
Karmada 如何跨集群实现完整的自定义资源分发能力?
共 13288字,需浏览 27分钟
· 2022-11-24
❝本文转自徐信钊的博客,原文:https://xinzhao.me/posts/guide-to-karmada-resource-interpreter-webhook/,版权归原作者所有。欢迎投稿,投稿请添加微信好友:cloud-native-yang
Karmada 介绍
在开始讲 Resource Interpreter Webhook 之前需要对 Karmada 的基础架构以及如何分发应用等有一定的了解,但那一部分在之前的博客中已经提到过了,所以这篇文章就不再赘述了,如果需要的话可以移步到 Kubernetes 多集群项目介绍[1]了解。
一个例子:创建一个 nginx 应用
让我们先从一个最简单的例子开始,在 Karmada 中创建并分发一个 nginx 应用;首先是准备 nginx 的资源模板,这个就是原生的 K8s Deployment,不需要任何改变:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
再准备一个 PropagationPolicy,用来控制 nginx 分发到哪些集群:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- member1
- member2
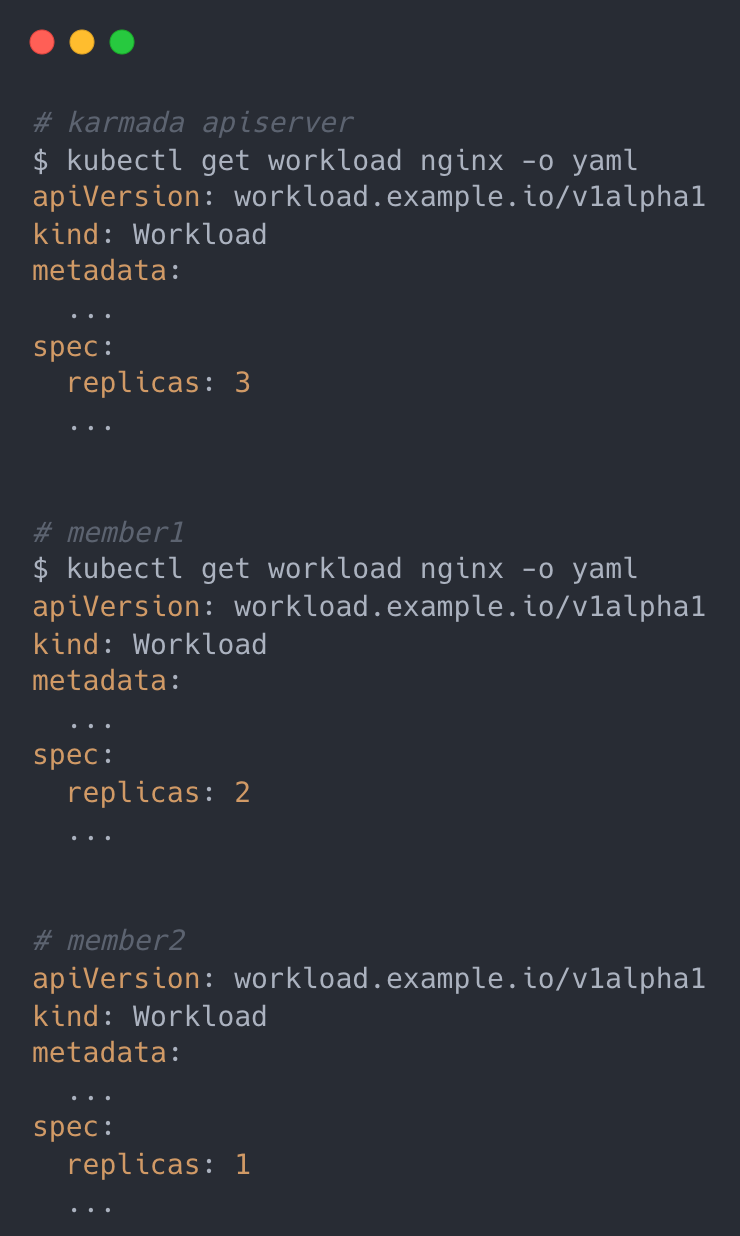
这里我们就直接将它分发到 member1 和 member2 集群。
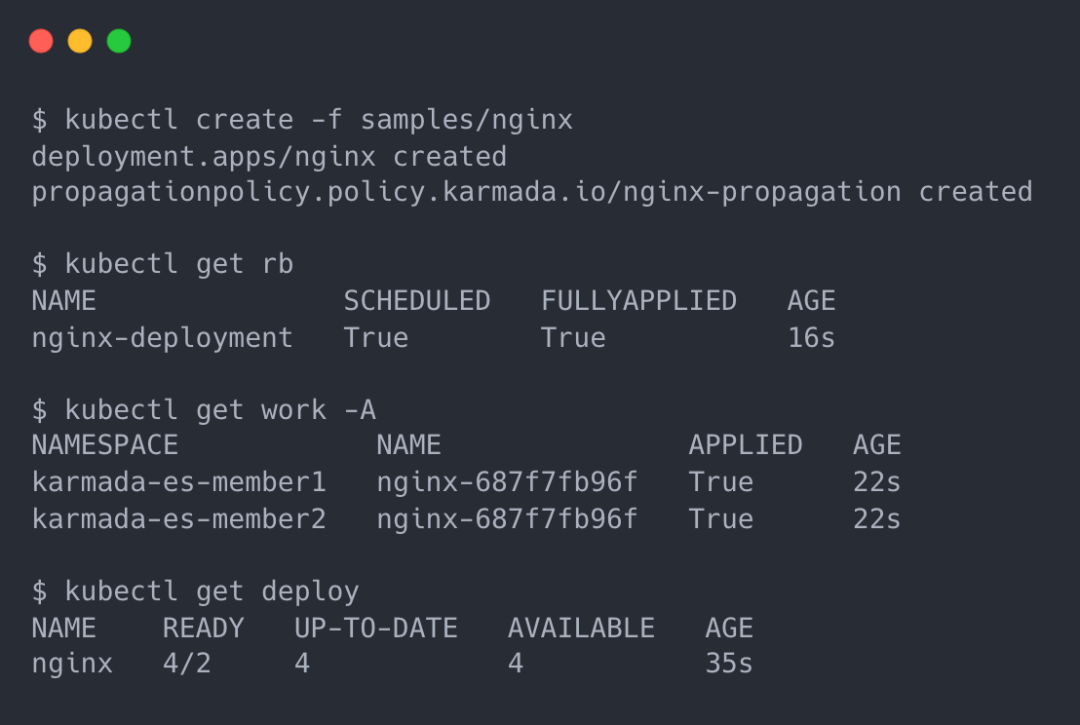
member1 和 member2 集群分别有一个副本数为 2 的 nginx Deployment,所以该资源一共存在 4 个 Pod。
上面的例子非常简单,直接在 member 集群根据模板原封不动创建 Deployment 就行了,但是大家知道 Karmada 是支持一些更高级的副本数调度策略的,比如下面这个例子:
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- member1
weight: 1
- targetCluster:
clusterNames:
- member2
weight: 1
应用了该规则之后,会涉及到针对每个集群上资源副本数的动态调整,之后 Karmada 在 member 集群创建 Deployment 的时候就需要增加一个修改副本数的步骤。
针对 Deployment 这类 K8s 核心资源,因为其结构是确定的,我们可以直接编写修改其副本数的代码,但是如果我有一个功能类似 Deployment 的 CRD 呢?我也需要副本数调度,Karmada 能正确地修改它的副本数吗?答案是否定的,也正因此,Karmada 引入了一个新的特性来使其能深度支持自定义资源(CRD)。
Resource Interpreter Webhook
为了解决上面提到的问题,Karmada 引入了 Resource Interpreter Webhook,通过干预从 ResourceTemplate 到 ResourceBinding 到 Work 到 Resource 的这几个阶段来实现完整的自定义资源分发能力:
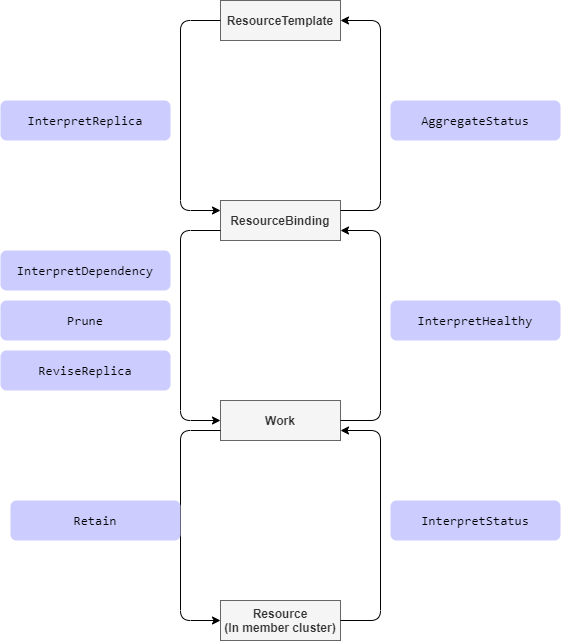
从一个阶段到另一个都会经过我们预定义的一个或多个接口,我们会在这些步骤中实现修改副本数等操作;用户需要增加一个单独的实现了对应接口的 webhook server,Karmada 会在执行到相应步骤时通过配置去调用该 server 来完成操作。
下面我们将选四个具有代表性的 hook 点来逐一介绍,接下来都使用以下 CRD 作为示例:
// Workload is a simple Deployment.
type Workload struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
// Spec represents the specification of the desired behavior.
