
起薪4万,百度AI产品&研发必懂深度学习实现原理框架(上)

这是求职产品经理系列的第171篇文章
近期有很多社招和校招想要做AI产品经理的小伙伴,都在找我要AI产品经理相关算法的资料,所以老薛我趁周末加班赶工给大家写了两篇文章。
重点给大家分享深度学习的三个经典模型:CNN、RNN和GAN。会帮助大家深度理解当前火热的ChatGPT4.0底层的技术原理。
如果大家有更多想要了解的或者想直播现场找我咨询,可以直接预约周四的直播,如果已过期可以点击进入预约其他场次。
一、深度学习的前世今生
说到深度学习就不得不先提一个概念--机器学习。
机器学习是人工智能的分支,它专门研究计算机如何模拟和实现人类的学习行为。
在人工智能发展过程中,机器学习占据核心地位。通过各种模型,机器学习可以从海量的数据中习得规律,从而对新的数据做出智能识别或者预测,并且为决策提供支持。
而深度学习正是机器学习的一种。
如下图所示,人工智能是一个范围很大的概念,其中包括了机器学习,机器学习包括了深度学习。
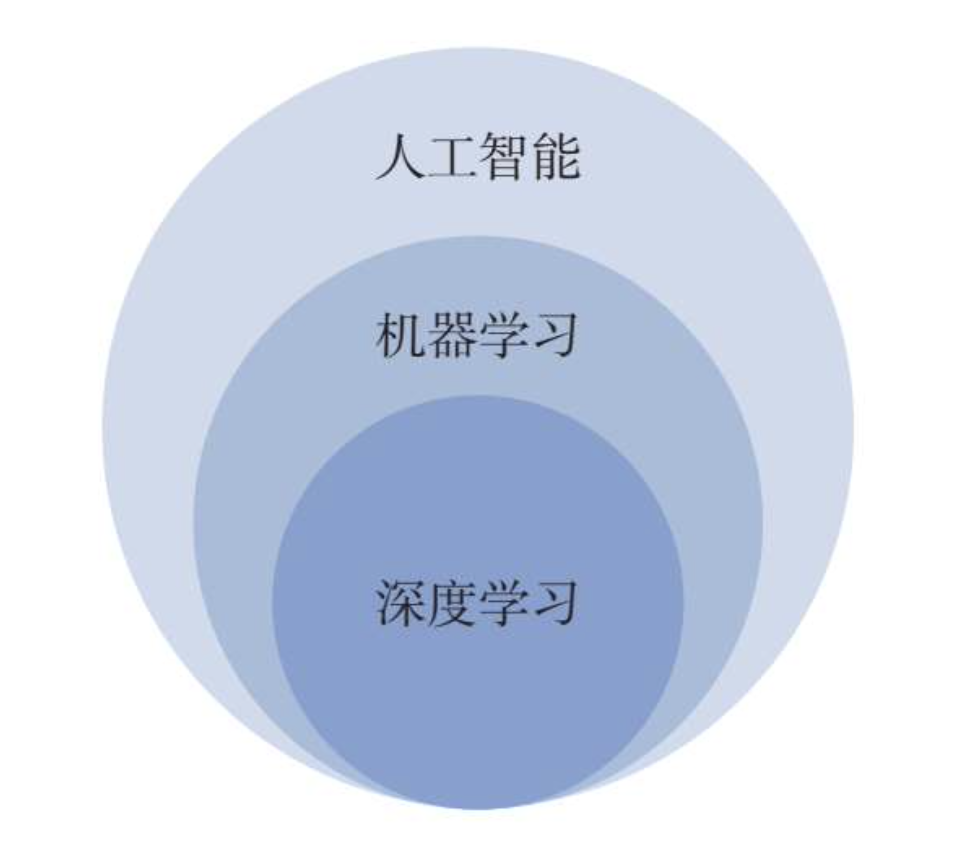
机器学习是人工智能提升性能的重要途径,而深度学习又是机器学习的重要组成部分。
深度学习解决了许多复杂的识别、预测和生成难题,使机器学习向前迈进了一大步,推动了人工智能的蓬勃发展。
那么深度学习又是如何发展起来的呢?
深度学习的概念最初起源于人工神经网络。科学家发现人的大脑中含有大约1000亿个神经元,大脑平时所进行的思考、记忆等工作,其实都是依靠神经元彼此连接而形成的神经网络来进行的。
人工神经网络是一种模仿人类神经网络来进行信息处理的模型,它具有自主学习和自适应的能力。
1943年,数学家皮茨(Pitts)和麦卡洛克(McCulloch)建立了第一个神经网络模型M-P模型,能够进行逻辑运算,为神经网络的发展奠定了基础。
生物神经元一共由四个部分组成:细胞体、树突、轴突和轴突末梢。M-P模型其实是对生物神经元结构的模仿,如下图所示:
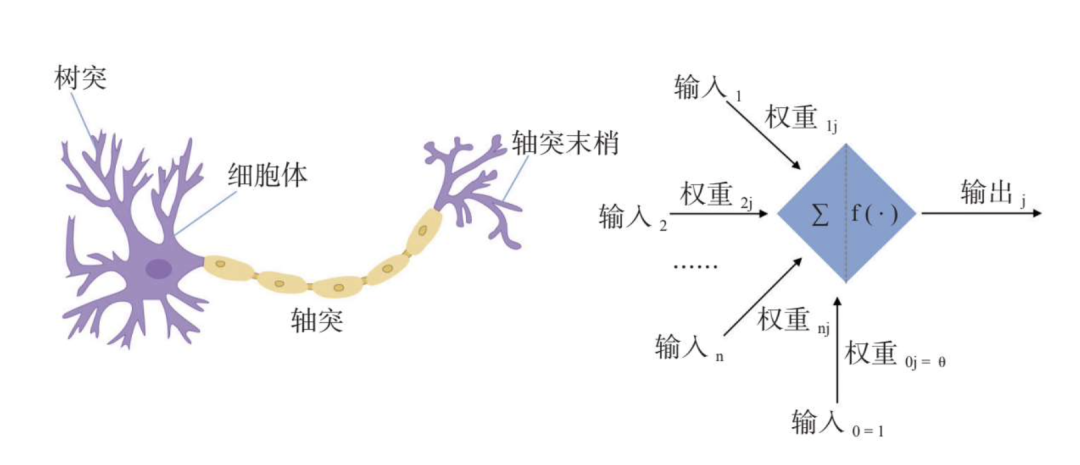
左边是生物神经元的示意图,右边是M-P模型的示意图。
为了建模更加方便简单,M-P模型将神经元中的树突、细胞体等接收到的信号都看作输入值,轴突末梢发出的信号视作输出值。
1958年,计算机科学家罗森布拉特发明了感知机,它分为三个部分:输入层、输出层和隐含层。
感知机能够进行一些简单的模式识别和联想记忆,是人工神经网络的一大突破,但这个感知机存在一个问题,就是无法对复杂的函数进行预测。
20世纪80年代,人工智能科学家拉姆梅尔哈特、威廉斯、辛顿、杨立昆(YannLeCun)等人发明的多层感知机解决了这个问题,推动了人工神经网络的进一步发展。
20世纪90年代,诺贝尔奖获得者埃德尔曼提出Darwinism模型并建立了一种神经网络系统理论。
他从达尔文的自然选择理论中获得启发,将其与大脑的思维方式联系在了一起,认为“面对未知的未来,成功适应的基本要求是预先存在的多样性”,这与我们现在谈论较多的模型训练和预测方式相契合,对90年代神经网络的发展产生了重大意义。
在这之后,神经网络技术再也没有出现过突破性的发展。
直到2006年,被称为“人工智能教父”的辛顿正式提出了深度学习的概念,认为通过无监督学习和有监督学习相结合的方式可以对现有的模型进行优化。

这一观点的提出在人工智能领域引起了很大反响,许多像斯坦福大学这样的著名高校的学者纷纷开始研究深度学习。2006年被称为“深度学习元年”,深度学习从这一年开始迎来了一个爆发式的发展。
2009年,深度学习应用于语音识别领域。
2012年,深度学习模型AlexNet在ImageNet图像识别大赛中拔得头筹,深度学习开始被视为神经网络的代名词。
同样是在这一年,人工智能领域权威学者吴恩达教授开发的深度神经网络将图像识别的错误率从26%降低到了15%,这是人工智能在图像识别领域的一大进步。

2014年,脸书开发的深度学习项目DeepFace在识别人脸方面的准确率达到了97%以上。
2016年,基于深度学习的AlphaGo在围棋比赛中战胜了韩国顶尖棋手李世石,在世界范围内引起轰动,这一事件不但使深度学习受到了认可,人工智能也因此被社会大众熟知。

2017年,深度学习开始在各个领域展开应用,如城市安防、医学影像、金融风控、课堂教学等,一直到最近的现象级产品ChatGPT,它在不知不觉中已经渗透到我们的生活中。
二、深度学习的经典模型
经过上面的介绍,我们知道了深度学习属于机器学习,也知道了深度学习是怎样从人工神经网络一步一步发展起来的。
那么,深度学习到底是什么呢?
深度学习是建立在计算机神经网络理论和机器学习理论上的科学,它使用建立在复杂网络结构上的多处理层,结合非线性转换方法,对复杂数据模型进行抽象,能够很好地识别图像、声音和文本。
下面,我们就来介绍两种深度学习的经典模型:CNN和RNN。
2.1 CNN
CNN的全称是convolutional neural network,也就是卷积神经网络。
对卷积神经网络的研究出现于20世纪80至90年代,到了21世纪,随着科学家们对深度学习的深入研究,卷积神经网络也得到了飞速的发展,该网络经常用于图像识别领域。
如下图所示,卷积神经网络共分为以下几个层级部分:输入层、卷积层、池化层、全连接层。
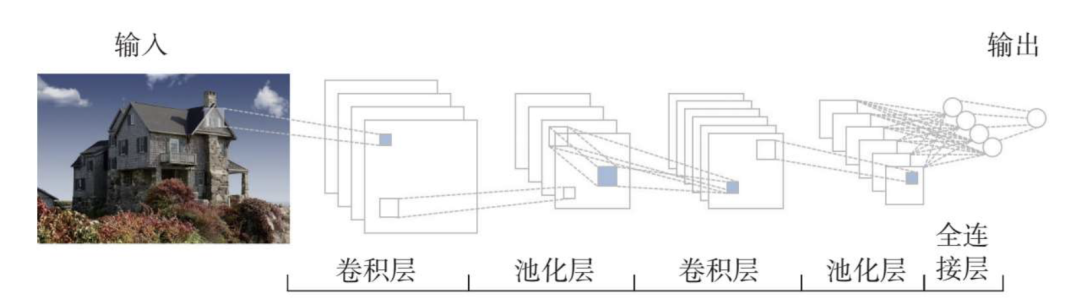
当图像进入输入层,模型会对这个图像进行一些简单的预处理,比如说降低图像维度,便于图像识别。
