
Pandas实战——灵活使用pandas基础知识轻松处理不规则数据
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是皮皮。
一、前言
前几天在Python最强王者群【wen】问了一个pandas数据合并处理的问题,一起来看看吧。他的原始数据如下所示:
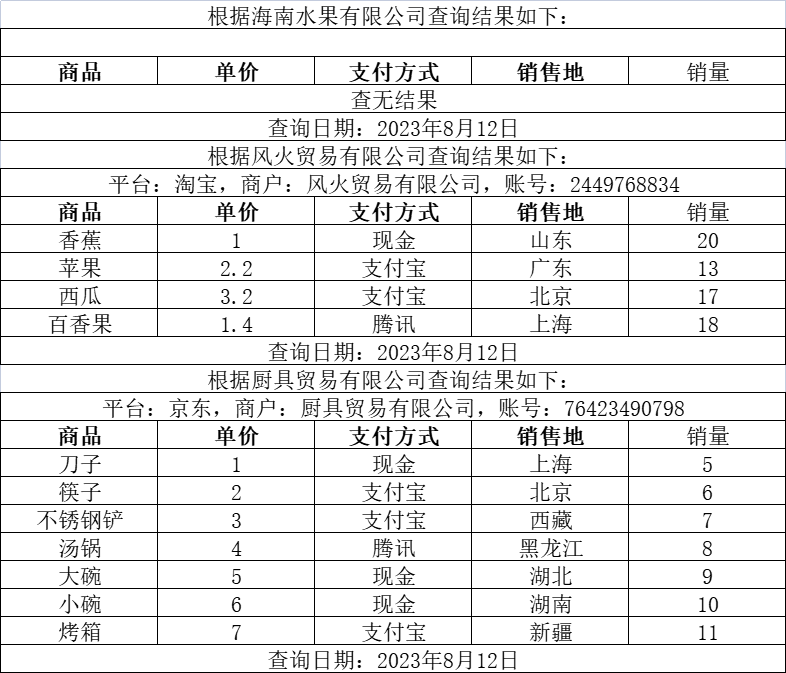
然后预期的结果如下所示:
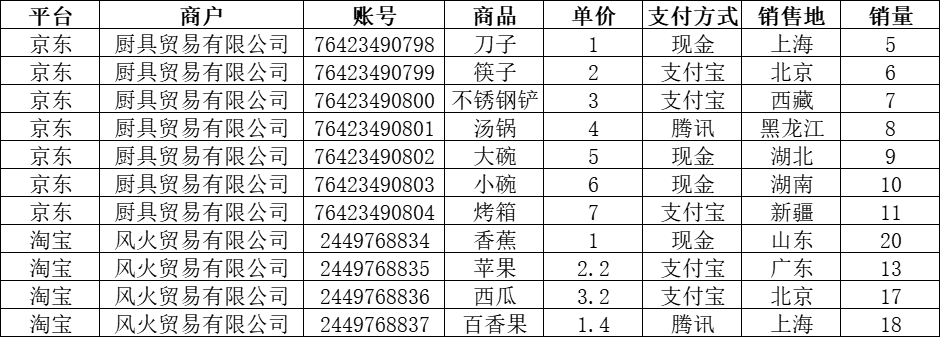
二、实现过程
这里【瑜亮老师】给了一个指导如下:原始数据中包含所有所需的信息,但是因为源系统导出的格式问题,有些数据被分配到了合并行中,并且每个单独的表中都是统一格式。
源数据中'商品', '单价', '支付方式', '销售地', '销量'是已经处理好的数据,不需要单独处理。需要获取的信息是'平台', '商户', '账号',这三个均在合并行中,群友的建议都是使用re正则表达式获取。
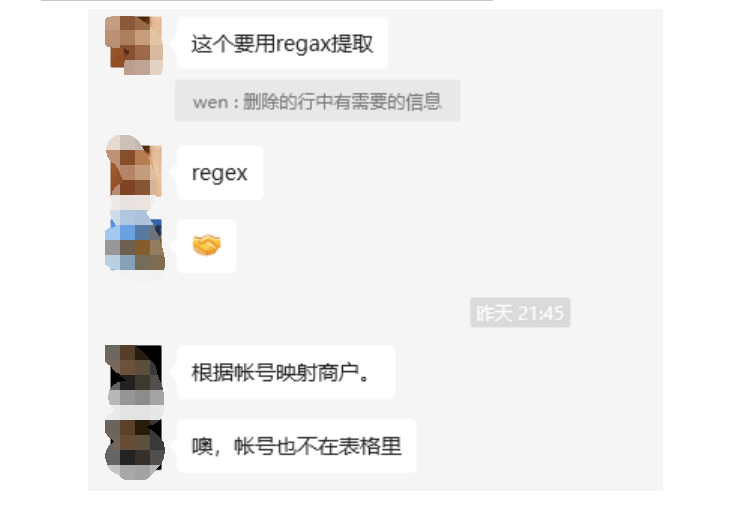
获取到上面数据后,还需要删掉多余的行。仔细观察原始表格我们可以发现:每个单独表格是由一个平台、商户、账号所查询的,且所需平台、商户、账号数据分布在合并行中,而这些合并行在被pandas读取后会形成只有第一列有数值,其他列为NaN的情况。
处理过后的格式情况如下:
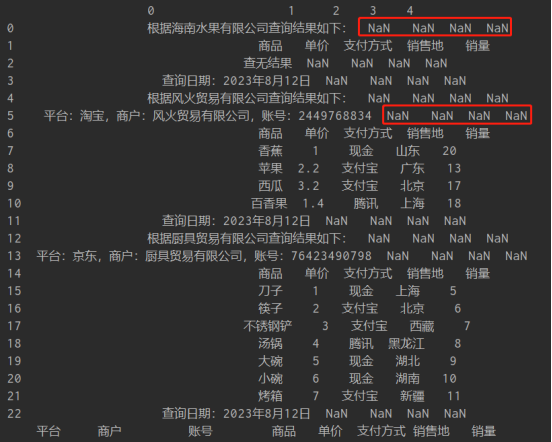
这就给了我们去掉这些合并行的简便方法:dropna。
而用正则获取到的平台、商户、账号只有一行,需要对数据进行向下填充空值。而pandas中fillna(method='ffill')即可实现使用前值去填充下面空值的需求。最后,瑜亮老师出手,实现需求,代码如下:
import pandas as pd
# 读取Excel文件
df = pd.read_excel('20230812.xlsx', header=None)
# 去除重复行
df = df.drop_duplicates(ignore_index=False).reset_index(drop=True)
# 根据正则表达式获取“账号”,“平台”,“商户”
df['账号'] = df[0].str.extract(r'账号:(\d+)', expand=False).fillna(method='ffill')
df['平台'] = df[0].str.extract(r'平台:(.*?),', expand=False).fillna(method='ffill')
df['商户'] = df[0].str.extract(r'商户:(.*?),', expand=False).fillna(method='ffill')
# 去除含有空值的行(即excel中所有的合并行
df = df.dropna().reset_index(drop=True)
# 设置df的列名
df.columns = ['商品', '单价', '支付方式', '销售地', '销量', '账号', '平台', '商户']
df = df[['平台', '商户', '账号', '商品', '单价', '支付方式', '销售地', '销量']]
print(df)
代码运行后的结果如下:
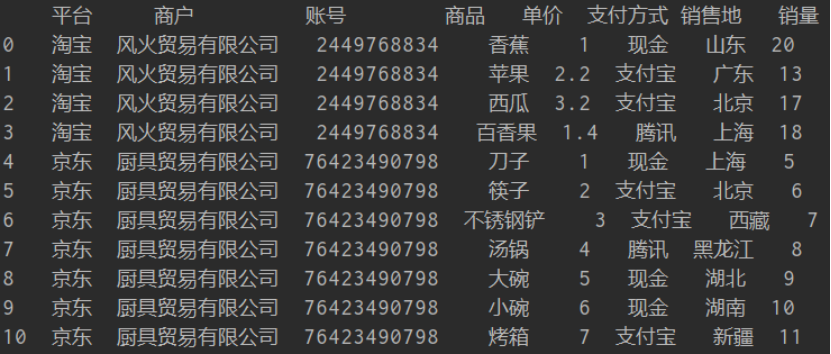
完美实现群友的需求!
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Pandas数据合并处理问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【wen】提问,感谢【瑜亮老师】给出的思路和代码解析,感谢【莫生气】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。

大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting1),应粉丝要求,我创建了一些ChatGPT机器人交流群和高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~