
副业1000元,文末有代码,制作一个谷歌浏览器插件,实现网页数据爬虫
一、什么是浏览器插件
浏览器插件,基于浏览器的原有功能,另外增加新功能的工具,是可定制浏览体验的小型软件程序,让用户可以根据个人需要或偏好来定制浏览器。
如拦截网页中的广告、划词翻译、倍速视频等等。
Chrome、edge等浏览器中都有专门的插件下载商店。 受某些原因限制,Chrome服务并不能正常访问
这里提供几个常用的浏览器插件下载地址:
Chrome插件,谷歌浏览器插件下载,chrome谷歌商店插件crx应用推荐与下载-扩展迷
Chrome插件,Chrome商店,谷歌浏览器插件下载,谷歌商店 - Chrome插件网
极简插件_Chrome扩展插件商店_优质crx应用下载
有兴趣的小伙伴可以进入网站看看有没有感兴趣的、满足自己定制化需求的插件。
如何开发浏览器插件
假如小伙伴找了半天,发现网上并没有满足自身需求的插件,那么你是否会考虑自己做一个呢?
其实这并不是什么高大上的事,网上那么多好用的浏览器插件都是开发者基于Chrome开放出的浏览器插件api完成的。
Chrome已经把可能用到的各种“砖”封装好开放出来了,那我们只需要按照一定的规则“搬”就行了啊。
开发插件之前,我们首先要了解的是插件都有哪些能力,什么能实现,什么不能实现。
如果你想点一点就把15寸的笔记本屏放大到30寸,用完让屏幕再缩小回去,那这插件肯定是实现不了的。
相关文档:
chrome谷歌浏览器开发文档
360浏览器综述--扩展开发文档
浏览器扩展 - Mozilla | MDN
以上都是通篇文档,可能对新手并不友好,读起来枯燥无味。
下面推荐一个能快速上手的博客,同时感谢该作者的技术输出。Chrome插件(扩展)开发全攻略(干货)
常见爬虫方法的对比
后面我们会实现一个爬虫功能的插件。 在开始实战之前,我们可以先聊一聊常见爬虫能力的优缺点。
api接口 该方法速度快,容易上手,会任意编程语言都可以实现,且操作用户对此无感知。
但同时也有很大的缺点,这种方法很难同时发起用户行为收集请求,有些产品会通过这些行为收集接口分析用户的操作,如果逻辑变化,需要手动更新代码到客户处。
如果只有数据接口请求,没有统计接口请求,很容易被判定为爬虫,从而产生一系列负面影响。