卷积层里的神经元会对图像进行各个维度的特征提取。这一提取动作不是针对原图像进行的,而是仅对图像的局部进行特征提取,比如说需要识别的是一张包含小狗的照片,神经元只负责处理这张照片中的一小部分,例如狗的耳朵、眼睛。
卷积层对图像进行不同尺度的特征提取,大大丰富了获取特征的维度,有助于提升最终识别的准确度。
池化就是对图像进行压缩降维,减少图像识别需要处理的数据量。
全连接层需要做的就是将前面所提取出来的所有图像特征连接组合起来,如下图,将提取到的小狗的头、身体、腿等局部特征组合起来,形成一个完整的包含小狗的特征向量,然后识别出类别。这就是卷积神经网络进行图像识别的全过程。

通过对卷积神经网络工作过程的梳理,我们可以总结出卷积神经网络的三个特性:
第一,图像识别不需要识别图像的全部,每个神经元只需要聚焦图像的一小部分,识别的难度降低;
第二,卷积层对应的神经元可以应用于不同的图像识别任务,比如上图中的神经元,经过训练,已经能够识别出小狗,那这些神经元也可以应用于识别其他任何图像中的相似物体;
第三,虽然图像特征的维度降低了,但是由于保留了图像的主要特征,所以并不影响图像识别,反而减少了识别图像需要处理的数据量。
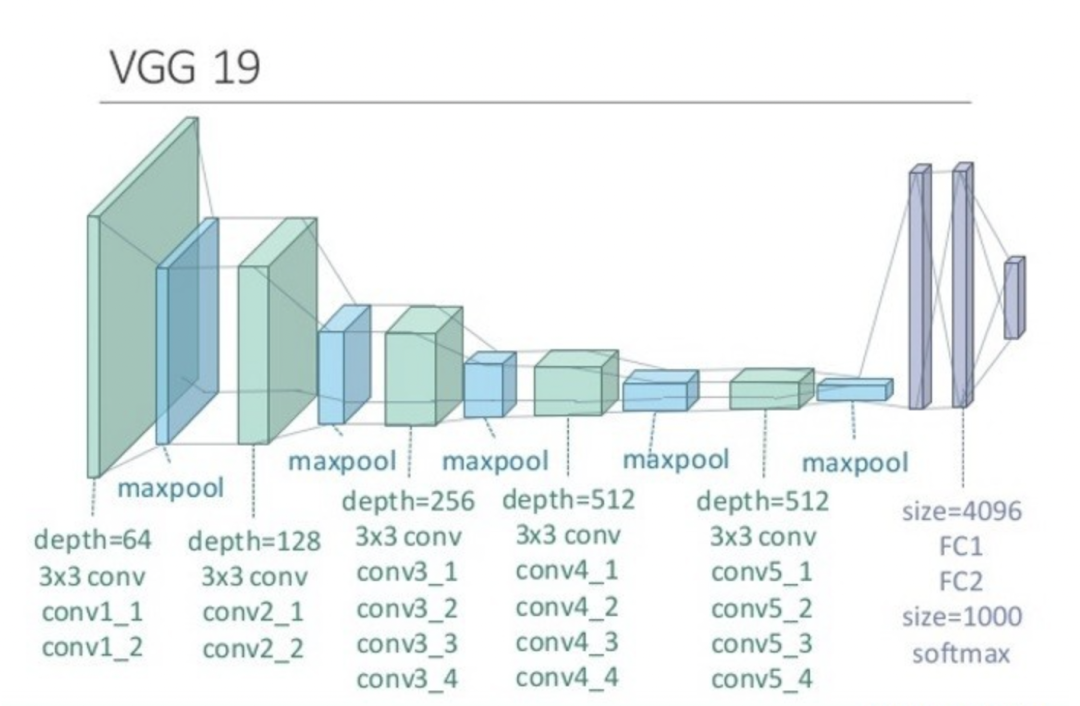
这三个特性决定了卷积神经网络非常适合用于图像识别。例如由牛津大学开发的VGG模型就是基于卷积神经网络模型建立的,它在识别物体的候选框生成、图像的定位与检索等方面十分准确,这使得它在2014年ImageNet竞赛定位任务中获得了第一名。
下一篇文章:《起薪4万,百度AI产品&研发必懂深度学习实现原理框架(下)》会继续讲解CNN、RNN和GAN深度学习三大典型模型的详细原理拆解,大家可以先关注公众号。
如果你最近在看新的机会,也打算求职AI的产品经理,可以加我微信入AI求职交流群。
如果想要转行做AI产品经理,但是缺乏项目经验,可以关注我们推出的《AIGC产品经理特训营》,以求职成功为核心目标,4人小班制一对一打磨AIGC项目经验,想要了解详情,可以私信:xuelaoban667