 大邓和他的Python
大邓和他的Python





乱码由来
相信大家使用Python读取txt、csv文件时,经常遇到UnicodeDecodeError错误,从字面意思看是 编码解码问题 。 关于编码解码相关知识推荐看B站柴知道制作的视频,了解
锟斤拷�⊠是怎样炼成的------中文显示"⼊"门指南【柴知道】
遇到乱码
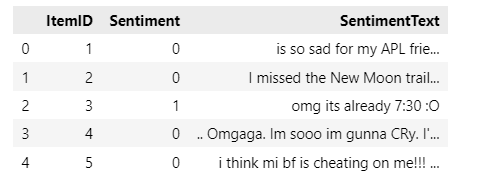
在Python中,遇到文件读取乱码的可能性很大,例如
import pandas as pd
df = pd.read_csv('twitter_sentiment.csv')
df.head()
Run
c:\users\thunderhit\appdata\local\programs\python\python37-32\lib\site-packages\pandas\io\parsers.py in parser_f(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, dialect, error_bad_lines, warn_bad_lines, delim_whitespace, low_memory, memory_map, float_precision)
...
pandas\_libs\parsers.pyx in pandas._libs.parsers.TextReader._tokenize_rows()
pandas\_libs\parsers.pyx in pandas._libs.parsers.raise_parser_error()
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbd in position 10717: illegal multibyte sequence
可以看到报错, 遇到 UnicodeDecodeError 问题
使用encoding参数
常见的解决办法是在函数内加入encoding参数,中文最常见的编码方式有gbk、gb2312、utf-8。
import pandas as pd
#这里依次试验gbk、gb2312、utf-8
df = pd.read_csv('twitter_sentiment.csv', encoding='utf-8')
df.head()
依然出现 UnicodeDecodeError 问题 。所以encoding遇到很不常见的编码方式。
获取encoding参数
先获取 twitter_sentiment.csv 文件的编码方式,再进行读取操作。
import chardet
#读取为二进制数据
binary_data = open('twitter_sentiment.csv', 'rb').read()
#传给chardet.detect,稍等片刻
chardet.detect(binary_data)
Run
{'encoding': 'Windows-1252', 'confidence': 0.7291192008535122, 'language': ''}
由此得知该文件的编码方式为 Windows-1252 , 重新更改即可成功读入数据
成功读取
获取了正确的编码 encoding='Windows-1252', 就能正确的读入数据
import pandas as pd
#这里依次试验gbk、gb2312、utf-8
df = pd.read_csv('twitter_sentiment.csv', encoding='Windows-1252')
df.head()
Run
精选文章
27G数据集 | 使用Python对27G招股说明书进行文本分析
PNAS | 使用语义距离测量一个人的创新力(发散思维)得分
安装python包出现报错:Microsoft Visual 14.0 or greater is required. 怎么办?
R语言 | 使用posterdown包制作学术会议海报 R语言 | 使用ggsci包绘制sci风格图表
R语言 | 使用word2vec词向量模型
27G数据集 | 使用Python对27G招股说明书进行文本分析
PNAS | 使用语义距离测量一个人的创新力(发散思维)得分
安装python包出现报错:Microsoft Visual 14.0 or greater is required. 怎么办?
R语言 | 使用posterdown包制作学术会议海报 R语言 | 使用ggsci包绘制sci风格图表 R语言 | 使用word2vec词向量模型
R语言 | 将多个txt汇总到一个csv文件中
R语言 | 将多个txt汇总到一个csv文件中

