
ECCV 2022|通过 Diffusion-based Stereo 进行高质量人体重建
共 4554字,需浏览 10分钟
· 2022-11-24
来源:ECCV 2022
原标题:DiffuStereo: High Quality Human Reconstruction via Diffusion-based Stereo Using Sparse Cameras
论文作者:Ruizhi Shao, Zerong Zheng, Hongwen Zhang, Jingxiang Sun, and Yebin Liu
内容整理:王彦竣
本文提出了 DiffuStereo ,一个基于 Diffusion model 的稀疏相机高质量人体表面重建算法。它创新性地提出了一个基于 Diffusion model 的多层级立体匹配 (stereo match) 网络,在合理运算量下处理高质量 (4K) 图像。基于一系列稀疏相机 (8个) 的彩色图像,该模型可以生成高质量的三维人体表面。
目录
引言
方法
网格模型、深度、视差初始化
用于视差图细化的Diffusion-based Stereo
轻量多视角融合模块
实验
总结
引言
高质量的三维人体表面重建,主要有两种路线,一种是基于密集相机阵列与定制的光照条件的设备,另一种则是基于深度学习的方法,如预测神经隐式函数,从单目或多目RGB,RGBD重建表面。然而目前学习的方法的重建效果与传统的密集阵列方法仍存在较大的差距,即便有多目的输入,现有学习方法仍无法取得高精度的重建模型。这些方法主要基于单个图像的人体以及高层级的语义特征来估计几何特征,但忽视了不同视角间的关系。相反的,密集相机阵列的方法显式地进行立体匹配来对不同视角的输入建立密集联系,并用于模型深度的计算,因此这些方法不需要数据先验来实现准确重建。
因此,作者认为在学习法中引入立体匹配可以显著提升稀疏重建的效果。然而现有的立体匹配方法受限于像素级别的代价体积(cost volume),重建的深度图无法实现亚像素精度。同时,受限于计算量,输入图像分辨率较低,因此无法实现高质量的深度图重建。而 diffusion model 可以迭代地对图像进行细化,从而在高分辨率下生成高精度的图像。传统的立体匹配基于连续变分公式,与而 diffusion model 被视为学习求解连续随机微分方程,与立体匹配的方式相似。因此作者在立体匹配中引入 diffusion model,来实现高质量的人体深度估计。

方法
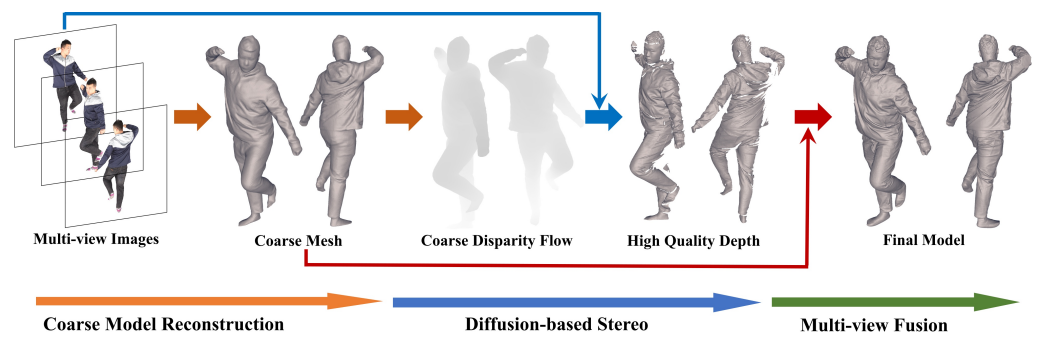
如上图所示,DiffuStereo 由一个现成的人体表面重建模型 DoubleField,一个 diffusion-based stereo 网络和一个轻量的多视角融合模块构成。该模型通过三个关键步骤从稀疏相机重建高质量的人体模型。
