
实践教程|旋转目标检测模型-TensorRT 部署(C++)

极市导读
本文详细的记录了一次旋转目标检测模型的C++部署过程,附有详细的代码。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
仓库地址(TensorRT,ncnn)github.com/Crescent-Ao/GGHL-Deployment:
https://github.com/Crescent-Ao/GGHL-Deployment
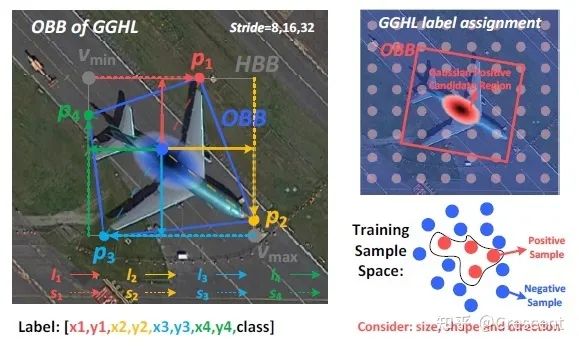
这次工程部署主要选择了比较熟悉的旋转选择框架-GGHL。如果没有特殊算子的检测框架,依然可以使用下面的这个Pipeline, 旋转目标检测主要分成五参数和八参数的表征方法,分别对应的 x,y,w,h,θ, x,y,w,h,\theta, x,y,w,h,\theta,.以及对应的八参数的转化求法 x1,y1,x2,y2,x3,y3,x4,y4x_1,y_1,x_2,y_2,x_3,y_3,x_4,y_4x_1,y_1,x_2,y_2,x_3,y_3,x_4,y_4 。这两种方式在后处理的时候可以互相转换,我们这里选择后者。
TensorRT安装
找到TensorRT的下载地址,我这边选择的是TensorRT8,TensorRT支持以下几种方式安装,分别是deb,tar,rpm。我这边的系统是Ubuntu 22.04,CUDA版本是11.6,选择的安装方式是tar进行安装。
TensorRT地址developer.nvidia.com/tensorrt-getting-started:
https://developer.nvidia.com/tensorrt-getting-started
关于tar的安装方式,可以参考Nvidia官方文档中关于tar的部分。NVIDIA Deep Learning TensorRT Documentation(https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html%23installing-tar)关于tar的安装方式,可以参考Nvidia官方文档中关于tar的部分。这部分会说的比较详细。
https://docs.nvidia.com/deeplearning/tensorrt/install-guide/index.html%23installing-tar
然后需要配置CUDA和TensorRT环境变量以及代码仓库的地址,下面是我zshrc的详细配置,包括TensorRT、CUDA、以及OpenCV。
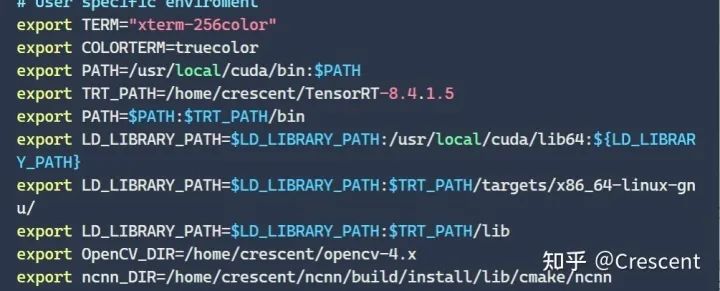
在安装好之后,我们需要对TensorRT进行编译,记住TensorRT的安装位置,我这边是/home/crescent/TensorRT-8.4.15,在命令函数输入下面的命令。
cd /home/crescent/TensorRT-8.4.15
mkdir -p build && cd build
cmake .. -DTRT_LIB_DIR=$TRT_LIBPATH -DTRT_OUT_DIR=`pwd`/out
make -j$(nproc)等待一段时间完成编译后,如果不报错,那么按照英伟达github上官方SampleMnist的测试来检查你的TensorRT是否安装成功。出现下面的结果,代表之前的安装策略都没有错,可以进行下一步,否则要仔细检查编译阶段的问题,可以去stackoverflow找到相应的解决方法。
&&&& RUNNING TensorRT.sample_mnist # ./sample_mnist
[I] Building and running a GPU inference engine for MNIST
[I] Input:
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@#-:.-=@@@@@@@@@@@@@@
@@@@@%= . *@@@@@@@@@@@@@
@@@@% .:+%%% *@@@@@@@@@@@@@
@@@@+=#@@@@@# @@@@@@@@@@@@@@
@@@@@@@@@@@% @@@@@@@@@@@@@@
@@@@@@@@@@@: *@@@@@@@@@@@@@@
@@@@@@@@@@- .@@@@@@@@@@@@@@@
@@@@@@@@@: #@@@@@@@@@@@@@@@
@@@@@@@@: +*%#@@@@@@@@@@@@
@@@@@@@% :+*@@@@@@@@
@@@@@@@@#*+--.:: +@@@@@@
@@@@@@@@@@@@@@@@#=:. +@@@@@
@@@@@@@@@@@@@@@@@@@@ .@@@@@
@@@@@@@@@@@@@@@@@@@@#. #@@@@
@@@@@@@@@@@@@@@@@@@@# @@@@@
@@@@@@@@@%@@@@@@@@@@- +@@@@@
@@@@@@@@#-@@@@@@@@*. =@@@@@@
@@@@@@@@ .+%%%%+=. =@@@@@@@
@@@@@@@@ =@@@@@@@@
@@@@@@@@*=: :--*@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@@@@@@@@@@@@@@@@@@@@@@@@@@@@
[I] Output:
0:
1:
2:
3: **********
4:
5:
6:
7:
8:
9:
&&&& PASSED TensorRT.sample_mnist # ./sample_mnist完成TensorRT的安装后,我们开始下面的部署工作。
模型的中间表达的转换
GGHL只涉及样本分配的策略,这个不会给整体的模型增加任何参数和复杂度,也非常简单。采用的主要架构就是YoloV3中策略,包括DarkNet,FPN+PANet,解耦头等等。有兴趣的话,可以查看相关的代码解读,这里简要概括。这些你都可以不看,我们只要它的权重文件就可。
直接从release下载对应的权重文件,我们需要将这个转换成ONNX等TensorIR等中间表达方式。给出下面的代码,转换过程中,由于结构附带解码头,所以实际获得输出是三个FPN输出和最后一个Concat输出的结构,也就是四个输出name,我们需要将这剔除前面三个输出头。最后利用onnxsim将一些胶水算子简化掉,下面我们用Netron可视化这网络的结构。
def main():
args = make_parser().parse_args()
logger.info("args value: {}".format(args))
print("loading weight file from :{}".format(args.weight_path))
model = GGHL().eval()
ckpt = torch.load(os.path.join(args.weight_path),map_location='cpu')
model.load_state_dict(ckpt)
logger.info("loading checkpoint done")
dummy_input = torch.randn(1,3,cfg.TEST["TEST_IMG_SIZE"],cfg.TEST["TEST_IMG_SIZE"])
dummy_output = model(dummy_input)
torch.onnx.export(model,
dummy_input,
args.onnx_filename,
input_names=[args.input],
output_names=[args.output,args.output2,'demo','output'],
opset_version = 11)
