
再见,Elasticsearch !
共 5048字,需浏览 11分钟
· 2023-09-19
点击关注公众号:互联网架构师,后台回复 2T获取2TB学习资源!
新一代搜索引擎,是ES的15倍,号称干翻ES!
Manticore Search 是一个使用 C++ 开发的高性能搜索引擎,创建于 2017 年,其前身是 Sphinx Search 。
Manticore Search 充分利用了 Sphinx,显着改进了它的功能,修复了数百个错误,几乎完全重写了代码并保持开源。这一切使 Manticore Search 成为一个现代,快速,轻量级和功能齐全的数据库,具有出色的全文搜索功能。
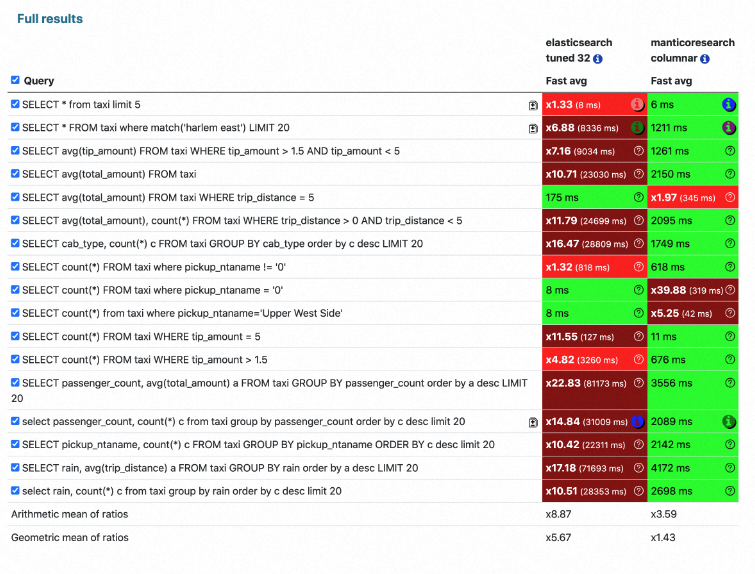
在一定的场景中,Manticore 比 Elasticsearch 快 15 倍!完整的测评结果,可以参考:
https://manticoresearch.com/blog/manticore-alternative-to-elasticsearch/
优势
它与其他解决方案的区别在于:
-
它非常快,因此比其他替代方案更具成本效益。例如,Manticore:
-
对于小型数据,比MySQL快182倍(可重现) -
对于日志分析,比Elasticsearch快29倍(可重现) -
对于小型数据集,比Elasticsearch快15倍(可重现) -
对于中等大小的数据,比Elasticsearch快5倍(可重现) -
对于大型数据,比Elasticsearch快4倍(可重现) -
在单个服务器上进行数据导入时,最大吞吐量比Elasticsearch快最多2倍(可重现) -
由于其现代的多线程架构和高效的查询并行化能力,Manticore能够充分利用所有CPU核心,以实现最快的响应时间。
-
强大而快速的全文搜索功能能够无缝地处理小型和大型数据集。 -
针对小、中、大型数据集提供逐行存储。 -
对于更大的数据集,Manticore通过Manticore Columnar Library提供列存储支持,可以处理无法适合内存的数据集。 -
自动创建高效的二级索引,节省时间和精力。 -
成本优化的查询优化器可优化搜索查询以实现最佳性能。 -
Manticore是基于SQL的,使用SQL作为其本机语法,并与MySQL协议兼容,使您可以使用首选的MySQL客户端。 -
通过PHP、Python、JavaScript、Java、Elixir和Go等客户端,与Manticore Search的集成变得简单。 -
Manticore还提供了一种编程HTTP JSON协议,用于更多样化的数据和模式管理。 -
Manticore Search使用C++构建,启动快速,内存使用最少,低级别优化有助于其卓越性能。 -
实时插入,新添加的文档立即可访问。 -
提供互动课程,使学习轻松愉快。 -
Manticore还拥有内置的复制和负载均衡功能,增加了可靠性。 -
可以轻松地从MySQL、PostgreSQL、ODBC、xml和csv等来源同步数据。 -
虽然不完全符合ACID,但Manticore仍支持事务和binlog以确保安全写入。 -
内置工具和SQL命令可轻松备份和恢复数据。
Craigslist、Socialgist、PubChem、Rozetka和许多其他公司使用 Manticore 进行高效搜索和流过滤。
使用
Docker 镜像可在Docker Hub上获取:
https://hub.docker.com/r/manticoresearch/manticore/
要在 Docker 中试验 Manticore Search,只需运行:
docker run -e EXTRA=1 --name manticore --rm -d manticoresearch/manticore && until docker logs manticore 2>&1 | grep -q "accepting connections"; do sleep 1; done && docker exec -it manticore mysql && docker stop manticore之后,可以进行其他操作,例如创建表、添加数据并运行搜索:
create table movies(title text, year int) morphology='stem_en' html_strip='1' stopwords='en';insert into movies(title, year) values ('The Seven Samurai', 1954), ('Bonnie and Clyde', 1954), ('Reservoir Dogs', 1992), ('Airplane!', 1980), ('Raging Bull', 1980), ('Groundhog Day', 1993), ('<a href="http://google.com/">Jurassic Park</a>', 1993), ('Ferris Bueller\'s Day Off', 1986);select highlight(), year from movies where match('the dog');select highlight(), year from movies where match('days') facet year;select * from movies where match('google');完整文档和开源代码,可以移步:
https://github.com/manticoresoftware/manticoresearch
最后,关注公众号互联网架构师,在后台回复:2T,可以获取我整理的 Java 系列面试题和答案,非常齐全。
正文结束
推荐阅读 ↓↓↓

正文结束