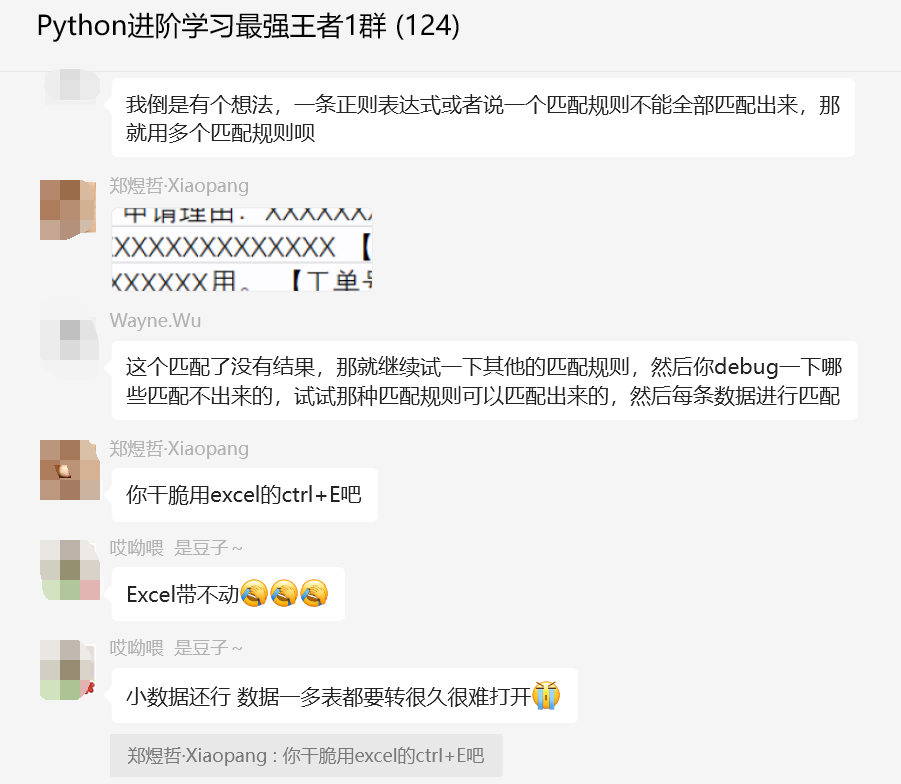
【黑科技·鼓包】也给了一个思路,如下所示:
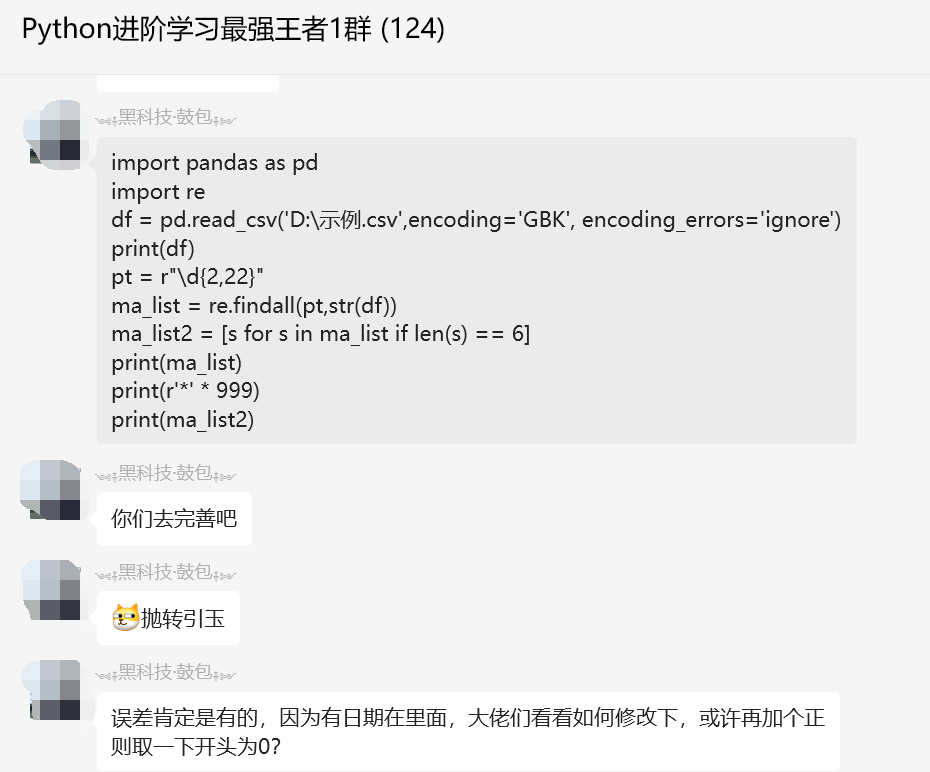
不过还是存在了点问题。后来【瑜亮老师】也给了一个思路和代码,如下所示:
df = pd.read_csv('示例.csv', encoding='gbk')
pattern = r'\D(\d{6})(?=\D|$)'
df['提取单号'] = df['理由'].map(lambda x: re.findall(pattern, x)[0] if len(re.findall(pattern, x)) >= 1 else 0)
print(df)
代码运行后可以得到下图的预期结果:
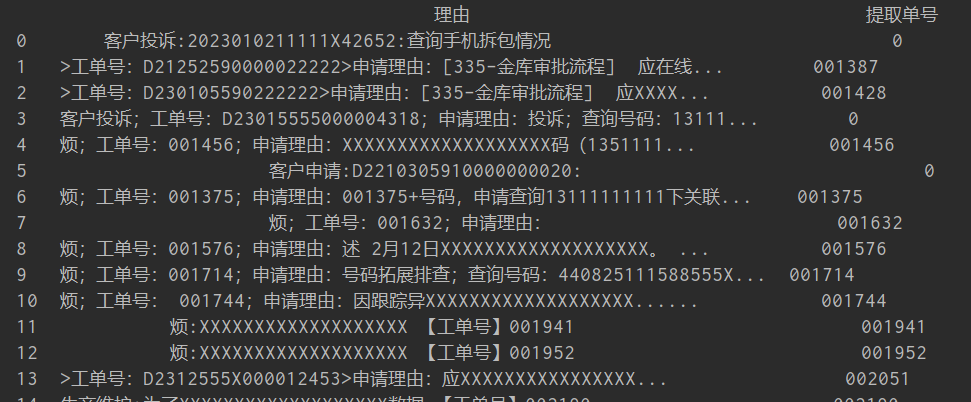
不过还留了一点点小尾巴,下一篇文章一起来看看吧!
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python正则表达式数据提取的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【哎呦喂 是豆子~】提问,感谢【瑜亮老师】、【猫药师Kelly】、【隔壁😼山楂】、【Wayne.Wu】、【郑煜哲·Xiaopang】给出的思路和代码解析,感谢【黑科技·鼓包】、【巭孬🕷】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting1),应粉丝要求,我创建了一些ChatGPT机器人交流群和高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~