
盘点一个使用Python实现Excel中找出第一个及最后一个不为零的数,它们各自在第几列
共 2216字,需浏览 5分钟
· 2022-11-25
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是皮皮。
一、前言
前几天在小小明大佬的Python交流群中遇到一个粉丝问了一个使用Python实现Excel中找出第一个及最后一个不为零的数,它们各自在第几列的问题,觉得还挺有用的,这里拿出来跟大家一起分享下。
数据截图如下所示:
二、实现过程
这里【小小明】大佬给了一个方法,使用Pandas实现,如下所示:
# code by:小小明大佬
import pandas as pd
df = pd.read_excel('Data.xlsx', header=1, usecols="B:K")
result = []
for row in df.itertuples():
code = row.Index
row = pd.Series(row[1:])
row.index += 1 # 默认索引从0开始,但是他要求编号从1开始
row = row[row != 0]
# print(row)
s_num, s_i, e_num, e_i = [pd.NA] * 4
if row.shape[0] > 0: # row.shape[0],row是过滤后的数据,row.shape[0]非零数据的长度,等价于len(row)
s_num, s_i, e_num, e_i = row.iat[0], row.index[0], row.iat[-1], row.index[-1]
result.append([code, s_num, s_i, e_num, e_i])
result = pd.DataFrame(result, columns=["产品编码", "起始数", "起始位置", "结束数", "结束位置"])
print(result)
