 3D视觉工坊
3D视觉工坊





作者:计算机视觉@一杯红茶|来源:计算机视觉工坊
我们都知道特征检测和匹配是计算机视觉领域中的重要任务,它们在许多应用中发挥着关键作用,比如SLAM、SFM、AR、VR等许多算法都需要稳定精确的特征检测和匹配。
特征检测算法的意义在于从图像或视频中提取出具有独特性质的特征点,这些特征点可以代表图像中的关键信息。这些特征点通常具有旋转、尺度和光照变化的不变性,使得它们在图像的不同位置和角度下都能够被准确地检测到。
特征匹配算法的意义在于将两个或多个图像中的特征点进行对应,以实现图像间的关联和匹配。通过将特征点进行匹配,可以进行目标跟踪、图像配准、三维重建等任务。
目前个人认为特征检测和匹配的研究点包括但不限于以下几个方面:
1.特征点检测算法的设计和改进,提高特征点的鲁棒性和准确性。
2.特征描述子的设计和优化,提高特征点的区分度和匹配性能。
3.多尺度和多模态特征检测与匹配,适应不同尺度、视角和传感器条件下的图像数据。
4.大规模特征点检测和匹配算法,用于处理大规模图像数据库或视频流。
5.深度学习在特征检测和匹配中的应用,如使用卷积神经网络提取图像特征和进行匹配。
特征检测和匹配的应用广泛,包括但不限于以下几个方面:
1.目标识别和跟踪:通过检测和匹配图像中的特征点,可以实现目标在视频中的跟踪和定位,如自动驾驶中的目标识别和跟踪。
2.图像配准和拼接:通过匹配图像中的特征点,可以将多幅图像进行配准和拼接,生成全景图像或三维重建模型。
3.增强现实(AR)和虚拟现实(VR):特征检测和匹配可用于将虚拟对象与真实世界进行对齐和融合,实现更逼真的AR和VR体验。
4.图像检索和分类:通过匹配图像中的特征点,可以对图像进行相似性搜索和分类,用于图像检索和内容识别。
5.三维重建和建模:通过匹配多个视角的图像中的特征点,可以进行三维重建和场景建模,用于计算机辅助设计、虚拟现实等领域。
6.视频处理和分析:特征检测和匹配在视频处理中可以用于运动估计、目标跟踪、动作识别等任务。
所以,本篇文章针对不同的实际应用需求,对三种特征检测和匹配算法进行总结并进行代码实践:
1.最传统的且应用最为广泛的SIFT特征检测匹配算法。
2.速度和精度之间的平衡,注重实时性的SLAM中常用的ORB特征检测和匹配算法。
3.最新且效果很好的基于深度学习的特征检测和匹配算法SuperPoint+SuperGlue。
1.SIFT特征检测和匹配算法
关于SIFT的算法原理及解释网上有很多资料,如果想深入理解还可以找来原论文读一读,所以这里就简单介绍下SIFT特征检测和匹配算法。
SIFT是找到图像中的一些“稳定点”,这些点是一些十分突出的点,比如角点、边缘点、暗区域的亮点以及亮区域的点,其算法假设两幅图像中有相同的景物,那么使用某种方法分别提取各自的稳定点,这些点之间会有相互对应的匹配点。
SIFT算法找稳定点的方法是找灰度图的局部最值,由于数字图像是离散的,想求导和求最值这些操作都是使用滤波器,而滤波器是有尺寸大小的,使用同一尺寸的滤波器对两幅包含有不同尺寸的同一物体的图像求局部最值将有可能出现一方求得最值而另一方却没有的情况,SIFT的精妙之处在于采用图像金字塔的方法解决这一问题,我们可以把两幅图像想象成是连续的,分别以它们作为底面作四棱锥,就像金字塔,那么每一个截面与原图像相似,那么两个金字塔中必然会有包含大小一致的物体的无穷个截面,但应用只能是离散的,所以我们只能构造有限层,层数越多当然越好,但处理时间会相应增加,层数太少不行,因为向下采样的截面中可能找不到尺寸大小一致的两个物体的图像。有了图像金字塔就可以对每一层求出局部最值,但是这样的稳定点数目将会很多,所以需要使用某种方法抑制去除一部分点,但又使得同一尺度下的稳定点得以保存。
这里用C++和Python各自实现一遍:
C++版本:
这里需要自己安装配置opencv3哈,很简单。安装链接:https://blog.csdn.net/qq_43193873/article/details/126144636
在ubuntu20.04LTS下编译执行,首先是CMakeLists.txt的编写
cmake_minimum_required(VERSION 2.8)
set(CMAKE_BUILD_TYPE Debug)
set(DCMAKE_BUILD_TYPE Debug)
project(KeyPointsExtractionAndMatche)
find_package(OpenCV 3 REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
## CUDA(可选择,SIFT可以进行GPU加速)
# FIND_PACKAGE(CUDA)
# IF(CUDA_FOUND)
# set (EXTRA_INC_DIRS
# ${CUDA_INCLUDE_DIRS}
# ${CUDA_SDK_INCLUDE_DIR}
# )
# cuda_include_directories(${EXTRA_INC_DIRS} ${CMAKE_CURRENT_BINARY_DIR})
# set (EXTRA_LIBRARIES
# ${CUDA_LIBS}
# ${CUDA_cublas_LIBRARY}
# )
# ENDIF(CUDA_FOUND)
add_executable(KeyPointsExtractionAndMatche main.cpp)
target_link_libraries(KeyPointsExtractionAndMatche ${OpenCV_LIBS})
代码:
#include <stdlib.h>
#include <string>
#include <vector>
#include <opencv2/opencv.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
using namespace std;
int main()
{
//图像名,自己实践时替换成自己的路径
string image_name1="/home/ccy/code_test/img1.jpg";
string image_name2="/home/ccy/code_test/img2.jpg";
//先读一个彩色图像用于后续绘制特征点匹配对
cv::Mat color_img1 = cv::imread(image_name1, 1);
cv::Mat color_img2 = cv::imread(image_name2, 1);
//将图像转换为灰度图像,用于SIFT特征提取和匹配
cv::Mat gray_img1 = cv::imread(image_name1, 0);
cv::Mat gray_img2 = cv::imread(image_name2, 0);
//计算SIFT特征检测和匹配的时间
double start = static_cast<double>(cv::getTickCount());
//提取两幅图像的SIFT特征点并筛选出匹配的特征点
vector<cv::KeyPoint> keypoints1,keypoints2;
cv::Mat descriptors1,descriptors2;
cv::Ptr<cv::FeatureDetector> detector=cv::SiftFeatureDetector::create();
cv::Ptr<cv::DescriptorExtractor> descriptor=cv::SiftDescriptorExtractor::create();
cv::Ptr<cv::DescriptorMatcher> matcher=cv::DescriptorMatcher::create("BruteForce");
//----------------------------------------------------------------------------------------------------//
//opencv3里提供了两种匹配算法,分别是BruteForce和FlannBased,BruteForce是暴力匹配,FlannBased是基于近似最近邻的匹配。
//BruteForce:通过计算两个特征描述子之间的欧氏距离或其他相似性度量来确定匹配程度。
//BruteForce_L1:这种匹配类型使用L1范数(曼哈顿距离)作为特征描述子之间的距离度量方式。L1范数是将两个向量各个对应元素的差的绝对值求和作为距离的度量方式。
//BruteForce_Hamming:这种匹配类型使用汉明距离作为特征描述子之间的距离度量方式。汉明距离是将两个向量各个对应元素的差的绝对值求和作为距离的度量方式。
//BruteForce_HammingLUT:这种匹配类型使用汉明距离作为特征描述子之间的距离度量方式。汉明距离是将两个向量各个对应元素的差的绝对值求和作为距离的度量方式。这种匹配类型使用了查找表(LUT)来加速汉明距离的计算。
//BruteForce_SL2:这种匹配类型使用平方欧氏距离作为特征描述子之间的距离度量方式。平方欧氏距离是将两个向量各个对应元素的差的平方求和作为距离的度量方式。
//FlannBased:基于近似最近邻的匹配,使用快速最近邻搜索包(FLANN)来计算。
//----------------------------------------------------------------------------------------------------//
detector->detect(gray_img1,keypoints1);
detector->detect(gray_img2,keypoints2);
descriptor->compute(gray_img1,keypoints1,descriptors1);
descriptor->compute(gray_img2,keypoints2,descriptors2);
//匹配
vector<cv::DMatch> matches;
matcher->match(descriptors1,descriptors2,matches);
//筛选匹配点
double min_dist=10000,max_dist=0;
//找出所有匹配之间的最小距离和最大距离,即是最相似的和最不相似的两组点之间的距离
for(int i=0;i<descriptors1.rows;i++)
{
double dist=matches[i].distance;
if(dist<min_dist) min_dist=dist;
if(dist>max_dist) max_dist=dist;
}
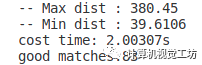
cout<<"-- Max dist : "<<max_dist<<endl;
cout<<"-- Min dist : "<<min_dist<<endl;
//当描述子之间的距离大于两倍的最小距离时,即认为匹配有误.但有时候最小距离会非常小,设置一个经验值30作为下限.
