斯坦福团队推出DetectGPT,学生用AI写论文要犯难了
共 1356字,需浏览 3分钟
· 2023-02-04

大数据文摘授权转载自学术头条
GPT-3、PaLM 和 ChatGPT 等大型语言模型(LLM)已经被证明能够针对各种各样的用户查询做出非常流畅的响应,可以生成“令人信服”的有关科学、数学、历史和当前事件以及社会趋势等复杂问题的回答。
尽管这些回答经常充满错误,但这些生成文本的清晰、自然仍然使得 LLM 在某些情况下被用来替代人力,特别是在学生论文写作和新闻撰写方面。
例如,学生可能使用 LLM 来完成书面作业,使得教师无法准确地评估学生的学习情况;而且,由 LLM 撰写且公开发布在新闻网站上的内容,往往存在大量的事实性错误,由于缺少足够的人工审查,也会对新闻读者产生误导。

不幸的是,在对 LLM 生成的文本和人类编写的文本进行分类时,人类的表现只比随机情况略好(Gehrmann et al., 2019)。因此,使用自动检测方法来识别人类难以识别的信号,成为当前业内的一个重要研究方向,这种方法可能会让教师和新闻读者更相信他们看到的内容来自人类。
近日,斯坦福大学研究团队提出了一种名为 DetectGPT 的新方法,旨在成为首批打击高等教育中 LLM 生成文本的工具之一。相关研究论文以“DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature”为题,已发表在预印本网站 arXiv 上。

在此次工作中,研究团队基于“LLM 生成的文本通常徘徊(hover around)在模型的对数概率函数的负曲率区域的特定区域周围”这一发现,提出了一种用于判别 LLM 生成文本的新指标,这一方法既不需要训练单独的分类器,也不需要收集真实或生成的段落的数据集。
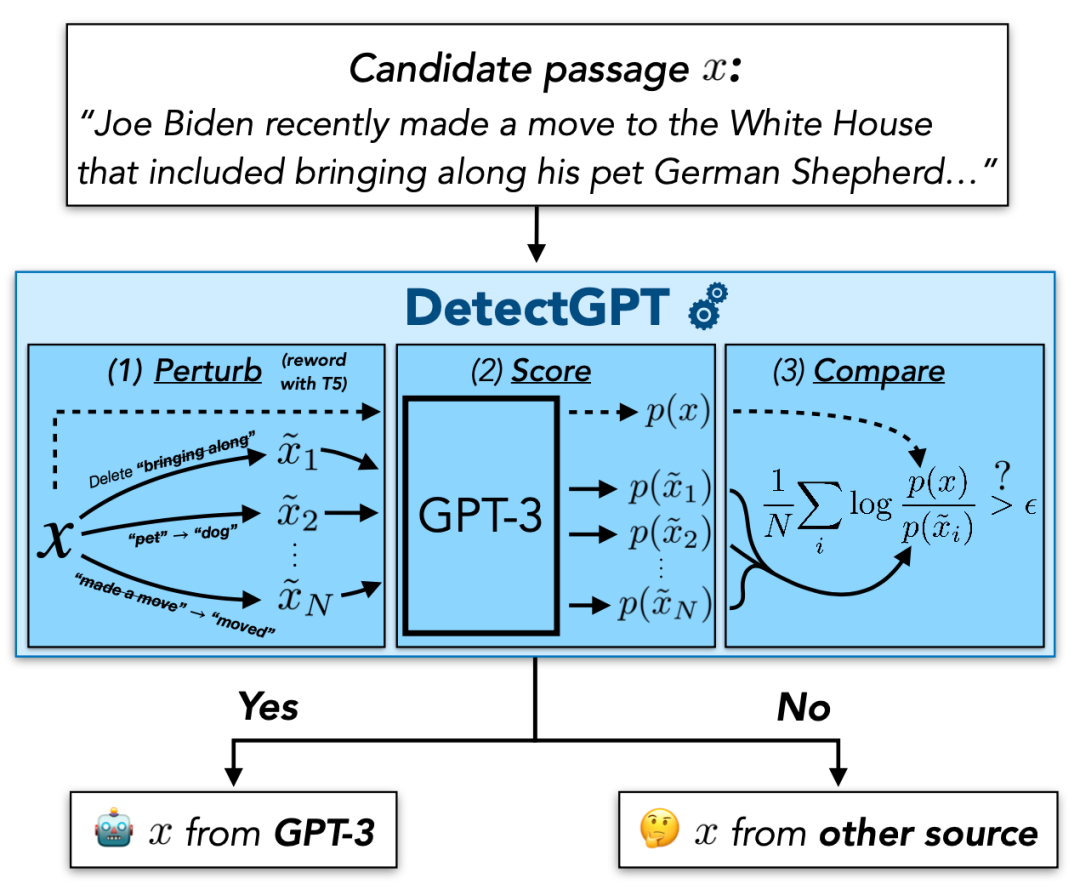
图|确定一段文本是否由特定的 LLM 生成。(来源:该论文)
据论文描述,DetectGPT 可以将 20B 参数 GPT-NeoX 生成的假新闻文章的检测从 0.81 AUROC 提高到 0.95 AUROC。
研究团队表示,这一方法在检测机器生成的文本方面优于其他零样本方法,或在未来的机器生成文本检查方面非常有前途。另外,他们也将尝试将这一方法用于 LLM 生成的音频、视频和图像的检测工作中。
然而,这一方法也存在一定的局限性。例如,如果现有的掩模填充模型不能很好地表示有意义的改写空间,则某些域的性能可能会降低,从而降低曲率估计的质量;以及 DetectGPT 相比于其他检测方法需要更多的计算量等。
未来,随着 LLM 的不断改进,它们将成为越来越有吸引力的工具,可以在各种环境(比如教育、新闻和艺术)中取代人类作家。
尽管在所有这些环境中都存在语言模型技术的合法使用,但教师、读者和消费者可能需要工具来验证具有高度教育、社会或艺术意义的某些内容是否来自人类,特别是在真实性(而不仅仅是流畅性)至关重要的情况下。
参考链接: