 小白学视觉
小白学视觉




点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

要点:仅需要8M额外的训练参数,就可以利用冻结的CLIP模型实现15帧每秒的开放词汇语义分割,同时性能相较STOA大幅度提升。
Code: https://github.com/MendelXu/SAN

图1 SAN的可视化结果

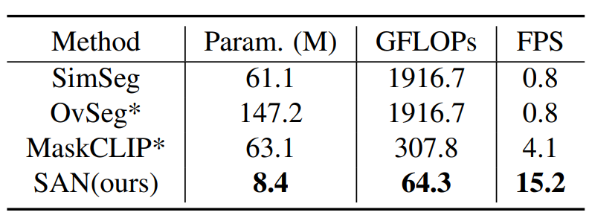
表 2 推理速度与可训练参数量的比较。
开放词汇语义分割算法通常基于以CLIP为代表的VL预训练模型。然而,这些VL预训练模型通常是在图片级任务上训练的,因此不具备像素级识别能力。为了克服图片级识别与像素级识别的粒度鸿沟(Granularity Gap),此前的开放词汇语义分割算法[1,3]会采用以下策略:
1.对VL预训练模型进行微调,通过改变其网络权重,使其具备像素级识别能力。该策略的缺点在于:微调模型权重会导致VL预训练模型的开放词汇识别能力受到伤害。
2.将开放语义分割问题拆解为两个阶段:第一阶段提取Mask Proposals,第二阶段使用CLIP对每个Mask Proposals进行识别。该策略可以在一定程度上绕开粒度鸿沟的挑战,但其缺点在于CLIP需要对每个Mask Proposal单独提取特征,计算代价十分巨大,并且第一阶段提取的Mask Proposal并不一定适合CLIP的分类。
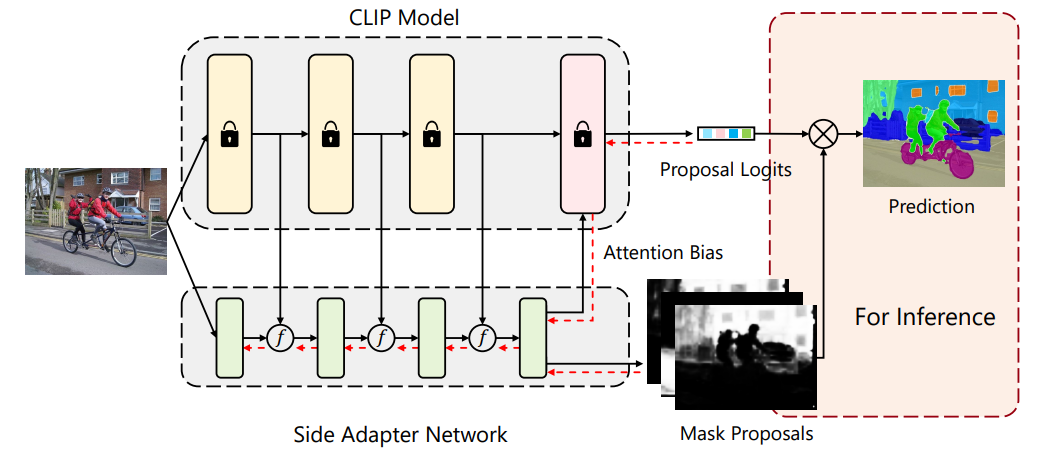
图2 SAN的架构示意图
具体来说,Side Adapter Network包含以下几个关键技术:
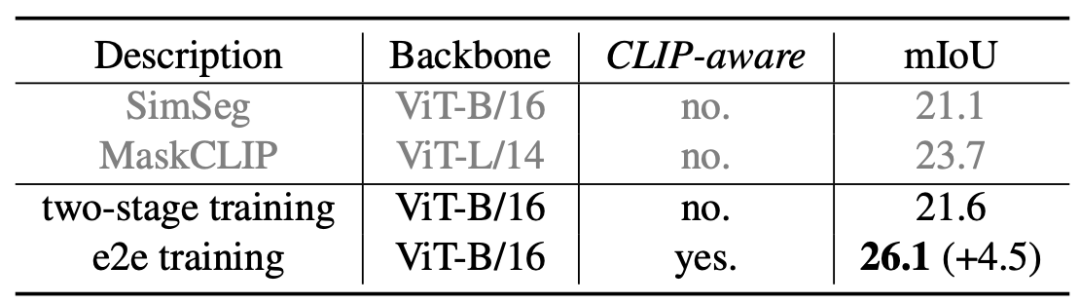
表 3 端到端训练的有效性
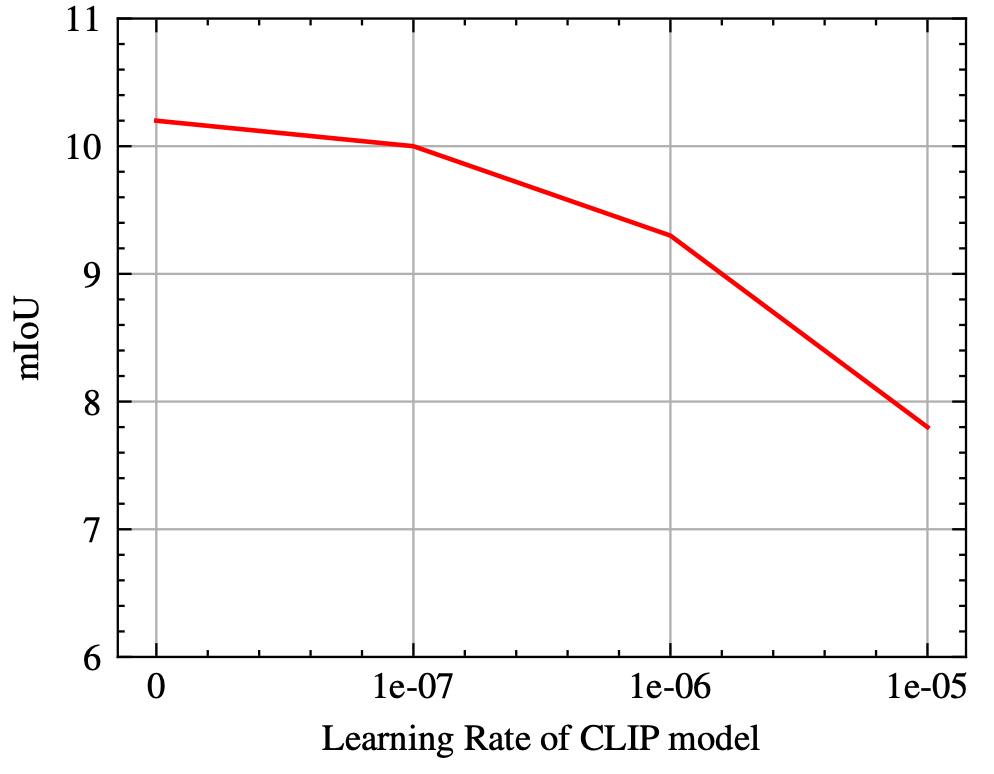
图3 微调(Fine-tune) CLIP模型的参数会伤害其开放词汇识别能力。
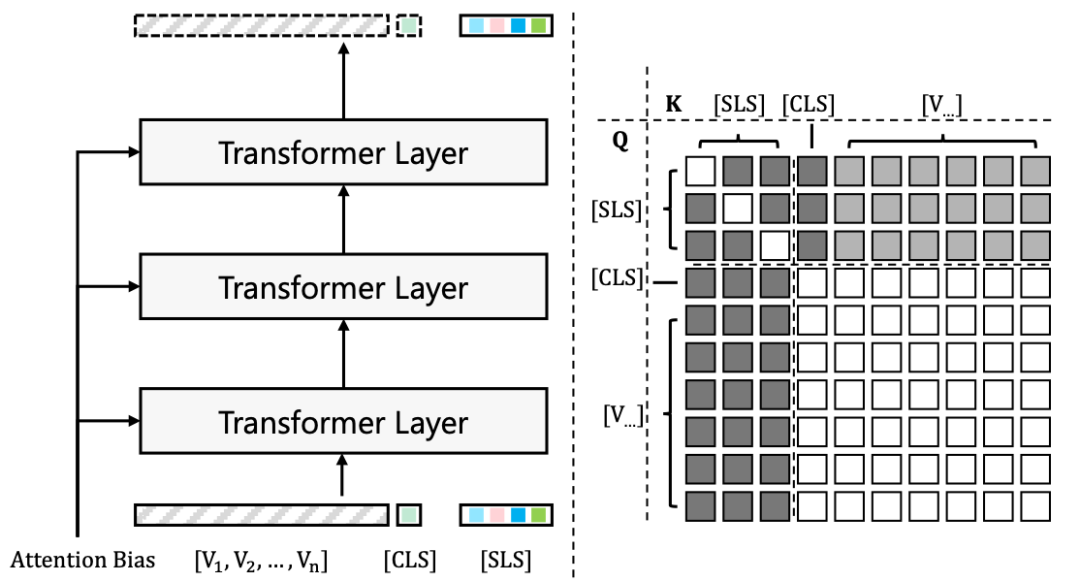
图4 [SLS] Token通过修改Attention Bias实现对Mask Proposals的高效识别。

