
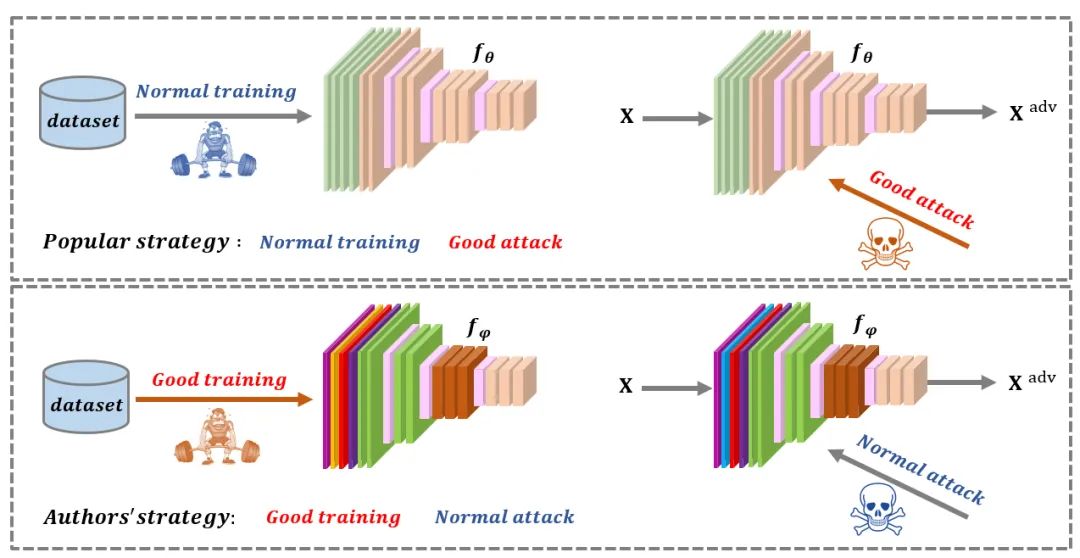
TIP'22|目标迁移性新解法开源!阿里提出:从数据分布的角度提高对抗样本的可迁移性

极市导读
与过去从模型的视角分析迁移性不同,本文从数据本身出发,从数据分布的视角给出了对抗样本迁移性的一种理解。实验表明,本文的方案是目前迁移性最佳的攻击方法,在某些场景下可以超过现有方法40%以上。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
引言

预备知识
论文方法
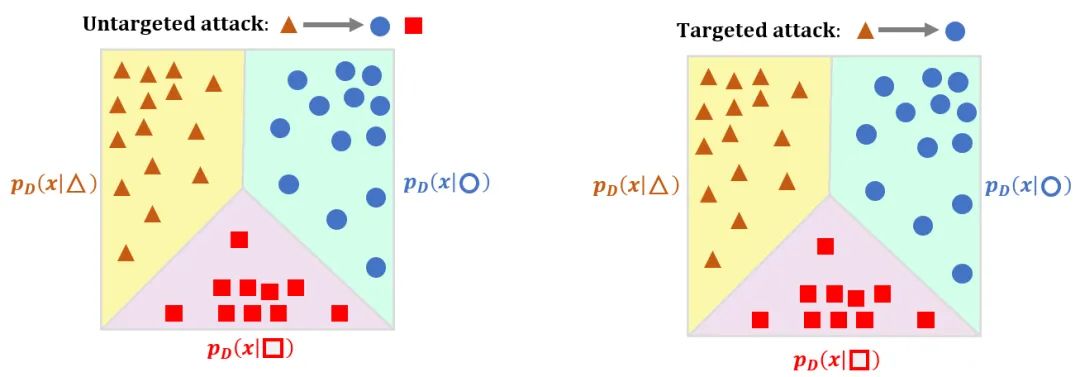
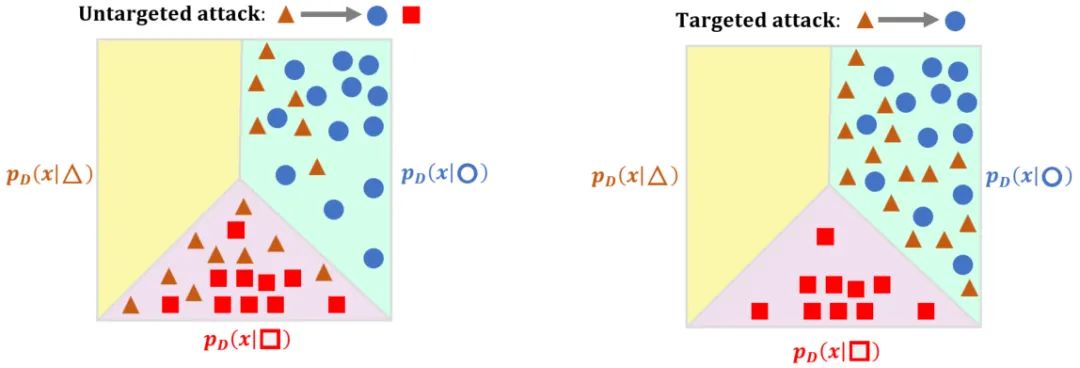
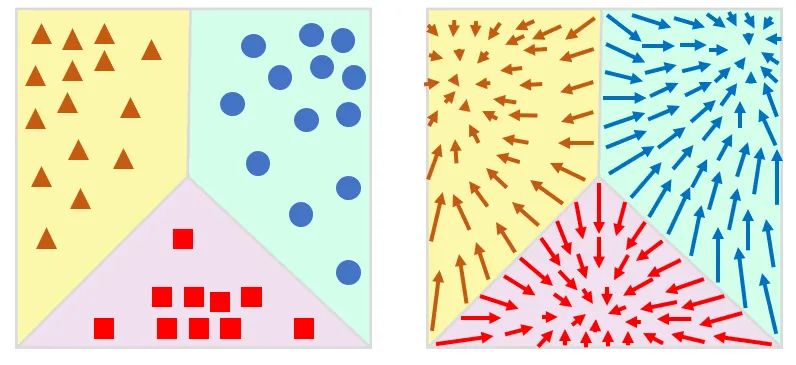
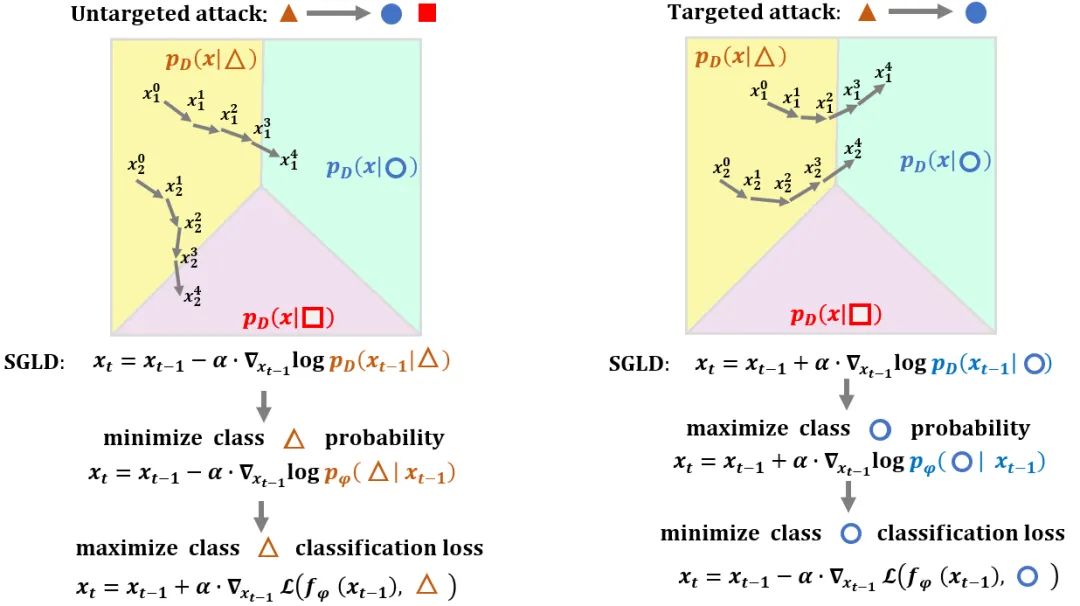
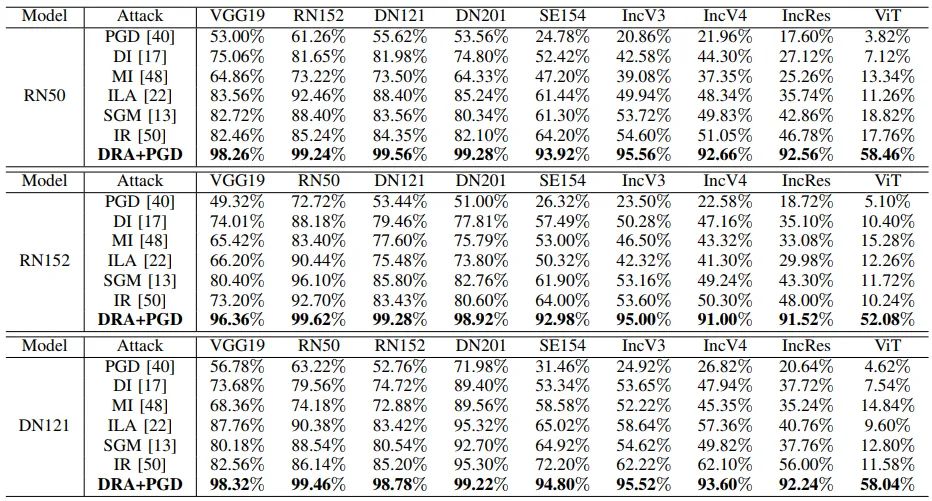
实验结果

代码实现
from torchvision import datasets, transforms
from torch.utils.data import DataLoader, Dataset
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.optim as optim
import torch.nn.functional as F
import os
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(784, 300)
self.fc2 = nn.Linear(300, 100)
self.fc3 = nn.Linear(100, 10)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
out = self.fc3(x)
return out
def DR_training():
randon_number = 1
lambda_ = 1
epoch = 5
model = Net()
optimizer = torch.optim.SGD(model.parameters(), lr=0.005)
loss_fn = torch.nn.CrossEntropyLoss()
use_cuda = torch.cuda.is_available()
mnist_transform = transforms.Compose([transforms.ToTensor(), transforms.Lambda(lambda x : x.resize_(28*28))])
mnist_train = datasets.MNIST(root="mnist-data", train=True, download=True, transform=mnist_transform)
train_loader = torch.utils.data.DataLoader(mnist_train, batch_size=32, shuffle=True, num_workers=0)
for epoch_idx in range(epoch):
for batch_idx, (inputs, targets) in enumerate(train_loader):
if use_cuda:
inputs, targets = inputs.cuda(), targets.cuda()
inputs, targets = Variable(inputs), Variable(targets)
inputs.requires_grad_(True)
predict = model(inputs)
CE_loss = loss_fn(predict, targets)
# DCG loss
log_pro = torch.log(F.softmax(predict, 1))
log_pro_target = log_pro.gather(1, targets.view(-1,1)).squeeze(1)
grad = torch.autograd.grad(log_pro_target, inputs, grad_outputs = torch.ones_like(log_pro_target), retain_graph = True, create_graph=True)
DCG_grad_loss = torch.mean(torch.norm(grad[0], dim = 1, p = 2))
Hessian = torch.tensor([])
for anygrad in grad[0].T:
Hessian_entry = torch.autograd.grad(anygrad, inputs, grad_outputs = torch.ones_like(anygrad), retain_graph = True, create_graph=True)
Hessian_temp = Hessian_entry[0].unsqueeze(2)
Hessian = torch.cat((Hessian, Hessian_temp), 2)
DCG_Hessian_loss = 0
for idx in range(randon_number):
v = (torch.randn_like(inputs) + 1).unsqueeze(1)
v_t = v.permute(0, 2, 1)
DCG_Hessian_loss += torch.mean((torch.bmm(torch.bmm(v, Hessian), v_t)))
DCG_Hessian_loss = DCG_Hessian_loss / randon_number
DCG_loss = DCG_grad_loss + 2 * DCG_Hessian_loss
loss = CE_loss + lambda_ * DCG_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('successful')
if __name__ == '__main__':
DR_training()
公众号后台回复“CNN100”,获取100 篇 CNN 必读的经典论文资源下载
极市干货
技术干货:数据可视化必须注意的30个小技巧总结|如何高效实现矩阵乘?万文长字带你从CUDA初学者的角度入门
实操教程:Nvidia Jetson TX2使用TensorRT部署yolov5s模型|基于YOLOV5的数据集标注&训练,Windows/Linux/Jetson Nano多平台部署全流程

# 极市原创作者激励计划 #
极市平台深耕CV开发者领域近5年,拥有一大批优质CV开发者受众,覆盖微信、知乎、B站、微博等多个渠道。通过极市平台,您的文章的观点和看法能分享至更多CV开发者,既能体现文章的价值,又能让文章在视觉圈内得到更大程度上的推广,并且极市还将给予优质的作者可观的稿酬!
我们欢迎领域内的各位来进行投稿或者是宣传自己/团队的工作,让知识成为最为流通的干货!
对于优质内容开发者,极市可推荐至国内优秀出版社合作出书,同时为开发者引荐行业大牛,组织个人分享交流会,推荐名企就业机会等。
评论