std::vector<cv::DMatch> filteredMatches;
for(int i=0;i<descriptors1.rows;i++)
{
if(matches[i].distance<=max(2*min_dist,30.0))
{
filteredMatches.push_back(matches[i]);
}
}
double time = ((double)cv::getTickCount() - start) / cv::getTickFrequency();
cout<<"cost time: "<<time<<"s"<<endl;
//输出匹配点对数
cout<<"good matches:"<<filteredMatches.size()<<endl;
//画出匹配的特征点
cv::Mat img_matches;
//拼接两幅图像作为画布
cv::hconcat(color_img1,color_img2,img_matches);
for(int i=0;i<filteredMatches.size();i++)
{
cv::Point2f pt1=keypoints1[filteredMatches[i].queryIdx].pt;
cv::Point2f pt2=keypoints2[filteredMatches[i].trainIdx].pt;
//特征点坐标需要根据图像偏移量进行修正
pt2.x+=color_img1.cols;
cv::line(img_matches,pt1,pt2,cv::Scalar(0,255,0),2);
}
//保存图片到指定路径
cv::imwrite("/home/ccy/code_test/img_matches.jpg", img_matches);
return 0;
}
结果:

Python实现:
import cv2
# 读取彩色图像
image1_color = cv2.imread('/home/ccy/code_test/img1.jpg', 1)
image2_color = cv2.imread('/home/ccy/code_test/img2.jpg', 1)
# 读取灰度图像
image1 = cv2.imread('/home/ccy/code_test/img1.jpg', 0)
image2 = cv2.imread('/home/ccy/code_test/img2.jpg', 0)
# 计算SIFT特征检测和匹配的时间
start = cv2.getTickCount()
# 创建SIFT对象
sift = cv2.SIFT_create()
# 检测关键点和计算描述子
keypoints1, descriptors1 = sift.detectAndCompute(image1, None)
keypoints2, descriptors2 = sift.detectAndCompute(image2, None)
# 创建FLANN匹配器
flann = cv2.FlannBasedMatcher()
# 进行特征匹配
matches = flann.knnMatch(descriptors1, descriptors2, k=2)
# 筛选匹配结果
good_matches = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good_matches.append(m)
end = cv2.getTickCount()
print('SIFT匹配时间:', (end - start) / cv2.getTickFrequency(), 's')
# 绘制匹配结果
result = cv2.drawMatches(image1_color, keypoints1, image2_color, keypoints2, good_matches, None)
# 保存结果
cv2.imwrite('SIFT_Matches.jpg', result)
结果:
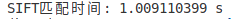

可以看出FLANN匹配效果还是要比Brute-Force暴力匹配要好很多,速度也更快。
ORB特征检测和匹配算法:
ORB(Oriented FAST and Rotated BRIEF)结合了FAST角点检测和BRIEF特征描述子,具有快速、鲁棒和旋转不变性的特点。
其中FAST(Features from Accelerated Segment Test)角点检测算法通过比较像素点与其周围邻域像素点的灰度值来判断该点是否为角点。通过FAST角点检测,ORB能够快速而准确地检测出具有稳定性和重复性的关键点。BRIEF(Binary Robust Independent Elementary Features)特征描述子来表示关键点的局部特征。BRIEF特征描述子将关键点周围的像素对进行二进制比较,并生成一个定长的二进制描述子,用于描述关键点的局部特征。这种二进制描述子具有较小的存储空间和快速的匹配速度。
ORB算法具有旋转不变性,这意味着它能够检测和匹配旋转变化后的关键点。为了实现旋转不变性,ORB在角点检测过程中计算关键点的方向,并在生成描述子时根据关键点的方向进行旋转。这样,即使图像发生旋转,ORB算法仍然能够正确地匹配关键点。
ORB算法可以使用暴力匹配(Brute-Force)或近似最近邻匹配(FLANN)进行特征匹配。暴力匹配方法通过计算特征描述子之间的欧氏距离或汉明距离来确定匹配程度。近似最近邻匹配方法使用FLANN(快速最近邻搜索库)算法进行近似的最近邻搜索,以加速匹配过程。
C++实践代码:
#include <stdlib.h>
#include <string>
#include <vector>
#include <opencv2/opencv.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
using namespace std;
int main()
{
// 读取彩色图像
cv::Mat image1_color = cv::imread("/home/ccy/code_test/img1.jpg", cv::IMREAD_COLOR);
cv::Mat image2_color = cv::imread("/home/ccy/code_test/img2.jpg", cv::IMREAD_COLOR);
// 读取灰度图像
cv::Mat image1_gray = cv::imread("/home/ccy/code_test/img1.jpg", cv::IMREAD_GRAYSCALE);