// +required
Spec WorkloadSpec `json:"spec"`
// Status represents most recently observed status of the Workload.
// +optional
Status WorkloadStatus `json:"status,omitempty"`
}
// WorkloadSpec is the specification of the desired behavior of the Workload.
type WorkloadSpec struct {
// Number of desired pods. This is a pointer to distinguish between explicit
// zero and not specified. Defaults to 1.
// +optional
Replicas *int32 `json:"replicas,omitempty"`
// Template describes the pods that will be created.
Template corev1.PodTemplateSpec `json:"template" protobuf:"bytes,3,opt,name=template"`
// Paused indicates that the deployment is paused.
// Note: both user and controllers might set this field.
// +optional
Paused bool `json:"paused,omitempty"`
}
// WorkloadStatus represents most recently observed status of the Workload.
type WorkloadStatus struct {
// ReadyReplicas represents the total number of ready pods targeted by this Workload.
// +optional
ReadyReplicas int32 `json:"readyReplicas,omitempty"`
}
它和 Deployment 很像,我们用来演示 Karmada 如何支持这类资源来进行副本数调度等高级特性。
InterpretReplica
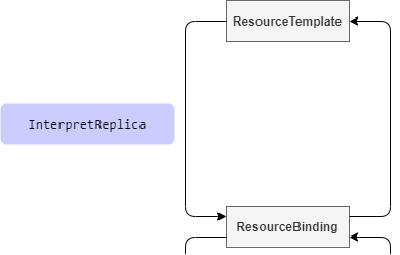
该 hook 点发生在从 ResourceTemplate 到 ResourceBinding 这个过程中,针对有 replica 功能的资源对象,比如类似 Deployment 的自定义资源,实现该接口来告诉 Karmada 对应资源的副本数。
apiVersion: workload.example.io/v1alpha1
kind: Workload
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
针对我们示例的 Workload 资源,实现方式也非常简单,直接在 webhook server 中返回副本数的值即可:
func (e *workloadInterpreter) responseWithExploreReplica(workload *workloadv1alpha1.Workload) interpreter.Response {
res := interpreter.Succeeded("")
res.Replicas = workload.Spec.Replicas
return res
}
❝注:所有的示例均来自 Karmada 官方文档,可以通过文章最后的 参考链接[2] 来查看完整的示例和代码。
ReviseReplica
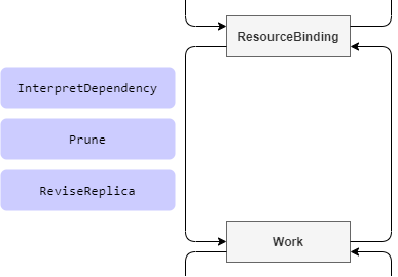
该 hook 点发生在从 ResourceBinding 到 Work 这个过程中,针对有 replica 功能的资源对象,需要按照 Karmada 发送的 request 来修改对象的副本数。Karmada 会通过调度策略把每个集群需要的副本数计算好,你需要做的只是把最后计算好的值赋给你的 CR 对象(因为 Karmada 并不知道该 CRD 的结构):
func (e *workloadInterpreter) responseWithExploreReviseReplica(workload *workloadv1alpha1.Workload, req interpreter.Request) interpreter.Response {
wantedWorkload := workload.DeepCopy()