# Network has dynamic or shape inputs, but no optimization profile has been defined.
# 将onnx导入之后,需要剔除三个输出节点
model_onnx = onnx.load(args.onnx_filename)
graph = model_onnx.graph
out = graph.output
for i in range(len(graph.output)-1):
graph.output.remove(out[0])
#去除掉上面三个的头节点,转换成
onnx.checker.check_model(model_onnx)
onnx.save(model_onnx,args.onnx_filename)
logger.info("generate onnx name {}".format(args.onnx_filename))
if(args.onnxsim):
model = onnx.load("GGHL.onnx")
model_sim,chenck = onnxsim.simplify(model)
logger.info("generate onnx_sim name {}".format("GGHL_sim.onnx"))
onnx.save(model_sim,"GGHL_sim.onnx")
if(args.jittrace):
model = model.train()
jit_model = torch.jit.trace(model,dummy_input)
torch.jit.save(jit_model,'GGHL_jit.pt')
logger.info("generate torchscripy format{}".format("GGHL_jit.pth"))下面是GGHL中三个解码头的部分,涉及了大量胶水算子,但是可以省去后续C++解码的部分。我们直接获得也就是这种带有解码头的结构。至于不带有解码头的结构,我们会在后续的NCNN中实现,敬请期待(Nihui大佬TQL)。
转换结束后,我们会获得GGHL.onnx,GGHL_sim.onnx,GGHL.jit,这三个都是TensorIR,不同的框架支持有所不同。直接利用torch.onnx.export就可以直接转换,相关的学习文件可以参考MMDeploy中有关的介绍性文章,收益良多。
接下来我们需要将模型转换成TensorRT需要的范式。至于后面的onnx->Trt。请根据onnx-tensorrt中安装好。可能需要安装,protobuf,onnx等一系列工具,按照README安装就好。
C++ 部署实现
本文只介绍C++的部署的实现,Python版本中也有实现(这个和权重模型加载后再进行推理差不多)。由于TensorRT几乎每一步都需要传入Logger这个类,为了简要的实现,我们使用Nvidia官方示例中的samplelogger这个类。下面介绍一下main.cpp中类中成员函数,和全部的流程。
class GGHLONNX
{
public:
GGHLONNX(const string &onnx_file, const string &engine_file) : m_onnx_file(onnx_file), m_engine_file(engine_file){};
vector prepareImage(const cv::Mat &img);
bool onnxToTRTModel(nvinfer1::IHostMemory *trt_model_stream);
bool loadEngineFromFile();
void doInference(const cv::Mat &img);
private:
const string m_onnx_file;
const string m_engine_file;
samplesCommon::Args gArgs;
nvinfer1::ICudaEngine *m_engine;
bool constructNetwork(nvinfer1::IBuilder *builder, nvinfer1::INetworkDefinition *network, nvinfer1::IBuilderConfig *config, nvonnxparser::IParser *parser);
bool saveEngineFile(nvinfer1::IHostMemory *data);
std::unique_ptr readEngineFile(int &length);
int64_t volume(const nvinfer1::Dims &d);
unsigned int getElementSize(nvinfer1::DataType t);
}; GGHLONNX类主要负责TensorRT两个阶段分别是Builder Phase, Runtime Phase。下面介绍一下这两个阶段的作用。
TensorRT阶段的最高级别接口为Builder,Builder用来负责优化一个模型,并且产生一个Engine
构建一个网络的定义 修改Builder的配置 调用Builder返回引擎
NetworkDefinition接口用来定义模型,最通用的方式转化一个模型至TensorRT是用onnx中间格式输出网络,TensorRT onnx解释器填充网络的定义。必须定义网络的输入和输出。未标记的输出的张量由构建器优化掉的瞬态值,输入和输出张量必须命名,所以在Runtime的时候,TensorRT知道如何将对应的缓存给到模型的定义。