运行之后,可以得到预期的结果: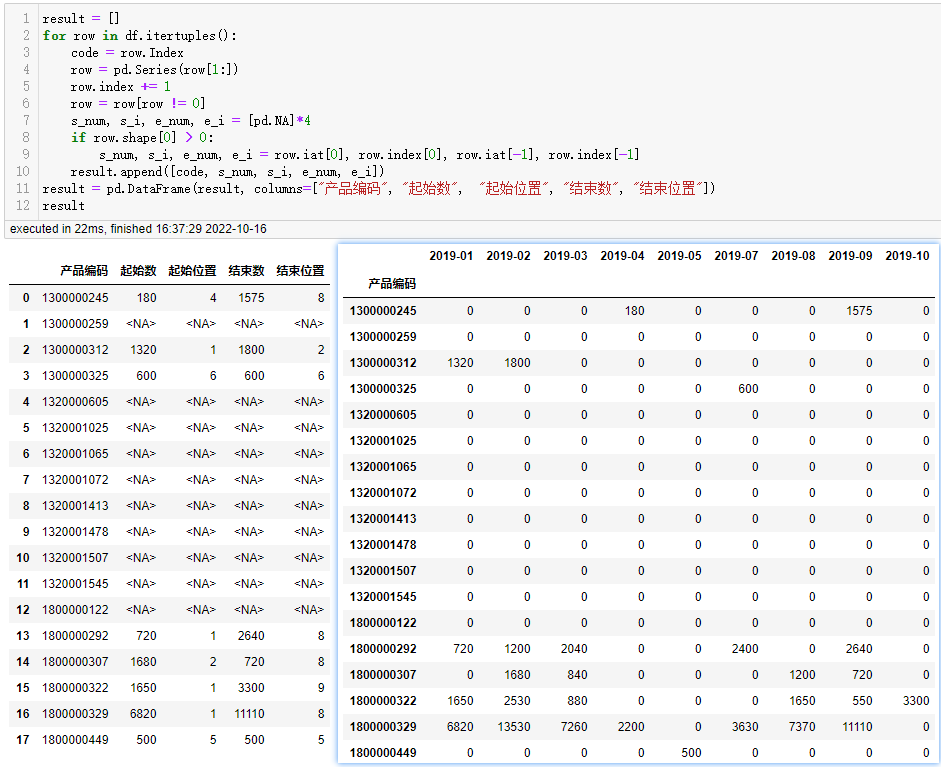 顺利地解决了粉丝的问题。
顺利地解决了粉丝的问题。
这里再补充下,df.itertuples()生成一个namedtuples类型数据,name默认名为Pandas,可以在参数中指定。
与df.iterrows()相比,df.itertuples()运行速度会更快一些,推荐在数据量庞大的情况下优先使用。
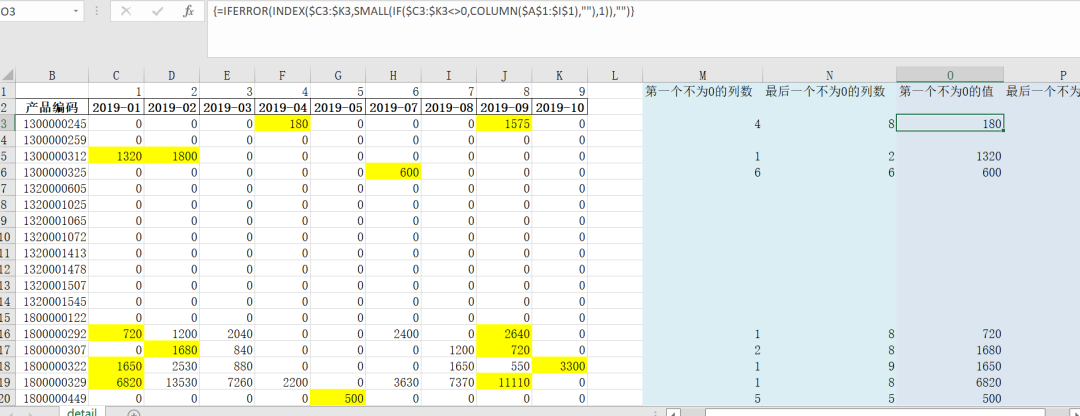
群里卧虎藏龙的,后来也有大佬给了一个Excel实现的方式,如下所示:
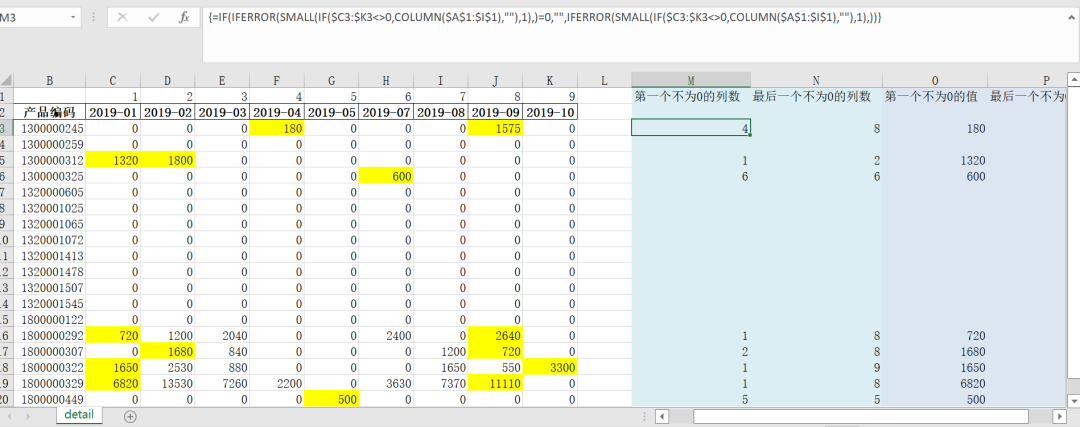
这个Excel的功夫算是到家了,公式确实写的长。
你以为这就完了?NO!
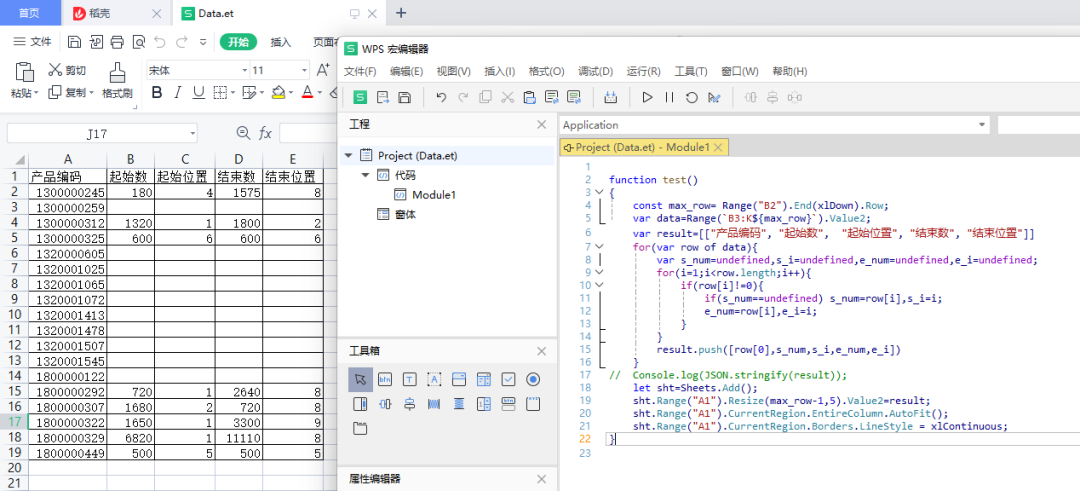
后来明佬还基于WPS宏代码实现了这个需求,实在是太强了!我对宏代码实现不了解,这里发出来给大家观摩了,感兴趣的小伙伴自行学习下,如下图所示。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python实现Excel中筛选数据的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。文中一共提供了三个方法,分别是使用Python,Excel公式实现,以及宏代码实现,干货满满!
最后感谢粉丝提问,感谢【小小明】大佬给出的思路和代码解析,感谢【皮皮】等人参与学习交流。
大家在学习过程中如果有遇到问题,欢迎随时联系我解决(我的微信:pdcfighting),应粉丝要求,我创建了一些高质量的Python付费学习交流群和付费接单群,欢迎大家加入我的Python学习交流群和接单群!

小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~