wantedWorkload.Spec.Replicas = req.DesiredReplicas
marshaledBytes, err := json.Marshal(wantedWorkload)
if err != nil {
return interpreter.Errored(http.StatusInternalServerError, err)
}
return interpreter.PatchResponseFromRaw(req.Object.Raw, marshaledBytes)
}
核心代码也只有赋值那一行。
Workload 实现副本数调度
回到我们最初的那个问题,在了解了 InterpretReplica 和 ReviseReplica 两个 hook 点之后,就能够实现自定义资源按副本数调度了,实现 InterpretReplica hook 点以告知 Karmada 该资源的副本总数,实现 ReviseReplica hook 点来修改对象的副本数,再配置一个 PropagationPolicy 就可以了,配置方法和 Deployment 等资源一样:
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-workload-propagation
spec:
resourceSelectors:
- apiVersion: workload.example.io/v1alpha1
kind: Workload
name: nginx
placement:
clusterAffinity:
clusterNames:
- member1
- member2
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- member1
weight: 2
- targetCluster:
clusterNames:
- member2
weight: 1
效果如下:
Retain
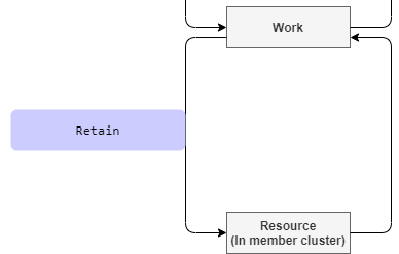
该 hook 点发生在从 Work 到 Resource 这个过程中,针对 spec 内容会在 member 集群单独更新的情况,可以通过该 hook 告知 Karmada 保留某些字段的内容。
apiVersion: workload.example.io/v1alpha1
kind: Workload
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 3
paused: false
以 paused 为例,该字段的功能是暂停 workload,member 集群的 controller 会单独更新该字段,Retain hook 就是为了能更好地和 member 集群的 controller 协作,可以通过该 hook 来告知 Karmada 哪些字段是需要不用更新、需要保留的。
func (e *workloadInterpreter) responseWithExploreRetaining(desiredWorkload *workloadv1alpha1.Workload, req interpreter.Request) interpreter.Response {
if req.ObservedObject == nil {
err := fmt.Errorf("nil observedObject in exploreReview with operation type: %s", req.Operation)
return interpreter.Errored(http.StatusBadRequest, err)
}
observerWorkload := &workloadv1alpha1.Workload{}
err := e.decoder.DecodeRaw(*req.ObservedObject, observerWorkload)
if err != nil {
return interpreter.Errored(http.StatusBadRequest, err)
}
// Suppose we want to retain the `.spec.paused` field of the actual observed workload object in member cluster,
// and prevent from being overwritten by karmada controller-plane.
wantedWorkload := desiredWorkload.DeepCopy()
wantedWorkload.Spec.Paused = observerWorkload.Spec.Paused
marshaledBytes, err := json.Marshal(wantedWorkload)