BuilderConfig被用来如何优化的模型,TensorRT可以在降低计算精度的能力,控制内存和运行时的执行速度之间进行权衡,和限制CUDA内核的选择。Builder在完成网络定义和BuilderConfig之后,可以消除无效计算,折叠张量,重新排序在GPU更加高效地计算。可以选择降低浮点运算的精度,FP16,或者量化至INT8。还可以使用不同数据格式对每一层进行实现记录模型的最佳时间。构建序列化形式的引擎过程称为a plan, 反序列的话可以保存至磁盘。
NetworkDefinition接口用来定义模型,最通用的方式转化一个模型至TensorRT是用onnx中间格式输出网络,TensorRT onnx解释器填充网络的定义。必须定义网络的输入和输出。未标记的输出的张量由构建器优化掉的瞬态值,输入和输出张量必须命名,所以在Runtime的时候,TensorRT知道如何将对应的缓存给到模型的定义。1BuilderConfig被用来如何优化的模型,TensorRT可以在降低计算精度的能力,控制内存和运行时的执行速度之间进行权衡,和限制CUDA内核的选择。Builder在完成网络定义和BuilderConfig之后,可以消除无效计算,折叠张量,重新排序在GPU更加高效地计算。可以选择降低浮点运算的精度,FP16,或者量化至INT8。还可以使用不同数据格式对每一层进行实现记录模型的最佳时间。构建序列化形式的引擎过程称为a plan, 反序列的话可以保存至磁盘。
bool GGHLONNX::onnxToTRTModel(nvinfer1::IHostMemory *trt_model_stream)
{
nvinfer1::IBuilder *builder = nvinfer1::createInferBuilder(sample::gLogger.getTRTLogger());
assert(builder != nullptr);
const auto explicitBatch = 1U << static_cast(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
nvinfer1::INetworkDefinition *network = builder->createNetworkV2(explicitBatch);
//配置config
nvinfer1::IBuilderConfig *config = builder->createBuilderConfig();
config->setMemoryPoolLimit(MemoryPoolType::kWORKSPACE,1U<<30);
// 分配内存空间
auto parser = nvonnxparser::createParser(*network, sample::gLogger.getTRTLogger());
// 使用nvonnxparser 将network转换成 trt
// 利用construct network 传入 config,network两个定义,完成buider的构建,并反序列化相应的engine文件,保存到磁盘上
// 构建网络
if (!constructNetwork(builder, network, config, parser))
{
return false;
}
trt_model_stream = m_engine->serialize();
//序列化engine文件
nvinfer1::IHostMemory *data = builder->buildSerializedNetwork(*network,*config);
saveEngineFile(data);
delete config;
delete network;
delete parser;
// m_engine->destroy();
return true;
} 接下来是Runtime 阶段
runtime 需要执行下面的步骤
反序列化来创建引擎
从引擎中创建执行`context`
从接口中填充输入缓存
调用enqueue() or execute()函数 在执行context 来运行接口
其中`Engine`接口表示优化模型,可以查询引擎获取有关网络的输入和输出的张量信息--维度/数据格式/数据类型。`ExecutionContext`接口,是调用推理的主要接口。包含特定关联的所有状态,可以包括单个`Engine`的上下文,并且并行运行他们。调用接口是,必须在合适的位置设置输入输出的缓存,依赖于数据的具体特性,来将他们放入相应的CPU和GPU ,输入输出缓存设置好了,接口调用同步进行推理或者一步排序等等。对应的GGHL中实现是这样。
void GGHLONNX::doInference(const cv::Mat &img)
{
cv::Mat copy_img = img.clone();
nvinfer1::IExecutionContext *context = m_engine->createExecutionContext();
assert(context != nullptr);
int nbBindings = m_engine->getNbBindings();
assert(nbBindings == 2); // 输入和输出,一共是2个
// 为输入和输出创建空间,参考CUDA中的cudaMalloc 和 CUDA freed等范式
void *buffers[2]; // 待创建的空间 为指针数组
std::vector buffer_size; // 要创建的空间大小
buffer_size.resize(nbBindings);
for (int i = 0; i < nbBindings; i++)
{
nvinfer1::Dims dims = m_engine->getBindingDimensions(i); // (3, 224, 224) (1000)
