
一份保姆级的Stable Diffusion部署教程,开启你的炼丹之路
京东科技开发者
共 10398字,需浏览 21分钟
· 2023-08-03


1.1 创建GPU云主机
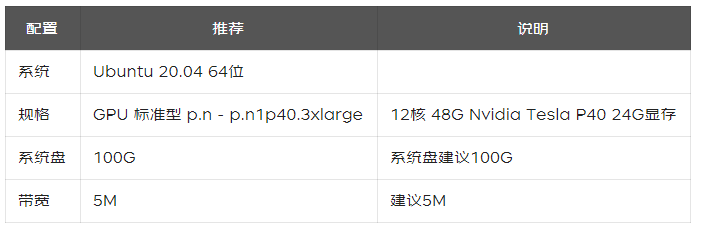
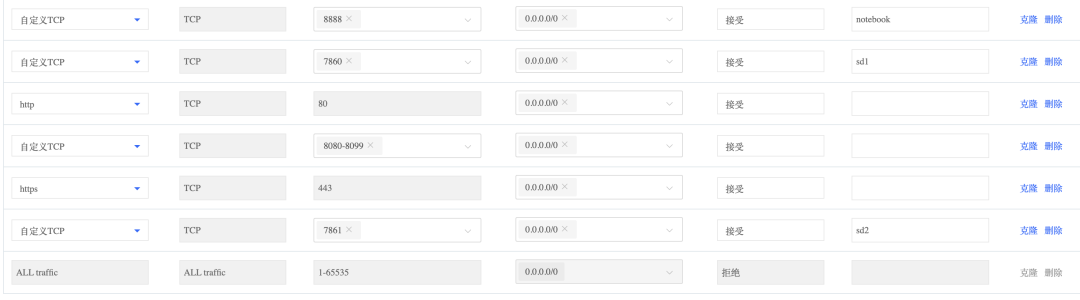
1.2 创建安全组并绑定
2.1 安装GPU驱动

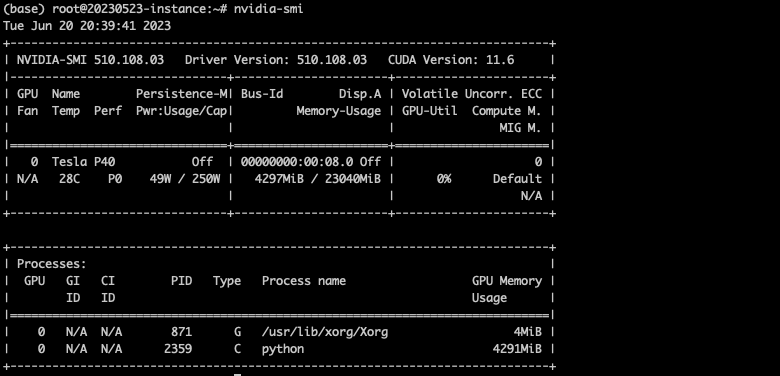
# 安装510版本驱动apt install nvidia-driver-510# 查看驱动信息nvidia-smi
2.2 安装CUDA
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pinsudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600wget https://developer.download.nvidia.com/compute/cuda/11.6.2/local_installers/cuda-repo-ubuntu2004-11-6-local_11.6.2-510.47.03-1_amd64.debsudo dpkg -i cuda-repo-ubuntu2004-11-6-local_11.6.2-510.47.03-1_amd64.debsudo apt-key add /var/cuda-repo-ubuntu2004-11-6-local/7fa2af80.pubsudo apt-get updatesudo apt-get -y install cuda
