
Prompt之文本生成
作者简介
作者:LaBuenaVida
原文:
https://zhuanlan.zhihu.com/p/521512441
转载者:杨夕
推荐系统 百面百搭地址:
https://github.com/km1994/RES-Interview-Notes
NLP 百面百搭地址:
https://github.com/km1994/NLP-Interview-Notes
个人笔记:
https://github.com/km1994/nlp_paper_study
NLP && 推荐学习群【如果人数满了,加微信 blqkm601】
prompt在生成方面的应用从两个方面进行介绍:
评估手段
具体任务
评估手段
生成任务的评估手段主要分为四种类型:
1). 基于N-gram匹配 2). 基于编辑距离 3). 基于词向量 4). 基于可学习方式。
本小节主要介绍BARTSCORE,其使用prompt方式将评估问题转化为文本生成问题的可学习方式。
自然语言生成的自动评估的目标是评估语义相似性,但通常的方法只是依赖于表面形式的相似性,因此,BERTSCORE借助预训练模型BERT的embedding来衡量两个句子的语义相似性。
BERTSCORE解决了基于N-gram匹配的两个问题:
1)、无法鲁棒匹配语义;
2)、无法捕捉远距离依赖关系和惩罚重要语义顺序的更改。
BARTScore: Evaluating Generated Text as Text
论文链接:https://arxiv.org/pdf/2106.11520.pdf
相较于以往的评估方式,在生成评估的背景下,模型如何使用文本生成任务目标进行预训练和如何被使用作为下游任务的特征提取器之间存在脱节。这将导致预训练模型参数没有被充分利用。该论文将文本生成的评估问题看作生成问题,能够从七个角度评估生成文本的质量,并可以通过prompt和fine-tuning来增强BARTSCORE。
BARTSCORE的核心思想为,一个高质量的假设能够很容易地基于源文本或参考文本生成,反之亦然。计算方式如下,wt 为待生成句子中token的权重(加权重效果不好):
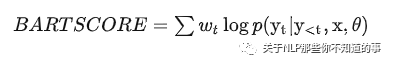
具体计算含义如下所示:
| Calculation | Implication | Evaluation & Application |
|---|---|---|
| Faithfulness(s->h) | 从source document生成hypothesis的概率 | Factuality,Relevance,Coherence and Fluency |
| Precision(r->h) | 从reference text生成hypothesis的概率 | precision-focused scenario |
| Recall(h->r) | 从hypothesis生成reference text的概率 | semantic coverage |
| F-score(r<->h) | 综合考虑Precision和Recall | semantic overlap(informativeness,adequacy) |
prompt增强:对于给定的prompt token:
(i)在source token后添加prompt token:
x = { x 1 , . . . , x n , z 1 , . . . , z l }; (ii)在target token前添加prompt token:
y = { z 1 , . . . , z l , y 1 , . . . , y m } 。prompt的模板集合通过paraphrase重构种子模板获取得到。
fine-tuning 任务:
1). summarization 任务,使用CNNDM数据集;
2). paraphrasing任务,使用ParaBank2数据集。
在多个实验中,BARTSCORE取得了很好的效果,但是引入prompt也有可能会导致效果变差,在事实性评估角度中,只有少数的prompt可以提升性能。
具体任务
本小节介绍三篇使用prompt进行文本生成任务的论文,涵盖摘要、QA、诗歌生成、回复生成多个任务。
Generation Planning with Learned Entity Prompts for Abstractive Summarization
论文链接:https://arxiv.org/pdf/2103.10685.pdf
该论文通过引入简单灵活的中间过程来生成摘要,构造prompt prefix提示生成对应的实体链和摘要,prompt模板为:[ENTITYCHAIN] entity chain [SUMMARY] summary,该方式使模型能够学会链接生成的摘要和摘要中的实体链。另外,可以通过删除预测实体链中的不可靠实体来生成可靠摘要,更为灵活。
Controllable Generation from Pre-trained Language Models via Inverse Prompting
论文链接:https://arxiv.org/pdf/2103.10685.pdf
可控文本中给的提示原不足够,这导致易在生成过程中逐渐偏离主题,因此该论文提出inverse prompt来更好的控制文本生成,激励生成文本与prompt之间的联系。模型结构如下图所示:
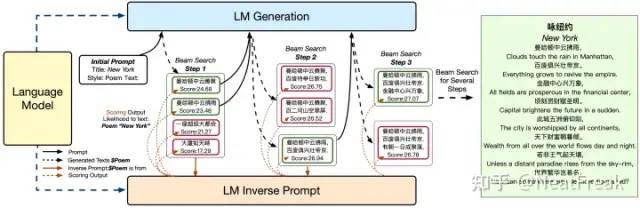
具体做法为:
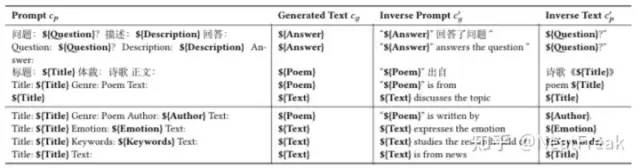
根据给定的生成文本构造inverse prompt,对应图中表格Inverse Prompt
c g ′ 根据给定的inverse prompt计算其原始prompt,对应图中表格Inverse Text
c p ′ 依据条件似然计算beam search的分数,生成最佳候选。
实验证明该方法在QA和诗歌生成两个任务上均可以取得很好的效果,能够给出准确流利的信息。但同时也存在数字输出混乱和无法理解出现频率低的词的问题。
Response Generation with Context-Aware Prompt Learning
论文链接:https://arxiv.org/pdf/2111.02643.pdf
该论文设计了一个新颖的动态prompt编码器来鼓励上下文感知的prompt learning,以更好地重利用大规模预训练语言模型中的知识并生成更有知识的回复。模型结构如下图所示:
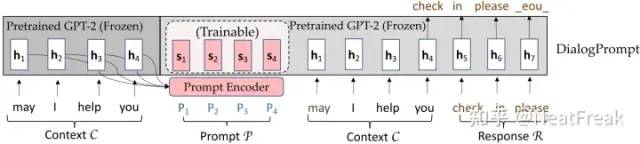
首先将上文文本的embedding送入可学习的prompt编码器中获得感知上文的prompt编码表示,再同时利用prompt的编码表示和上文文本来预测下文。论文中实验证明该方法可以有效利用预训练语言模型中的知识来促进富有知识的高质量回复。