使用 DoubleField 预测初始的人体网格模型,之后被渲染为粗的视差图(disparity flow)。DoubelField 是目前 SOTA 的人体重建算法之一,它结合了表面场和辐射场,提供了一个好的初始化模型。
对于两个相邻的视角,diffusion-based stereo 会细化粗的视差图 来得到高质量的深度图。Diffusion-based stereo 网络通过连续的视差细化来提升每个视角的视差图。
最初的人体模型与高质量的深度图被拼接在一起得到高质量的人体网格模型。一个轻量的多视角融合模块在初始的人体模型的基础上利用精细的部分深度图对模型进行细化。
网格模型、深度、视差初始化
基于一组 个视角的图像 ,使用 DoubleField 预测一个初始的网格模型 ,并渲染成 个视角的粗的深度图 。将深度图转换为视差图,用于立体匹配。设 和 是两个相邻视角的索引。为了得到从视角 到视角 的 视差图 ,基于视角 的深度图 ,计算每个位置 像素的视差图:
其中, 将点从深度图 坐标系转换为世界坐标系, 则将点从世界坐标系重投影到图像坐标系。
初始的视差图将通过 Diffusion-based Stereo 来重建出高质量的多视角深度图。
用于视差图细化的Diffusion-based Stereo
现有的 stereo 方法利用 3D/4D 代价体积来离散地预测视差图,这对于实现亚像素精度的视差流图(disparity flow)估计非常困难。为了解决这个限制,diffusion-based stereo 可以在迭代中学得连续的流,它包括了一个前向与反向过程来获得高质量的视差图。在前向过程,初始视差图被噪声扩散(diffuse),在反向过程,高质量的视差图将从有噪声的图中被恢复。作者将基础的 diffusion model 与基于学习的迭代视差匹配相结合,并提出了一个多层网络结构来解决高分辨率输入的内存问题。
通用 Diffusion Model
一个标准的 步 diffusion model 包含一个前向和反向过程。前向过程在每一步 将高斯噪声加在原本的输入 上,由此输入会在 步后转换为纯噪声 。而反向过程则是从 中迭代地恢复 ,可以被视为去噪。具体地,扩散模型可以被写为两个马尔可夫链:
其中 是前向过程, 是 diffusion 核表征加噪声的方式, 是正态分布, 是单位矩阵, 是反向函数,利用去噪网络 来对 进行去噪, 则是额外的条件。当 ,前向和反向过程可以被视为连续过程或者随机可微等式,是一个很自然的连续流预测的形式,可以在人体配准任务中生成连续的流。
相较于基础的 diffusion model,在本任务中,作者做了两个改动:
基于 stereo flow 预测任务不是纯生成任务,提出了一个新的 diffusion kernel; Stereo 相关的特征与监督参与在反向过程中来确保颜色一致性与极线的限制。
视差图前向过程
在 diffusion-based stereo 中,前向过程之间将图像的分布从视差图转变为噪声分布。具体地,diffusion model 的输入 是真实视差图 与粗视差图 的残差 ,。不同于原模型利用 逐步减少 的尺寸,本工作提出了一个保留 尺寸并线性的将 偏移到 的 diffusion kernel:
其中 是用来缩放噪声的参数,基于这个新的 diffusion kernel,前向过程利用公式(2)和公式(5)视差图逐渐的将噪声加载真实的残差视差 上。
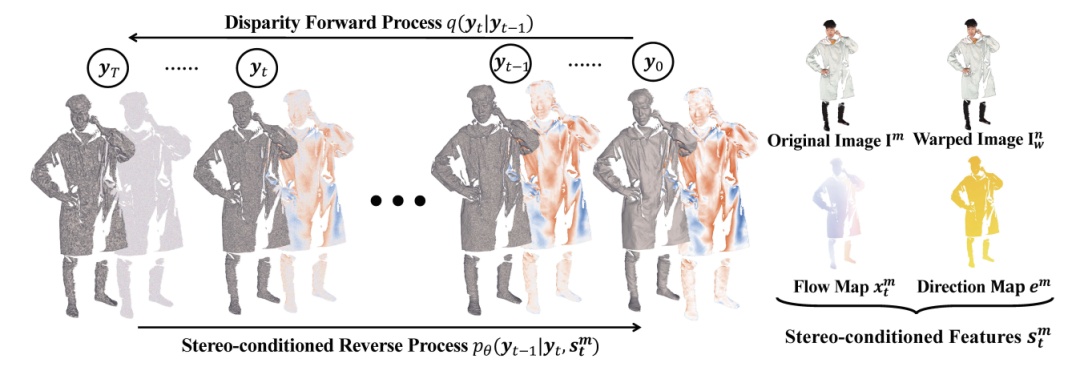
立体匹配调节的反向过程
反向过程基于公式(4)从噪声图 恢复残差视差图 。在这个步骤中,一个 diffusion stereo 网络作为去噪网络 ,通过接受 和 作为输入,并预测 。
由于diffusion kernel 同样影响反向过程,基于公式(5),反向过程中的每一步可以写为:
其中 , 是去噪网络的预测过程。将预测的 带入后验分布 中来表示 的均值:
由此,整个反向过程可以写为:
同时,该网络会接受额外的条件作为输入来预测高质量的时差图。如下图,四种 stereo 相关的输入将作为公式(4)中额外的条件 来确保每一步反向中的颜色一致性与极线约束:
视角 的图像 视角 warp 后的图像 ,是通过利用现有的视差 来变换 中的像素所得:
当前的视差图 极线的方向图:
其中 是基于粗深度图 与固定偏移角 计算得到:
在上述条件中,, 促进网络关注色彩一致性,, 提供视差流运动特征。通过将四种图进行拼接 ,进一步与拼接送入网络。该模型限制输出图 只保留单通道,预测的残差流 被限制在极线方向上移动。
当反向过程完成,最终的流将会基于公式(1)的逆向公式重新转换为视角 的细化的深度图 。
多层级网络结构
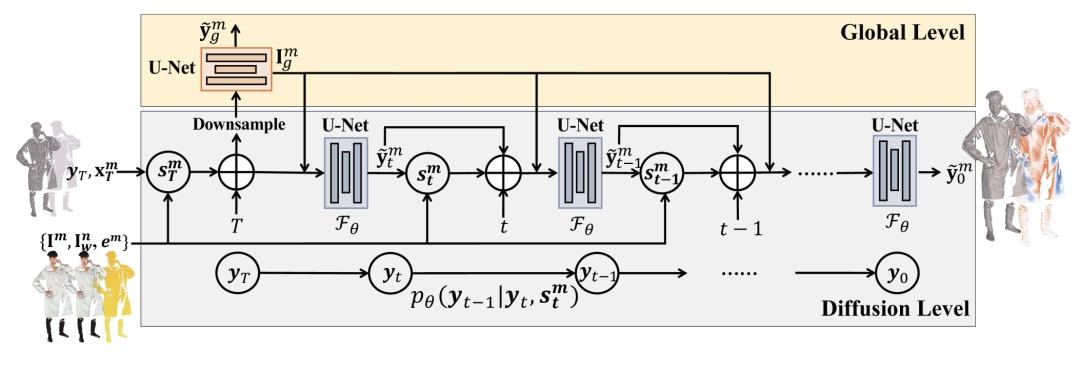
高质量的人体表面重建必须采用高分辨率的输入图像,但会导致内存不足的问题。作者提出了多层级的网络结构,一个全局网络 与 diffusion stereo 网络 结合。由此以来, 和 可以在 diffusion 层级与全局层级分别生成视差流。由上图所示,在全局层级,粗的初始流 与 stereo 特征 被降采样到 ,之后送入全局网络,直接预测低分辨率的残差流,这个全局层级的预测学到了包含全局人体语义信息,而在 diffusion 层级,作者使用全局网络中最后的图像特征 作为额外的条件送入网络,扩充stereo相关的特征到 。这种多层级的设计可以极大的克服内存限制,由此设计 diffusion stereo 可以基于块(patch-based)的方式进行训练。全局特征的也引导网络关注恢复精细的特征。