2.3 安装Python 3.10
apt install software-properties-commonadd-apt-repository ppa:deadsnakes/ppaapt updateapt install python3.10python3.10 --verison
[]index-url = https://pypi.tuna.tsinghua.edu.cn/simple[]trusted-host = https://pypi.tuna.tsinghua.edu.cn
2.4 安装Anaconda
wget https://repo.anaconda.com/archive/Anaconda3-2023.03-1-Linux-x86_64.shbash ./Anaconda3-2023.03-1-Linux-x86_64.sh
conda create -n python3.10.9 python==3.10.9conda activate python3.10.9
2.5 安装PyTorch
# 使用conda安装,两种安装方式二选一conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.6 -c pytorch -c nvidia# 使用pip安装,两种安装方式二选一pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
3.1 下载stable-diffusion-webui
conda activate python3.10.9
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
3.2 安装依赖
cd stable-diffusion-webuipip install -r requirements_versions.txtpip install -r requirements.txt
3.3 启动stable-diffusion-webui
python launch.py --listen --enable-insecure-extension-access
python launch.py --listen --enable-insecure-extension-access --gradio-auth username:password上述命令非后台运行,如需后台运行可以使用nohup、tmux等方法实现。
3.4 使用stable-diffusions生成图片
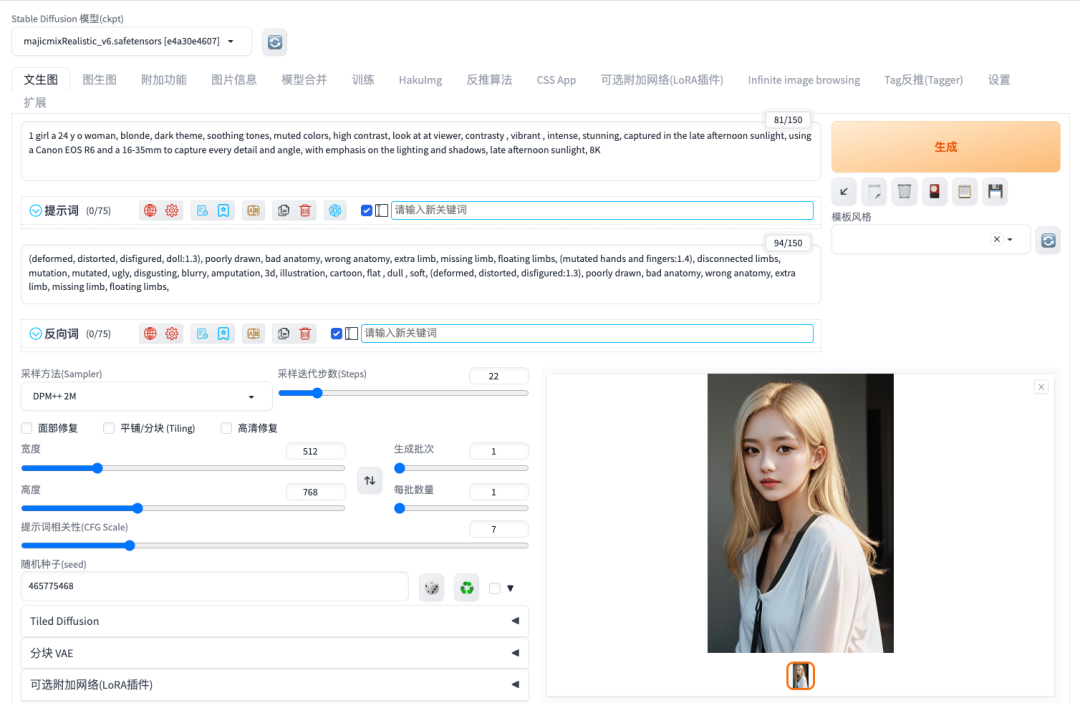
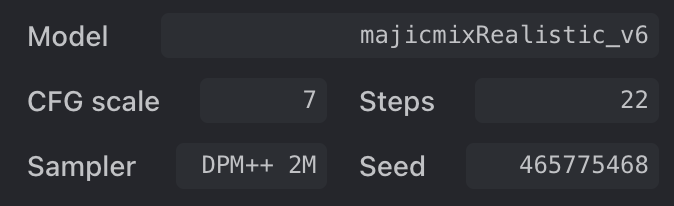
1 girl a 24 y o woman, blonde, dark theme, soothing tones, muted colors, high contrast, look at at viewer, contrasty , vibrant , intense, stunning, captured in the late afternoon sunlight, using a Canon EOS R6 and a 16-35mm to capture every detail and angle, with emphasis on the lighting and shadows, late afternoon sunlight, 8KNegative prompt
(deformed, distorted, disfigured, doll:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, (mutated hands and fingers:1.4), disconnected limbs, mutation, mutated, ugly, disgusting, blurry, amputation, 3d, illustration, cartoon, flat , dull , soft, (deformed, distorted, disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs,
其他参数
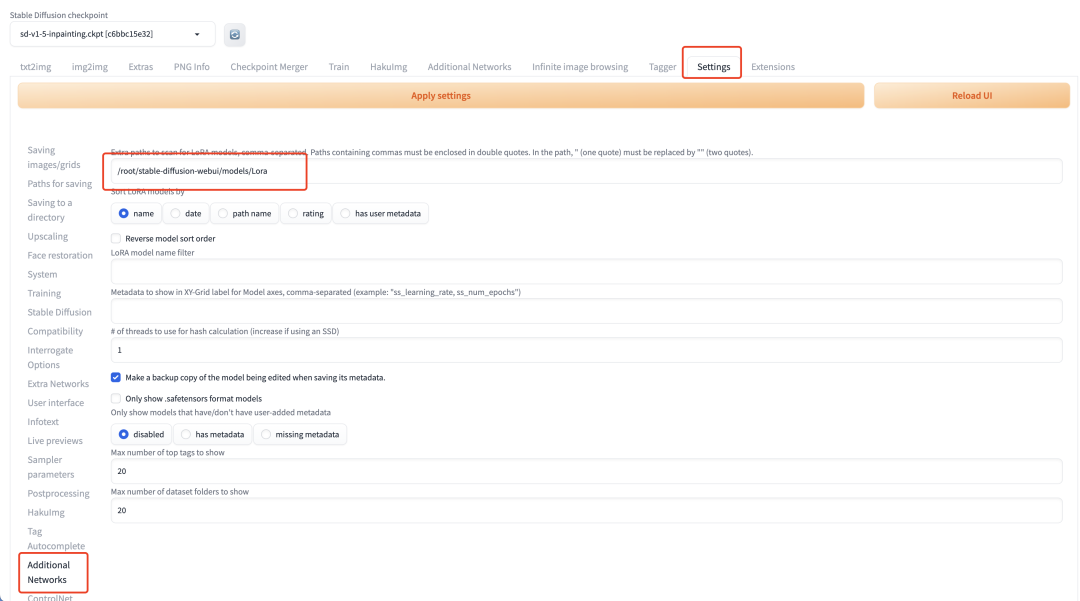