if err != nil {
return interpreter.Errored(http.StatusInternalServerError, err)
}
return interpreter.PatchResponseFromRaw(req.Object.Raw, marshaledBytes)
}
核心代码只有一行,更新 wantedWorkload 的 Paused 字段为之前版本的内容。
AggregateStatus
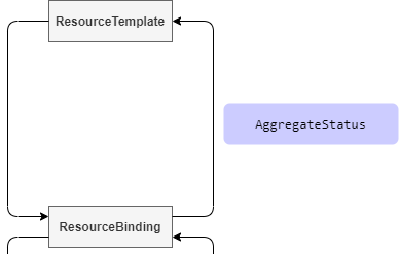
该 hook 点发生在从 ResourceBinding 到 ResourceTemplate 这个过程中,针对需要将 status 信息聚合到 Resource Template 的资源类型,可通过实现该接口来更新 Resource Template 的 status 信息。
Karmada 会将各个集群 Resouce 的状态信息统一收集到 ResourceBinding 中:
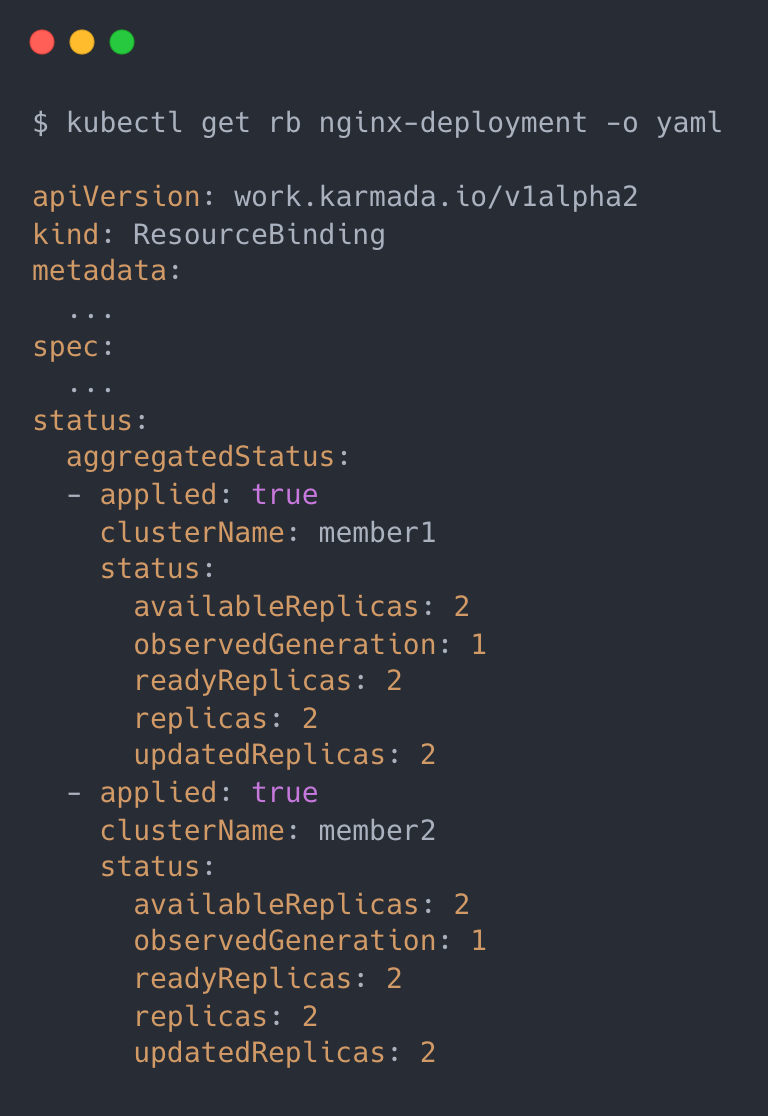
AggregateStatus hook 需要做的事情就是将 ResourceBinding 中 status 信息更新到 Resource Template 中:
func (e *workloadInterpreter) responseWithExploreAggregateStatus(workload *workloadv1alpha1.Workload, req interpreter.Request) interpreter.Response {
wantedWorkload := workload.DeepCopy()
var readyReplicas int32
for _, item := range req.AggregatedStatus {
if item.Status == nil {
continue
}
status := &workloadv1alpha1.WorkloadStatus{}
if err := json.Unmarshal(item.Status.Raw, status); err != nil {
return interpreter.Errored(http.StatusInternalServerError, err)
}
readyReplicas += status.ReadyReplicas
}
wantedWorkload.Status.ReadyReplicas = readyReplicas
marshaledBytes, err := json.Marshal(wantedWorkload)
if err != nil {
return interpreter.Errored(http.StatusInternalServerError, err)
}
return interpreter.PatchResponseFromRaw(req.Object.Raw, marshaledBytes)
}
逻辑也非常简单,根据 ResourceBinding 中的 status 信息来计算(聚合)出该资源总的 status 信息再更新到 Resource Template 中;效果和 Deployment 类似,可以直接查询到该资源在所有集群汇总后的状态信息:
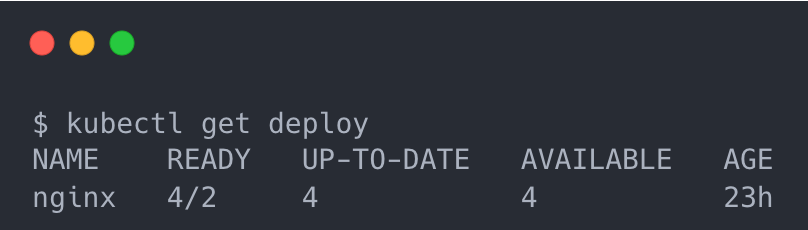
参考链接
Resource Interpreter Webhook[3] custom resource interpreter example[4]
引用链接
Kubernetes 多集群项目介绍: https://xinzhao.me/posts/kubernetes-multi-cluster-projects/#karmada
[2]参考链接: https://xinzhao.me/posts/guide-to-karmada-resource-interpreter-webhook/#参考链接
[3]Resource Interpreter Webhook: https://github.com/karmada-io/karmada/tree/master/docs/proposals/resource-interpreter-webhook
[4]custom resource interpreter example: https://github.com/karmada-io/karmada/tree/master/examples#resource-interpreter


你可能还喜欢
点击下方图片即可阅读
2022-11-16

2022-11-14

2022-11-11

2022-11-09


云原生是一种信仰 🤘


点击 "阅读原文" 获取更好的阅读体验!
发现朋友圈变“安静”了吗?