有些产品还会有加密代码,需要一些逆向工作,这就更进一步提高这种方法爬取数据的难度了。
Selenium 该方法是通过运行测试的开源工具实现的,常见编程语言都有对应的工具,相较于第一种方法有着更广范围的应用场景。
该方法通过启动相关驱动支持的真实的浏览器,尽可能的模拟用户操作,相关行为分析会自动请求,几乎不需要逆向,一定程度上填补了第一种方法的弊端。
但同时该方法也有弊端,需要给客户机安装运行环境和客户的Chrome浏览器升级等问题。
浏览器升级可能导致Selenium驱动版本和浏览器版本不匹配,程序就会运行失败。逻辑变化需要手动更新到客户处。
该方式也会被产品方识别出是程序启动而不是真实用户启动的浏览器,从而产生负面影响。
浏览器插件 该方法是通过浏览器的开放能力实现的,是用户启动的真实浏览器,进一步填充了前两种方法的弊端,通过各种形式的脚本实现复杂的操作。
可以发布到像app发布到应用商店一样发布到浏览器应用商店,且提供线上更新功能。
该方法必须得会JavaScript脚本语言,同时熟知浏览器的开放能力,增加了学习难度。
该方法仍可以被产品识别出,如使用 MutationObserver 方法检测出dom变化等。
没有完美的方法,只有更适合的方法,不同场景使用不同的技术应对不同的困难即可。
实现一个浏览器爬虫插件
介绍完常见爬虫的区别后,接下来,我们就开始实现一个浏览器爬虫插件。
此处假设小伙伴已经阅读上述推荐的博客并基本熟悉浏览器插件的能力。
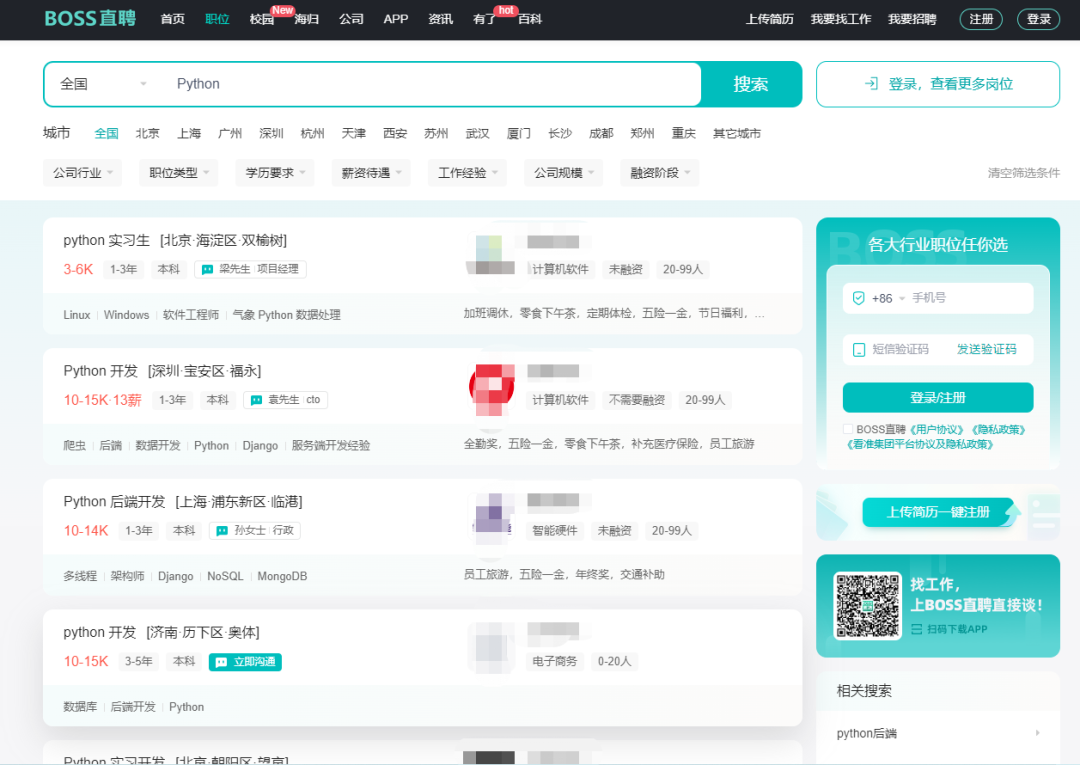
需求:爬取10页boss直聘网站上全国范围内Python岗位的招聘信息。
拆解需求:
目标网站:
boss直聘网站
筛选条件:
城市:全国 关键词:Python
数量:
1-10页内的全部数据
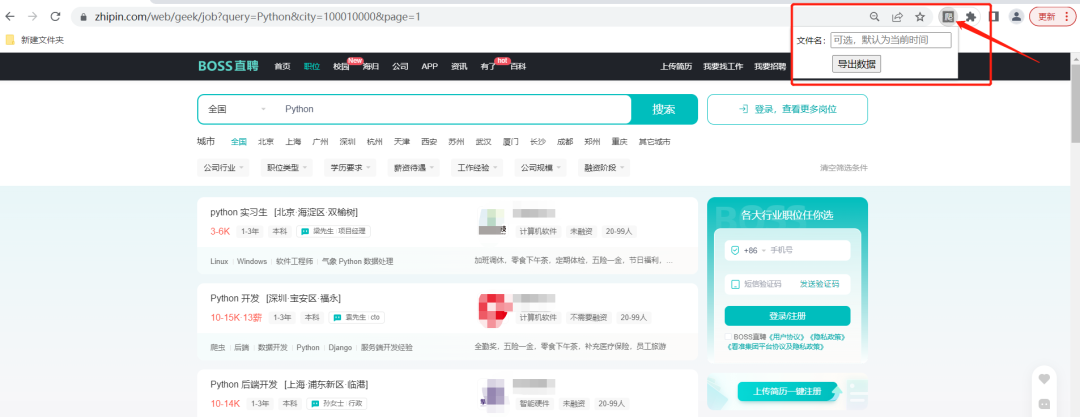
url地址:https://www.zhipin.com/web/geek/job?query=Python&city=100010000&page=1
难点分析
使用什么脚本类型
插件有injected、content、popup、background、devtools 5种类型的脚本,不同类型拥有不同的能力,相互之间的通信方式也不尽相同。
所以首先需要根据需求结合具体类型脚本的能力来确定使用什么脚本。
popup肯定是需要的,给文件指定名称和下达开始爬取的命令时要用到该类型脚本。
此处已确定popup脚本,其他类型待定。
拦截网络请求
经分析,从dom结构中获取数据不靠谱。 如,跳转链接,某些产品的链接并不放在dom中,而是通过点击事件句柄判断按钮的index、id等唯一标识,从js作用域中找到对应的链接进行跳转。
那么就需要考虑怎么能拦截到网络请求了。插件的核心是不同类型js脚本,不同类型的脚本能力不同,需结合实际考虑。
在5种脚本类型对比可知,只有injected、devtools、background可以拦截到网络请求。但background拿不到响应体,故抛弃。
devtools功能很强大,它可以模拟出一个和开发者工具(F12)-网络(network)功能几乎一样的面板,但实现起来会相对复杂。
前端同学常用的React Developer Tools、vue-tools调试面板就是使用该技术开发的。
经过权衡对比,使用更加简单的injected来做网络拦截。
此处已确定popup和injected两种脚本。
通信
爬取过程很简单,通信是一件复杂的事,详情通信可参考上述文档。
现在的流程是 injected拦截网络请求 -> popup下达开始爬取的指令 -> injected开始执行脚本收集数据 -> injected清洗并导出数据。
现在确定的popup和injected两种类型能满足吗?很遗憾,不能,通过上述博客中总结的通信方式可知,这两种类型的脚本不能直接通信,也就是popup不能告诉injected可以开始收集数据了。
怎么实现呢?需要引入一个“中介”——content,作为popup和injected中间通信的桥梁。
现在的过程就变成了,injected拦截网络请求 -> popup下达开始爬取的指令 -> content转发指令-> injected开始执行脚本收集数据 -> injected清洗并导出数据
这里可以留一个小问题,最后一步可以使用content实现吗,为什么不使用这种方式?
此处已确定popup和injected、content三种脚本。
代码部分
确定脚本选型后就可以创建工程了,新建一个文件夹,创建如下的目录结构:
boss-plugin
├─ html
│ └─ popup
│ ├─ popup.html // 点击浏览器右上角插件,弹出popup,传递用户指令
│ └─ popup.js
├─ js
│ ├─ content // content脚本通过manifest.json配置文件可以直接添加到页面中
│ │ ├─ install.js // injected脚本并不能直接通过配置添加到页面中,需要通过content执行js代码动态插入到dom中
│ │ └─ page.js // “中介角色”,转发指令
│ └─ inject
│ ├─ network.js // 拦截网络请求
│ ├─ page.js // 具体执行收集、清洗、导出数据的逻辑
│ └─ pikazExcel.js // 导出数据为Excel的js类库
└─ manifest.json // 浏览器识别插件配置的文件,必须
manifest.json
{
"name": "爬取boss数据",
"version": "1.0",
"manifest_version": 2,
"browser_action": {
"default_popup": "/html/popup/popup.html"
},
"content_scripts": [
{
"matches": ["*://www.zhipin.com/*"],
"js": ["/js/content/page.js", "/js/content/install.js"],
"run_at": "document_start"
}
],
"web_accessible_resources": [
"/js/inject/pikazExcel.js",
"/js/inject/page.js",
"/js/inject/network.js"
]
}
html/popup/popup.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<style>
#box {
align-items: center;
}
#input-box {
display: flex;
align-items: center;
}
.label {
white-space: nowrap;
}
#btn-box {
padding-left: 50px;
padding-top: 10px;
}
</style>
</head>
<body>
<div id="box">
<div id="input-box">
<span class="label">文件名:</span>
<input id="filename" type="text" placeholder="可选,默认为当前时间" />
</div>
<div id="btn-box">
<button id="export-btn">导出数据</button>
</div>
</div>
<script src="/html/popup/popup.js"></script>
</body>
</html>
html/popup/popup.js
function onClickExport() {
document.getElementById('export-btn').disabled = true
const filename = document.getElementById('filename').value
const cb = (tab) => {
chrome.tabs.sendMessage(tab.id, { action: "CHANGE_POPUP_ALLOW_DOWNLOAD", filename });
}
chrome.tabs.getSelected(null, cb);
}
document.getElementById('export-btn').onclick = onClickExport
js/content/install.js
setTimeout(() => {
const pageScript = document.createElement('script');
pageScript.setAttribute('type', 'text/javascript');
pageScript.setAttribute('src', chrome.extension.getURL("/js/inject/page.js"));
document.head.appendChild(pageScript);
const networkScript = document.createElement('script');
networkScript.setAttribute('type', 'text/javascript');
networkScript.setAttribute('src', chrome.extension.getURL('/js/inject/network.js'));
document.head.appendChild(networkScript);
const excelScript = document.createElement('script');
excelScript.setAttribute('type', 'text/javascript');
excelScript.setAttribute('src', chrome.extension.getURL("/js/inject/pikazExcel.js"));
document.head.appendChild(excelScript);
});
js/content/page.js
// 转发popup指令 popup => content script => inject script
chrome.extension.onMessage.addListener(
function (request) {
if (request.action == "CHANGE_POPUP_ALLOW_DOWNLOAD") {
// popup 告诉页面可以开始收集并下载数据了