cv::Mat image2_gray = cv::imread("/home/ccy/code_test/img2.jpg", cv::IMREAD_GRAYSCALE);
//计时
double start = static_cast<double>(cv::getTickCount());
// 创建ORB对象
cv::Ptr<cv::ORB> orb = cv::ORB::create();
// 检测关键点和计算描述子
std::vector<cv::KeyPoint> keypoints1, keypoints2;
cv::Mat descriptors1, descriptors2;
orb->detectAndCompute(image1_gray, cv::noArray(), keypoints1, descriptors1);
orb->detectAndCompute(image2_gray, cv::noArray(), keypoints2, descriptors2);
// 创建FLANN匹配器
//注意:BruteForce_HAMMING匹配类型适用于二进制特征描述子,如ORB(Oriented FAST and Rotated BRIEF)和Brief。
//这种匹配类型使用汉明距离(Hamming distance)作为特征描述子之间的距离度量方式。汉明距离是计算两个二进制向量之间不同位的数量。
cv::Ptr<cv::DescriptorMatcher> matcher = cv::DescriptorMatcher::create(cv::DescriptorMatcher::BRUTEFORCE_HAMMING);
// 进行特征匹配
std::vector<cv::DMatch> matches;
matcher->match(descriptors1, descriptors2, matches);
// 筛选匹配结果
std::vector<cv::DMatch> goodMatches;
double minDist = 100.0;
double maxDist = 0.0;
for (int i = 0; i < descriptors1.rows; i++)
{
double dist = matches[i].distance;
if (dist < minDist)
minDist = dist;
if (dist > maxDist)
maxDist = dist;
}
double thresholdDist = 0.6 * maxDist;
for (int i = 0; i < descriptors1.rows; i++)
{
if (matches[i].distance < thresholdDist)
goodMatches.push_back(matches[i]);
}
double time = ((double)cv::getTickCount() - start) / cv::getTickFrequency();
cout<<"cost time: "<<time<<"s"<<endl;
// 绘制匹配结果
cv::Mat result;
cv::drawMatches(image1_color, keypoints1, image2_color, keypoints2, goodMatches, result);
// 保存匹配结果
cv::imwrite("result.jpg", result);
return 0;
}
结果:

python代码实现:
import cv2
# 读取彩色图像
image1_color = cv2.imread('/home/ccy/code_test/img1.jpg', 1)
image2_color = cv2.imread('/home/ccy/code_test/img2.jpg', 1)
# 读取灰度图像
image1_gray = cv2.imread('/home/ccy/code_test/img1.jpg', cv2.IMREAD_GRAYSCALE)
image2_gray = cv2.imread('/home/ccy/code_test/img2.jpg', cv2.IMREAD_GRAYSCALE)
# 计时
start = cv2.getTickCount()
# 创建ORB对象
orb = cv2.ORB_create()
# 检测关键点和计算描述子
keypoints1, descriptors1 = orb.detectAndCompute(image1_gray, None)
keypoints2, descriptors2 = orb.detectAndCompute(image2_gray, None)
# 创建BFMatcher匹配器
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
# 进行特征匹配
matches = bf.match(descriptors1, descriptors2)
# 筛选匹配结果
matches = sorted(matches, key=lambda x: x.distance) # 按距离升序排序
good_matches = matches[:50] # 选择前50个较好的匹配
end = cv2.getTickCount()
print('ORB匹配时间:', (end - start) / cv2.getTickFrequency(), 's')
# 绘制匹配结果
result = cv2.drawMatches(image1_color, keypoints1, image2_color, keypoints2, good_matches, None, flags=2)
# 保存结果
cv2.imwrite('ORB_Matches.jpg', result)
结果:


从匹配质量上看还是SIFT更好,这是没有疑问的,但是速度比SIFT快一个数量级要。
Super Point + Super Glue特征检测和匹配算法:
Super Point论文:
D Detone, Malisiewicz T , Rabinovich A . SuperPoint: Self-Supervised Interest Point Detection and Description[C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, 2018.