nvinfer1::DataType dtype = m_engine->getBindingDataType(i); // 0, 0 也就是两个都是kFloat类型
// std::cout << static_cast(dtype) << endl;
int64_t total_size = volume(dims) * 1 * getElementSize(dtype);
buffer_size[i] = total_size;
CHECK(cudaMalloc(&buffers[i], total_size));
}
cudaStream_t stream;
CHECK(cudaStreamCreate(&stream)); // 创建异步cuda流
auto out_dim = m_engine->getBindingDimensions(1);
auto output_size = 1;
for (int j = 0; j < out_dim.nbDims; j++)
{
output_size *= out_dim.d[j];
}
float *out = new float[output_size];
// 开始推理
auto t_start = std::chrono::high_resolution_clock::now();
vector cur_input = prepareImage(img);
auto t_end = std::chrono::high_resolution_clock::now();
float duration = std::chrono::duration(t_end - t_start).count();
std::cout << "loading image takes " << duration << "ms" << std::endl;
if (!cur_input.data())
{
std::cout << "failed to prepare image" << std::endl;
}
// 将输入传递到GPU
CHECK(cudaMemcpyAsync(buffers[0], cur_input.data(), buffer_size[0], cudaMemcpyHostToDevice, stream));
// 异步执行
t_start = std::chrono::high_resolution_clock::now();
context->enqueueV2(&buffers[0],stream,nullptr);
// 输出传回给CPU
CHECK(cudaMemcpyAsync(out, buffers[1], buffer_size[1], cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
//主机和设备相同步
vector original_result;
for (int i = 0; i < output_size; i++)
{
original_result.push_back(*(out + i));
}
cout << output_size << endl;
vector convert_middle;
convert_result(original_result,convert_middle);
cout << convert_middle.size() << endl;
vector middle;
//后处理的部分
convert_pred(convert_middle, 800, 1024, BOX_CONF_THRESH,middle);
vector result;
//nms过程
non_max_supression_8_points(middle, BOX_CONF_THRESH, NMS_THRESH, result);
t_end = std::chrono::high_resolution_clock::now();
duration = std::chrono::duration(t_end - t_start).count();
cout << duration << "time" << endl;
cout << duration << "time" << endl;
draw_objects(copy_img, result);
cout << result.size() << endl;
delete[] out;
} Cpp版本的函数名称,同Python版本的函数相一致。8点的nms参考了DOTA Devkit的实现方式,同理也可以使用Opencv的旋转框nms实现,OBBDet.h为后处理主要的头文件,传入参数和传出参数,使用了引用和指针两种分配方式。由于这个部分的实现方式有些繁琐,这里就不详细叙述了,大致的流程同runtime流程相一致,大家可以去看代码的中的实现形式就ok。大致就是全部的实现的流程。
如何使用TensorRT版本的GGHL捏,需要准备cmake以及上述必要的package,CUDA和OpenCV可以查看其他的流程。
mkdir build
cd build
cmake ..
make生成可执行文件后,并且指定需要的图片就可以获得了推理后的图片了。

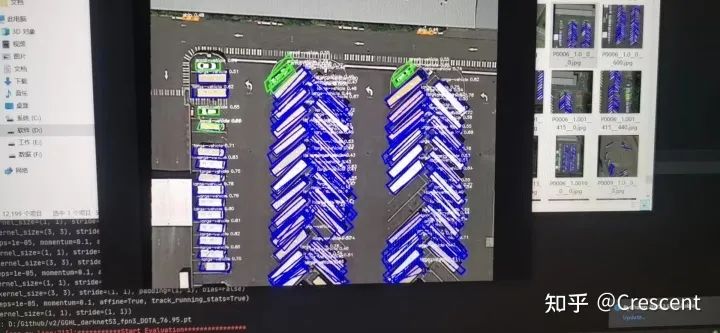
速度的话可以看下这里
FP-16 load image 16.32ms FP-16+nms 48.32ms FP-16 inference 5ms
如果有任何问题,欢迎在评论区中讨论~
公众号后台回复“极市直播”获取100+期极市技术直播回放+PPT
极市干货
点击阅读原文进入CV社区
收获更多技术干货