表 4 掩码预测与类别预测解耦的设计带来更好的性能。
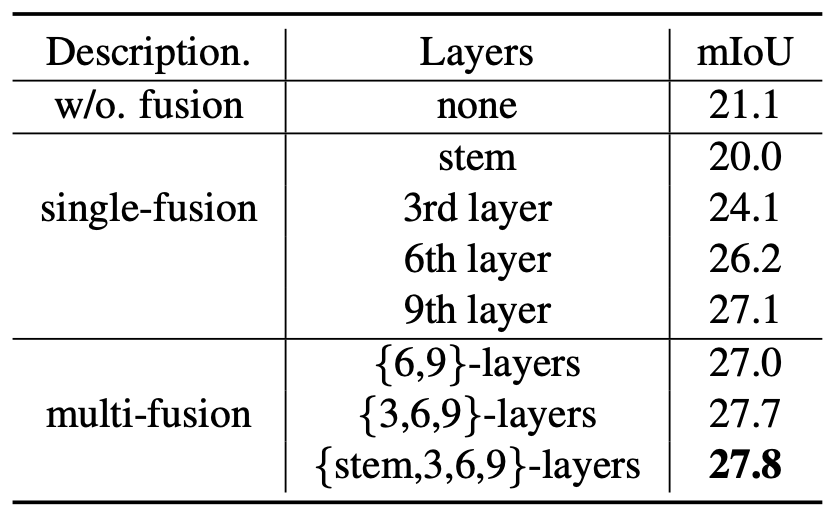
表5 复用CLIP模型的特征可以显著提升性能。
目前SAN的代码均已开源。
[1] A Simple Baseline for Open-Vocabulary Semantic Segmentation with Pre-trained Vision-language Model, ECCV,2022
[2] Open-Vocabulary Panoptic Segmentation with MaskCLIP, Arxiv, 2022
[3] Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP, CVPR2023
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~