项目地址:https://github.com/magicleap/SuperPointPretrainedNetwork
Super Glue论文:
P. -E. Sarlin, D. DeTone, T. Malisiewicz and A. Rabinovich, "SuperGlue: Learning Feature Matching With Graph Neural Networks," 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 2020, pp. 4937-4946, doi: 10.1109/CVPR42600.2020.00499.
项目地址:https://github.com/magicleap/SuperGluePretrainedNetwork
简单介绍下这两个算法,具体的网上有解释,还可以看原论文。
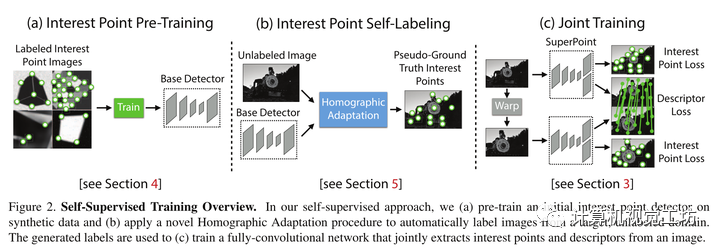
首先SuperPoint,采用了自监督的方法提取特征点,设计了一个由特征点检测器生成的具有伪真值的数据集,而非大量的人工标记。为了得到伪真值,首先在大量的虚拟数据集上训练了一个全卷积网络,这些虚拟数据集由一些基本图形组成,例如线段、三角形、矩形和立方体等,这些基本图形具有无争议的特征点位置;这样pre-trained得到的检测网络称之为MagicPoint,它在虚拟场景中检测特征点的性能明显优于传统方式,但是在真实的复杂场景中表现不佳,因此提出了一种多尺度多变换的方法Homographic Adaptation,通过对图像进行多次不同的尺度或角度变换来帮助网络能够在不同视角、不同尺度观测到特征点。
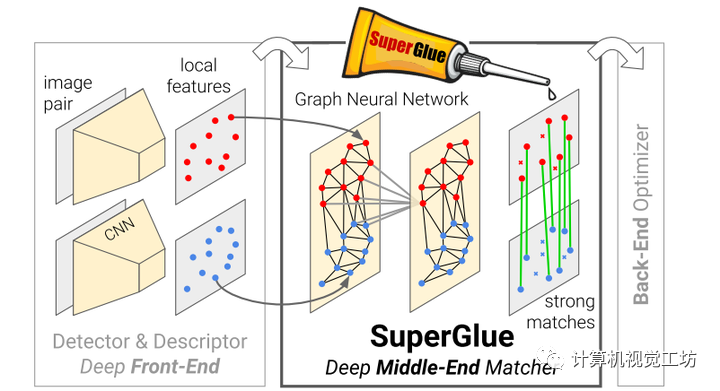
然后是SuperGlue,他是一种能够同时进行特征匹配以及滤除外点的网络,其中特征匹配是通过求解可微分最优化转移问题( optimal transport problem)来解决,损失函数由GNN来构建;基于注意力机制提出了一种灵活的内容聚合机制,这使得SuperGlue能够同时感知潜在的3D场景以及进行特征匹配。
代码实践:这里介绍一个常用的特征检测、匹配、重建、定位工具包,hloc,里面集成里很多常用的特征检测和匹配、重建、定位算法,我们直接拿他的库来进行super point和super glue特征检测和匹配。
项目地址:https://github.com/cvg/Hierarchical-Localization
首先配置hloc,其需要Python >=3.7 PyTorch >=1.1
git clone --recursive https://github.com/cvg/Hierarchical-Localization/
cd Hierarchical-Localization/
python -m pip install -e .