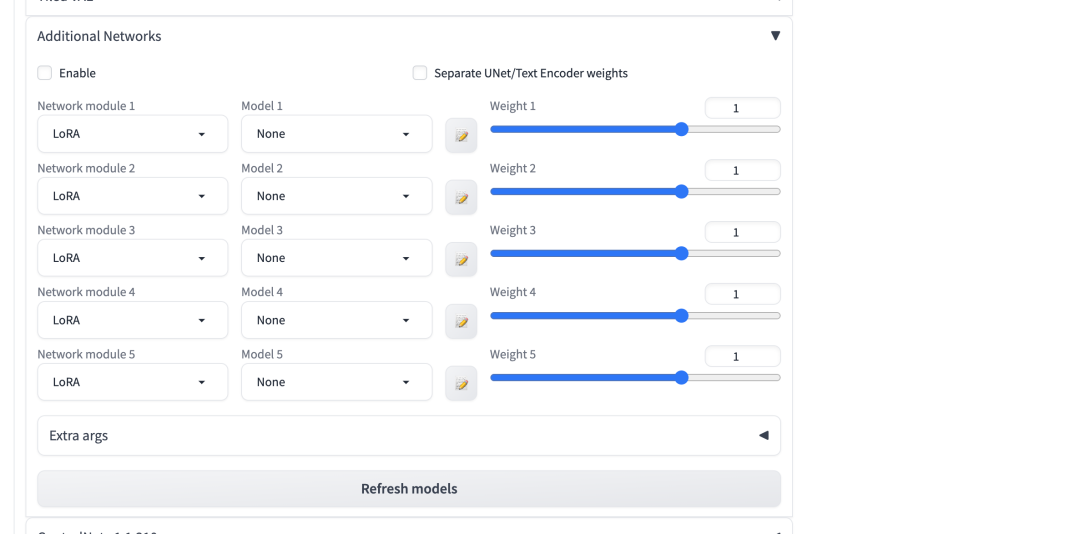
4.1 安装LoRa插件Additional Networks
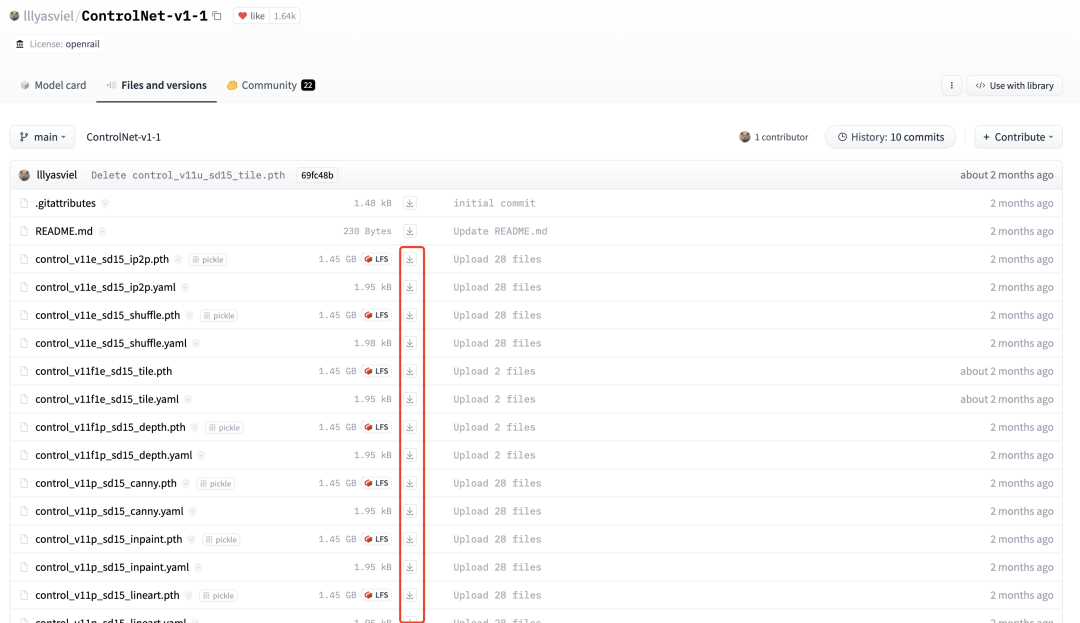
4.2 安装ControlNet

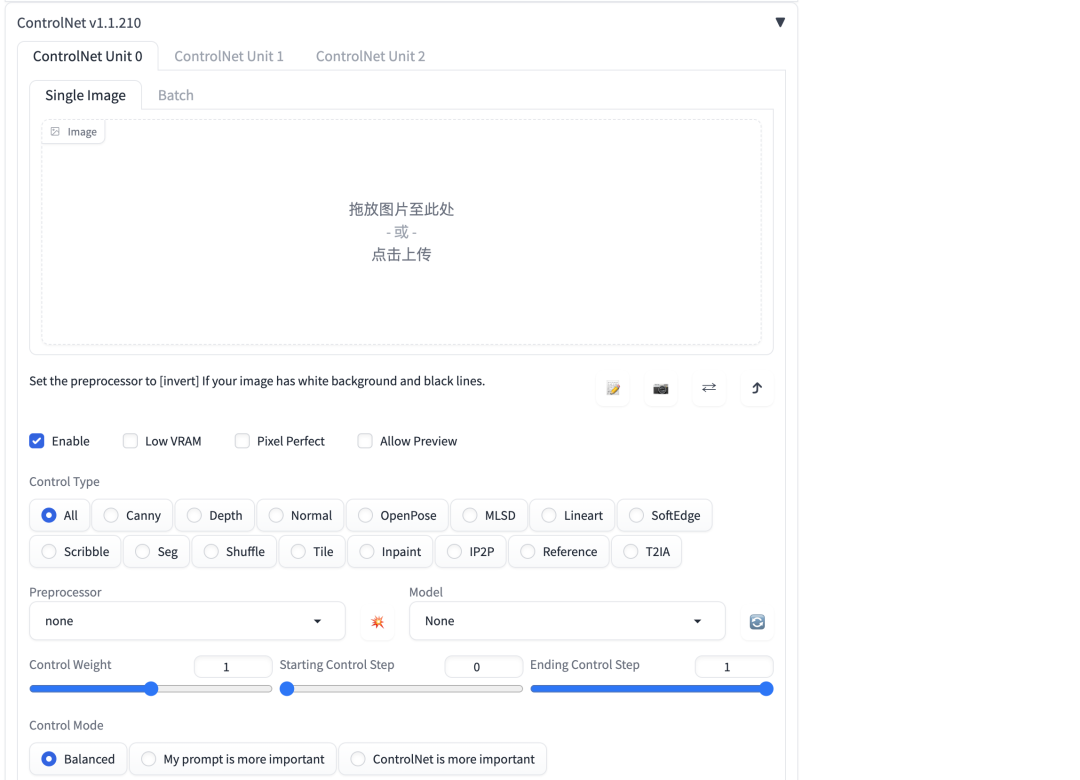
4.3 Jupyter Notebook
如已在章节2.4中安装了Anaconda,直接使用以下命令运行notebook
jupyter notebook --allow-root --NotebookApp.token='设置你的token'
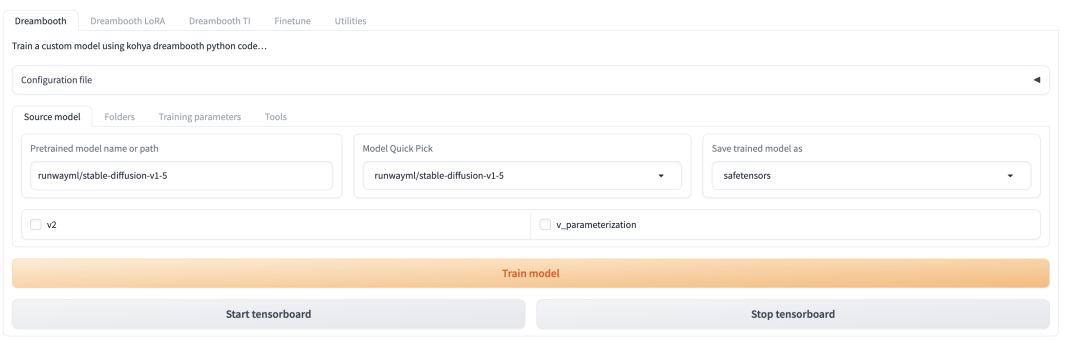
4.4 模型训练工具Kohya_ss
sudo apt-get update \&& sudo apt-get install -y nvidia-container-toolkit-base# 查看是否安装成功nvidia-ctk --version
git clone https://github.com/bmaltais/kohya_ss.git
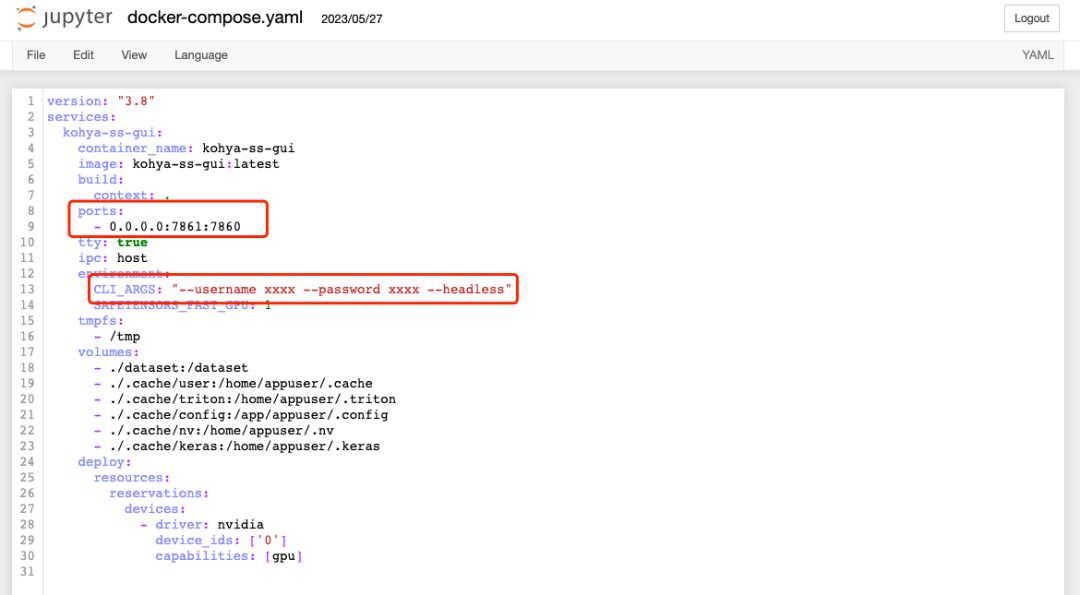
docker compose build # 首次执行需要builddocker compose run --service-ports kohya-ss-gui


评论
【第129期】程序员的新宠:三款终端工具,让你告别Xshell!
概述 WindTerm:跨平台的SSH利器 首先介绍的是WindTerm,这是一款使用C语言开发的跨平台SSH客户端。它不仅完全免费,而且没有商业使用的限制。WindTerm支持SSH v2、Telnet、Raw Tcp等协议,而且性能出色,甚至超过了FinalShell和Electerm。功能
前端微服务
0
上班的时候,有一群摸鱼搭子非常重要...
上班的时候,有一群摸鱼搭子非常重要!一到上班时间,他们就从四面八方涌进群里冒泡...从八卦聊到股市、从职场聊到乌X兰局势,偶尔还会复读、相亲、battle...然后,下午6点钟准时消失不见...所以你要不要加入我们一起摸鱼?我们有北京、上海、深圳、广州、杭州、武汉、成都、南京等8个城市的摸鱼群,还有
产品经理日记
0
周四002 瑞超:同样落寞的境遇——北雪平vs埃尔夫斯堡
上赛季最终排名联赛第9的北雪平本赛季伊始表现不佳,4轮战罢他们仅以1胜1平2负的战绩排在倒数第三,这支历史上曾夺得13次联赛冠军、6次杯赛冠军老牌劲旅,正如英格兰赛场上的一众百年俱乐部,在低谷中不断探索着出路。球队主教练安德烈亚斯·阿尔姆曾是AIK索尔纳及赫根队的主教练,他于今年年初刚刚拿起球队教鞭
产品与体验
0
你只是卡住了,你并没有被击垮
一旦思维僵化了,那就很难跟上这个真实世界的快节奏,更不可能自发地去发现自身问题,进而打破自己。思维僵化,会导致我们无法“活在当下,开放和接纳,并去做自己觉得重要的事情”。觉察自己思维僵化的特征,是改变的第一步。思维僵化导致了你的选择都是错误的。思维方式的不同,才是人跟人之间的不同。有的人遇到挫折了,
小Q聊产品
1
日本影山优佳最新杂志照,展现充满透明感的美丽
今天的图文分享的是影山优佳的杂志写真。元日向坂46的影山优佳,登上了写真杂志《周刊FLASH》5/7和5/14合并号的封面。影山优佳是日本艺人、女演员、前偶像。身高155厘米。2001年5月8日出生于东京都。2023年7月从组合日向坂46毕业,之后作为演员活跃的影山优佳,在《周刊FLAS
python教程
0
盘点一个使用超级鹰识别验证码并自动登录的案例
点击上方“Python共享之家”,进行关注回复“资源”即可获赠Python学习资料今日鸡汤江上几人在,天涯孤棹还。大家好,我是皮皮。一、前言前几天在Python钻石交流群【静惜】问了一个Python实现识别验证码并自动登录的问题,提问截图如下:验证码的截图如下所示:二、实现过程这里大家激烈的探讨,【
IT共享之家
0
朋友,你也不想一个人孤孤单单的上班吧?
上班的时候,有一群摸鱼搭子非常重要!一到上班时间,他们就从四面八方涌进群里冒泡...从八卦聊到股市、从职场聊到乌X兰局势,偶尔还会复读、相亲、battle...然后,下午6点钟准时消失不见...所以你要不要加入我们一起摸鱼?我们有北京、上海、深圳、广州、杭州、武汉、成都、南京等8个城市的摸鱼群,还有
产品经理日记
0