Diffusion-based Stereo 训练
全局层级:降采样真实残差流到 512 分辨率,用全局损失 训练全局网络 :
该损失函数鼓励网络学习用于流预测的人体语义信息。
Diffusion层级:随机取时间步骤 ,从 真实的残差流扩散到 ,使用下式:
之后使用 diffusion loss 来训练在 时刻的 diffusion stereo 网络 :
轻量多视角融合模块
基于多视角的预测结果,作者提出了一个多视角混合融合模块来融合精细深度图 和粗人体模型 来重建最终的模型。在融合前,使用 erosion kernel 去除深度边界,之后将每个精细深度图 转换为点云 。使用非刚性 ICP 配准对深度点云 和粗人体模型的点云 进行配准,粗点云作为锚定的模型来进行后续的配准。在配准过程中,优化目标为 由数据分量 和平滑分量 构成
其中 是深度点云 的偏移量, 是点云的邻点集。
优化后,最终的点云 是优化后的深度点云 和粗点云的 的集合,并可以通过柏松重建得到最终的人体表面模型。
实验
作者在 THUman2.0 上选取 300个模型进行评估,渲染了人的 4K 图与深度图。
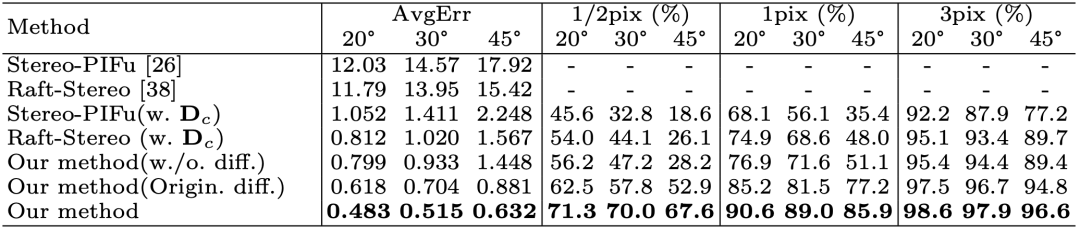
在立体匹配上,作者选取了4对视角进行立体匹配。以平均像素差一集三个等级的像素差比例作为指标。由上表,DiffuStereo 显著地超过了其他两种方法。在亚像素精度(1/2 pix)下,本方法的性能下降小于其他方法,证明了该方法可实现亚像素精度的匹配。同时,该方法在稀疏视角下单效果也明显优于其他方法。作者对比了是否引入 diffusion model,以及不同diffusion model 的设计下的匹配精度,证明了 diffusion model 可以有效提高配准效果。
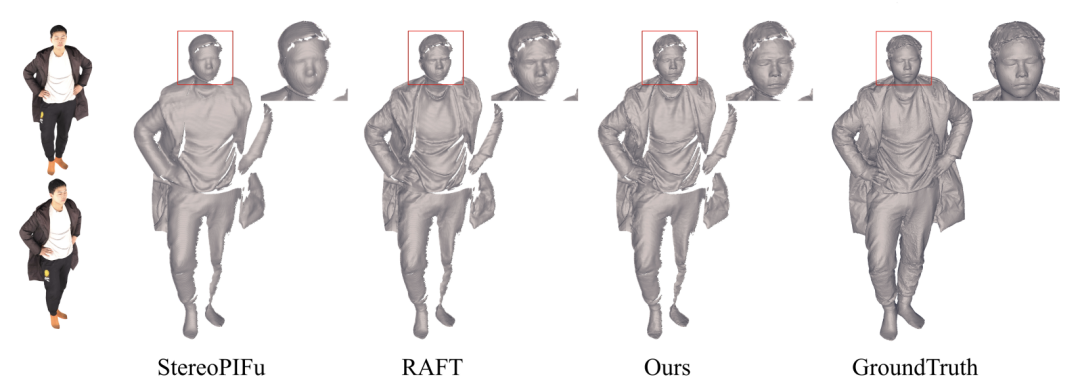
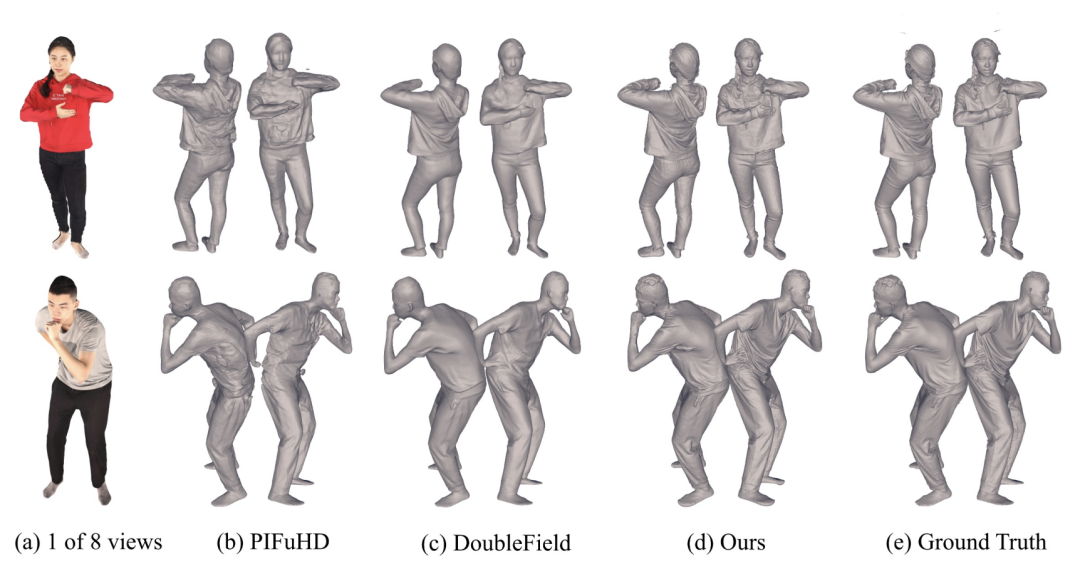
在人体重建上,作者对比了重建结果与真实结果的倒角距离差(Chamfer distance)和点到表面距离(P2S),下表证明该方法显著地提升了人体重建的精细度。下图的可视化的结果也显示出 DiffuStereo在衣物细节的精度显著好于其他 SOTA 方法。

总结
本文创新地将 diffusion model 与人体网格重建结合起来。通过基于初始的深度图,生成出生视差图,进而利用 diffusion model 强大的生成能力,得到亚像素精度的视差图,并转换为高精度的深度点云,并利用多目点云信息重建精确的三维人体表面,实现了在合理的内存占用下从稀疏高分辨率的图像重建精确的人体模型。