window.postMessage({ action: 'CHANGE_POPUP_ALLOW_DOWNLOAD', popupAllowDownload: true, filename: request.filename }, '*');
}
}
);
js/inject/network.js
此处需要注意浏览器发起请求的两种方式:xhr和fetch,前者使用较多,后者也在开发过程中见到过。
const _requestTools = {
formatQueryString(queryString = '') {
const result = {};
if (queryString.length > 0) {
queryString = queryString.split('?')[1].split('&');
for (let kv of queryString) {
kv = kv.split('=');
if (kv[0]) result[kv[0]] = decodeURIComponent(kv[1]);
}
}
return result
}
}
function _initXMLHttpRequest() {
// 拦截网络请求方法1
const open = XMLHttpRequest.prototype.open;
const _targetApiList = [
'wapi/zpgeek/search/joblist.json'
]
XMLHttpRequest.prototype.open = function (...args) {
this.addEventListener('load', function () {
// 如果当前url并不包含_targetApiList中任意一个地址,则阻止后续操作
if (!_targetApiList.find(item => this.responseURL.includes(item))) return
const result = {
responseHeaders: {},
responseData: {},
request: this,
status: this.status,
params: _requestTools.formatQueryString(this.responseURL)
}
// 格式化响应头
this.getAllResponseHeaders().split("\r\n").forEach((item) => {
const [key, value] = item.split(": ");
if (key) result.responseHeaders[key] = value;
});
if (result.responseHeaders["content-type"].includes("application/json")) {
// 如果响应头是content-type是json,则格式化响应体
if (this.response?.length) result.responseData = JSON.parse(this.response);
}
_crawler.collectData(result)
})
return open.apply(this, args);
};
// 拦截网络请求方法2
// 此处的方法拦截在目标网站中并没有遇到,在其他项目中遇到过,故添加在此做补充知识点。
const { fetch: originalFetch } = window;
window.fetch = async (...args) => {
let [resource, config] = args;
let response = await originalFetch(resource, config);
if (response.status === 200) {
response
.clone()
.json()
.then((data) => {
console.log('响应数据:', data)
});
}
return response;
};
}
_initXMLHttpRequest();
js/inject/page.js
// 因为inject js和页面共享js作用域,为防止污染全局变量,故插件中变量名都以_开头
class _Crawler {
constructor() {
this.downloadPageNum = 10 // 允许下载多少页
this.filename = '' // 从popup传进来的输入的文件名
this.allowDownload = false // popup给出指令允许下载
this.collectionList = [] // 收集每页请求得到的数据
}
/**
* 获取当前年-月-日 时:分:秒
* @returns string
*/
getTime() {
const time = new Date();
const timeInfo =
(time.getFullYear() + '-' + (time.getMonth() + 1) + '-' + time.getDate() + ' ' + time.getHours() + ':' + time.getMinutes() + ':' + time.getSeconds())
return timeInfo
}
// 生成随机延迟秒数, 默认3-4秒
getRandomTimeOut(x = 3000, y = 4000) {
return Math.round(Math.random() * (y - x) + x)
}
collectData(result) {
// 首次进来或搜索条件变化,清空收集结果
const currentPage = result.params.page * 1;
if (currentPage * 1 === 1) this.collectionList = []
if (!this.collectionList.find(el => result.request.responseURL.includes(el.responseURL))) {
const item = {
responseURL: result.request.responseURL,
responseData: result.responseData
}
this.collectionList.push(item)
}
// 如果没有点击导出按钮,则阻止后续操作
if (!this.allowDownload) return
// 结束收集行为的条件,然后进行数据清洗和导出excel
if (currentPage >= this.downloadPageNum) {
const sheet = this.clearData()
this.download(sheet)
} else {
// 随机3-4秒后进行点击下一页
// 这是写爬虫最基本的道德了,尽量在学习技术的同时,不要对目标服务器产生压力和影响其正常运行
const randomTimeout = this.getRandomTimeOut()
setTimeout(() => {
this.handleClickNext()
}, randomTimeout);
}
}
clearData() {
const headerAndKeyList = [
{
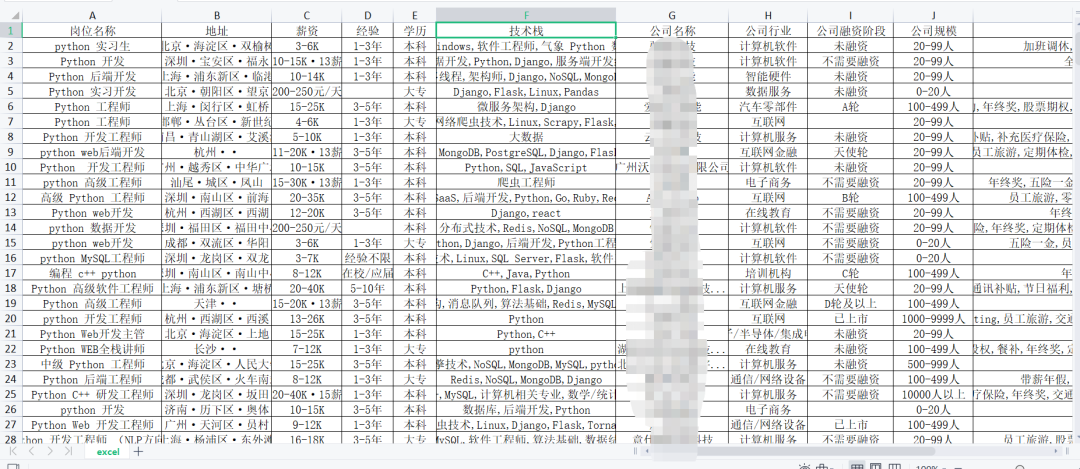
header: '岗位名称',
key: 'jobName'
},
{
header: '地址',
key: 'jobAddress'
},
{
header: '薪资',
key: 'salaryDesc'
},
{
header: '经验',
key: 'jobExperience'
},
{
header: '学历',
key: 'jobDegree'
},
{
header: '技术栈',
key: 'skills'
},
{
header: '公司名称',
key: 'brandName'
},
{
header: '公司行业',
key: 'brandIndustry'
},
{
header: '公司融资阶段',
key: 'brandStageName'
},
{
header: '公司规模',
key: 'brandScaleName'
},
{
header: '福利待遇',
key: 'welfareList'
},
]
const itemTableConfig = {
tHeader: headerAndKeyList.map(el => el.header),
keys: headerAndKeyList.map(el => el.key),
table: []
}
this.collectionList.forEach(el1 => {
el1.responseData.zpData.jobList.forEach(el2 => {
const { jobName, cityName, areaDistrict, businessDistrict, salaryDesc, jobExperience, jobDegree, skills, brandName, brandIndustry, brandStageName, brandScaleName, welfareList } = el2
const item = {
jobName,
jobAddress: `${cityName}·${areaDistrict}·${businessDistrict}`,
salaryDesc, jobExperience, jobDegree, skills, brandName, brandIndustry, brandStageName, brandScaleName, welfareList
}
itemTableConfig.table.push(item)
})
})
return [itemTableConfig]
}
download(sheet) {
const filename = this.filename || this.getTime()
window.pikazExcelJs.default.excelExport({
sheet,
filename,
beforeStart: (bookType, filename, sheet) => {
console.log("开始导出", bookType, sheet, filename);
},
}).then(() => {
this.filename = ''
this.allowDownload = false
this.collectionList = []
});
}
handleClickNext() {
const nextSelector = '.pagination-area .options-pages a:last-child'
const nextDom = document.querySelector(nextSelector)
nextDom.click()
// 如果目标网站有收集用户行为的接口,此处可添加模拟用户操作,如滚动页面、点击某些元素
}
}
const _crawler = new _Crawler();
// 监听从popup发送的指令 popup => content script => inject script
window.addEventListener("message", function (e) {
if (e.data.action === 'CHANGE_POPUP_ALLOW_DOWNLOAD') {
_crawler.filename = e.data.filename
_crawler.allowDownload = true
_crawler.handleClickNext()
}
}, false);
js/inject/pikazExcel.js
文档和下载地址:
https://www.npmjs.com/package/pikaz-excel-js
最后在Chrome浏览器中打开这个地址 chrome://extensions/
开启开发者模式 -> 加载已解压的扩展程序 -> 选择刚才新建的文件夹 -> 确认导入
这时候就已经把刚才编写的导入到浏览器中了,打开目标页面
然后点击红框区域,输入文件名(可选),点击导出数据,就可以开始爬取内容了
最终效果:
参考链接,感谢以下链接提供相关技术的解决思路:
XMLHttpRequest 拦截处理
Chrome插件(扩展)开发全攻略(干货)
pikaz-excel-js
代码下载地址
链接:https://pan.baidu.com/s/1RHYE-CuZqmBJm7Wj9G4fYQ
提取码:u5cp
如果想接副业单子
如果想跟着蚂蚁老师做副业兼职,可以每晚22点来蚂蚁老师抖音直播间:
抖音账号:Python导师-蚂蚁