代码:
from hloc import extract_features, match_features
from tqdm import tqdm
from pathlib import Path
import argparse
from hloc.utils.parsers import parse_retrieval
from hloc.utils.io import get_keypoints, get_matches
import cv2
import numpy as np
import time
if __name__ == '__main__':
#添加参数,在运行时输入自己的--base_dir,比如我的运行代码是'python SPSGtest.py --base_dir /home/ccy/code_test'
parser = argparse.ArgumentParser()
parser.add_argument('--base_dir', type=Path, required=True)
args = parser.parse_args()
#图像所在路径
images = args.base_dir / 'images/'
#输出路径
outputs=args.base_dir /'output/'
#要匹配的图像对所在路径,里面每行的内容为:img1name img2name
loc_pairs=args.base_dir / 'loc_pairs.txt'
#计时
start = time.time()
#提取特征和匹配特征的配置文件
feature_conf = extract_features.confs['superpoint_max']
matcher_conf = match_features.confs['superglue']
#提取特征和匹配特征,利用预训练模型
features = extract_features.main(feature_conf, images, outputs)
loc_matches = match_features.main(matcher_conf, loc_pairs, feature_conf['output'], outputs)
retrieval_dict = parse_retrieval(loc_pairs)
end = time.time()
print('time:',end-start)
#遍历每一对图像,画出匹配点对和匹配线
for img1 in tqdm(retrieval_dict):
img2 = retrieval_dict[img1]
for img2name in img2:
matches,_ = get_matches(loc_matches, img1, img2name)
kpts0= get_keypoints(features, img1)
kpts1= get_keypoints(features, img2name)
#找出匹配点对的坐标
kpts0 = kpts0[matches[:,0]]
kpts1 = kpts1[matches[:,1]]
#画出匹配点对
img1=cv2.imread(str(images/img1))
img2=cv2.imread(str(images/img2name))
for i in range(len(kpts0)):
cv2.circle(img1,(int(kpts0[i][0]),int(kpts0[i][1])),2,(0,0,255),-1)
cv2.circle(img2,(int(kpts1[i][0]),int(kpts1[i][1])),2,(0,0,255),-1)
img3=np.zeros((max(img1.shape[0],img2.shape[0]),img1.shape[1]+img2.shape[1],3),np.uint8)
img3[:img1.shape[0],:img1.shape[1]]=img1
img3[:img2.shape[0],img1.shape[1]:]=img2
#画出所有匹配线
for i in range(len(kpts0)):
cv2.line(img3,(int(kpts0[i][0]),int(kpts0[i][1])),(int(kpts1[i][0])+img1.shape[1],int(kpts1[i][1])),(0,255,0),1)
cv2.imwrite('/home/ccy/code_test/result.jpg',img3)
结果:
可以看到SP+SG的结果又快又准!
高效学习3D视觉三部曲
第一步 加入行业交流群,保持技术的先进性
目前工坊已经建立了3D视觉方向多个社群,包括SLAM、工业3D视觉、自动驾驶方向,细分群包括:[工业方向]三维点云、结构光、机械臂、缺陷检测、三维测量、TOF、相机标定、综合群;[SLAM方向]多传感器融合、ORB-SLAM、激光SLAM、机器人导航、RTK|GPS|UWB等传感器交流群、SLAM综合讨论群;[自动驾驶方向]深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器讨论群、多传感器标定、自动驾驶综合群等。[三维重建方向]NeRF、colmap、OpenMVS等。除了这些,还有求职、硬件选型、视觉产品落地等交流群。大家可以添加小助理微信: dddvisiona,备注:加群+方向+学校|公司, 小助理会拉你入群。

第二步 加入知识星球,问题及时得到解答
针对3D视觉领域的视频课程(三维重建、三维点云、结构光、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、源码分享、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答等进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业、项目对接为一体的铁杆粉丝聚集区,6000+星球成员为创造更好的AI世界共同进步,知识星球入口:「3D视觉从入门到精通」

第三步 系统学习3D视觉,对模块知识体系,深刻理解并运行
如果大家对3D视觉某一个细分方向想系统学习[从理论、代码到实战],推荐3D视觉精品课程学习网址:www.3dcver.com
工业3D视觉方向课程:
SLAM方向课程:
[1]如何高效学习基于LeGo-LOAM框架的激光SLAM?
[1]彻底剖析激光-视觉-IMU-GPS融合SLAM算法:理论推导、代码讲解和实战
[2](第二期)彻底搞懂基于LOAM框架的3D激光SLAM:源码剖析到算法优化
[3]彻底搞懂视觉-惯性SLAM:VINS-Fusion原理精讲与源码剖析
[4]彻底剖析室内、室外激光SLAM关键算法和实战(cartographer+LOAM+LIO-SAM)
视觉三维重建
[1]彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进)
自动驾驶方向课程:

