 大邓和他的Python
大邓和他的Python





在前面的文章中,我们介绍了文本可读性的计算方法,其核心思想在于计算文本的用词复杂度或者语言表达形式。
而在文本色彩计算上,如何计算文本的情感、如何从不同的维度挖掘文本中更为细节的信息,是个有趣的话题。
目前已经开放了许多情感词典,例如,台大NTUSD、知网HowNet、清华大学褒贬义词典、大连理工大学情感词汇本体库DUTIR等。
但在使用这些开放情感词的同时,关注下背后词库的构建过程,可能会有更多收获。
因此,本文我们来介绍多维度Valence-Arousal(VA)情感词典以及细粒度情感分类词典的建设,一起来谈谈情感分析在不同维度上、细粒度上的一些代表性工作。
一、多维度情感分类词库的建设解析
如何评估一个情感词,是件有趣的事,与我们所看到的情绪只有强度这一个维度的认知不同,情绪维度一般是多维的,包括极性(valence)、强度(arousal)以及可控性(dominance)。
1、Valence-Arousal(VA)空间
Aalence-Arousal(VA)空间是常见的一种情感维度空间,Valence代表愉快和不愉快(即积极和消极)的程度,而Arousal代表兴奋和平静的程度。
基于这种表示,任何情感状态都可以表示为VA坐标平面上的一个点。即该坐标平面内的每一个点都代表着一种情感状态。
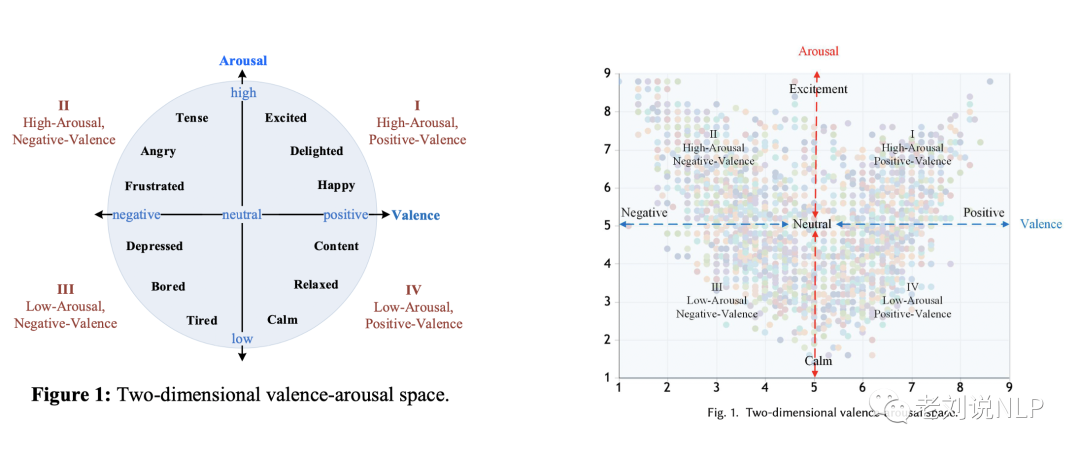
越来越多的研究集中在将情感状态表示为多维度上的连续值,最常见的多维度空间为Aalence-Arousal(VA)空间。
与之前的将情感状态分为几类(正面和反面)相比,维度方法可以提供更加细粒度的情感分析,目前针对这种数据的资源包括多种:
例如,
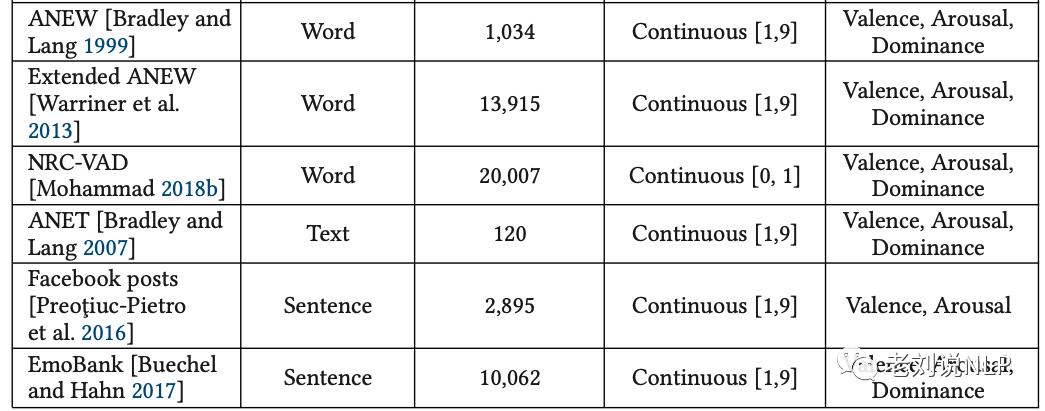
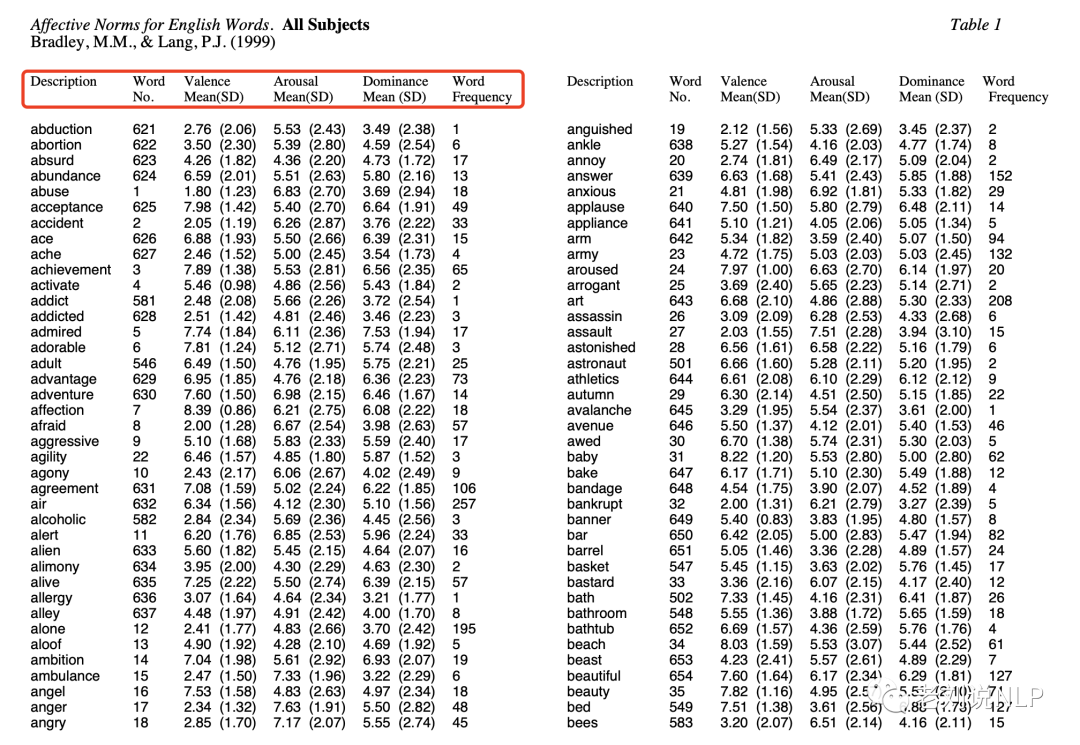
代表的,Norms for English Words (ANEW) 提供了1,034个标注VAD三个维度实值的情感词典。
2、ChineseEmoBank的构建方式解析
ChineseEmoBank,主要解决了面向中文的VA情感词典问题,改工作建立了可用于情感分析的中文VA词典(CVAW)和中文VA文本语料库(CVAT),以此来丰富VA维度下多语言的情感研究和开发。
下面介绍Lung-Hao Lee, Jian-Hong Li and Liang-Chih Yu, "Chinese EmoBank: Building Valence-Arousal Resources for Dimensional Sentiment Analysis," 的工作。
1)词典情况
ChineseEmoBank是一个维度的情感资源,在价值和唤醒两个维度上都标注了实值的分数,其中valence,代表积极和消极情绪的程度,arousal唤醒代表平静和兴奋的程度,这两个维度的范围从1(高度消极或平静)到9(高度积极或兴奋)。
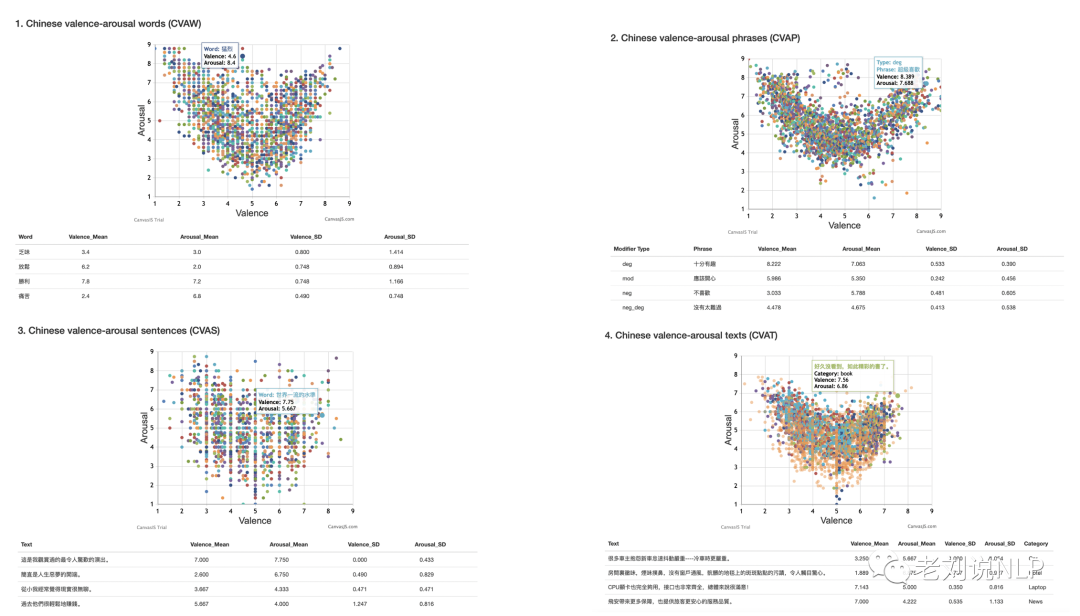
该库具有不同层次的文本颗粒度,包括两个词库,分别是中文情绪唤醒词(CVAW,5512个单字)和中文情绪唤醒短语(CVAP,2998个多字短语),以及两个语料库,分别是中文情绪唤醒句子(CVAS,2582个单句)和中文情绪唤醒文本(CVAT,2969个多句子文本)。
地址:http://nlp.innobic.yzu.edu.tw/resources/ChineseEmoBank.html
2)数据来源
CVAW(Chinese valence-arousal words) , 来自两个基于极性的情感词库,C-LiWC和NTUSD。
CVAP(Chinese valence-arousal phrases) 将CVAW中的情感词与一组修饰语,如否定词(如not)、程度副词(如very)和情态词(如should)结合起来,形成多词短语,然后从一个大型网络语料库中检索每个短语的频率。
此外,为了保证词库的准确性,CVAP保留频次大于3的词;
为了避免出现几个修饰语主导整个资源,每个修饰语(或修饰语组合)最多可以有50个短语;
为了最大限度地平衡正面和负面的词语,这有助于防止正面或负面的词语支配整个资源,例如,通过随机选择25个正面词和25个负面词来构成每个修饰语的50个短语来实现平衡。
最后,共有2,998个多词短语被选入CVAP。
CVAS(Chinese valence-arousal single-sentences) ,首先从社交网络服务Twitter上收集中文推文,选择那些包含在CVAW中发现的最多的情感词的推文,然后使用现有的标点符号将这些推文分成句子,总共有2,582个单句,不包括表情符号、URL和辱骂性语言。
CVAT(Chinese valence-arousal multi-sentence texts) ,从六个不同的类别中收集网络文本,即:新闻文章、政治讨论区、汽车讨论区、酒店评论、书评和笔记本评论。并将含有不完整语义和辱骂性语言的文本排除在外。最后,选择了2,969个包含在CVAW中发现的最多情感词的多句子文本进行标注。
2)构建方式
a. CVAW的建立
它是建立在C-LIWC的基础之上的,采用自我评定人体模型(SAVM),即经过培训的注释者们给每个单词一个在VA维度的值,同时SVA会给出一些图片来提高标注精确度,如下图中的面部表情以及心动的图解释。
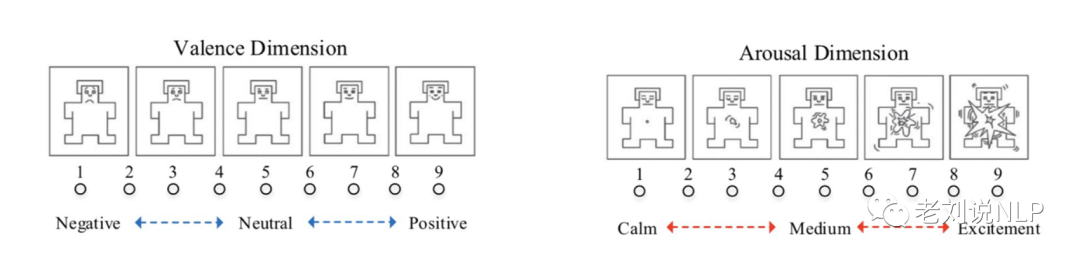

Valence和Arousal维度值的范围是1-9,效价和唤醒维度上的数值1分别表示极高的负面情绪和低唤醒情绪,而9表示极高的正面情绪和高唤醒情绪,5表示中性和中等唤醒情绪。
因为单词级别的评级相对于短语、句子和多句子级别更容易确定,用于CVAW的注释者数量分为5个,最后,将5个注释者所给的值得平均值作为该单词的VA值,从而就得到CVAW词典。
b. CVAT,CVAP、CVAS的建立
CVAT,CVAP、CVAS和CVAT的每个实例被随机分配给10个标注人员。
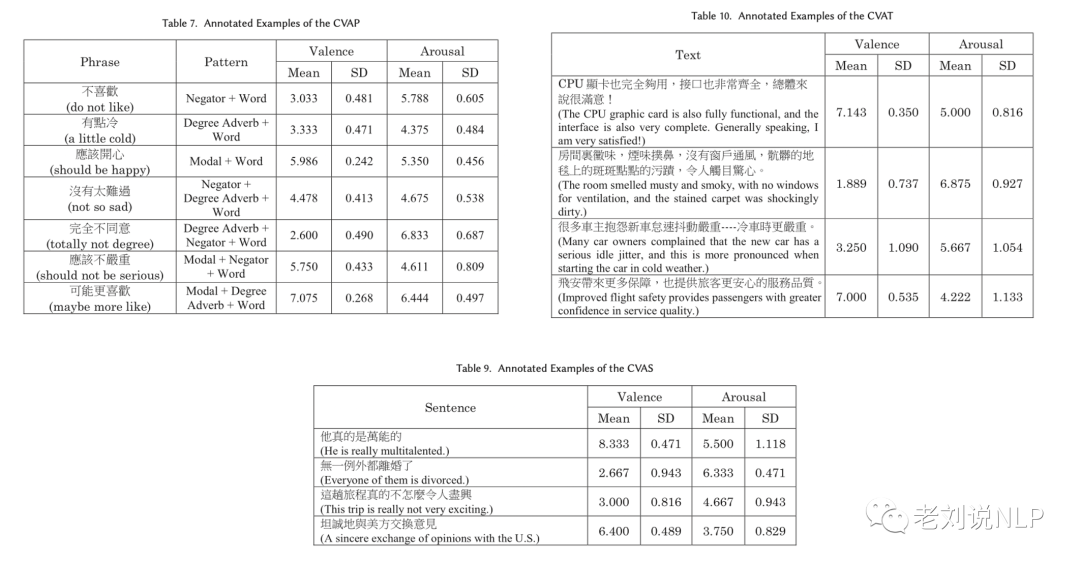
具体的,从6种不同类型的网络信息中选择处720条,总共包括2009个包括C-LIWC词典中出现次数最多的情感词的句子被选出来进行VA评定,评分结束后会执行一个语料库清楚程序来去除一些VA值异常(不在平均值左右1.5标准偏差的区间内的VA值)和不恰当的句子。
去除掉以后,这些句子将不再参加平均VA值得计算,句子的valence(或者arousal)等于句子中那些包含在CVAW词典章的词语的Valence(或arousal)值的平均值。
3)构建效果
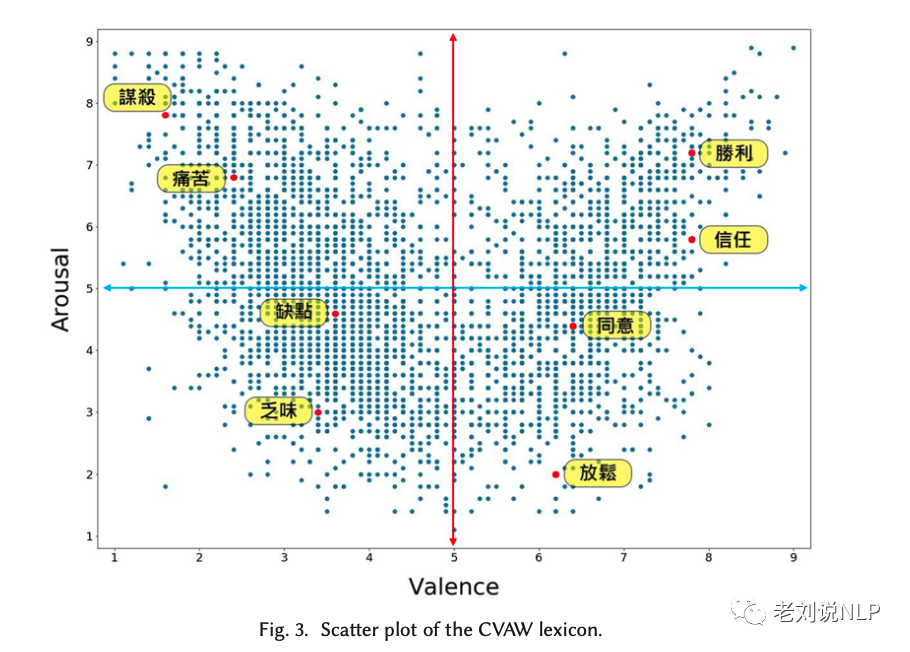
a.CVAW
下图显示了CVAW的散点图。它呈现出一个微笑曲线,表明高积极性和高消极性的词通常都有一个高的唤醒值。表4列出了VA平面的四个象限的几个例子词。
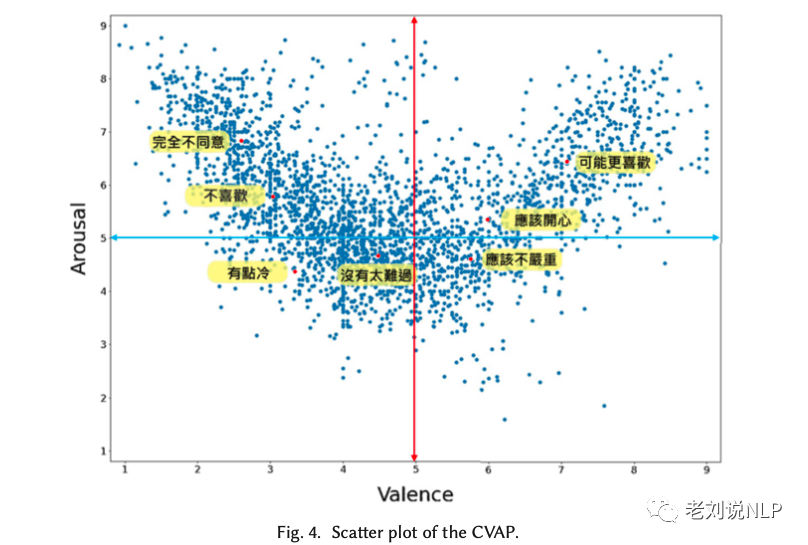
b.CVAP
对于CVAP,共有52个修饰词(包括4个否定词、42个程度副词和6个修饰词)与CVAW中的情感词相结合,形成多词组。

词组的方式分为多种:
2-word phrases:
Negator + Word
Degree Adverb + Word
Modal + Word
3-word phrases:
Negator + Degree Adverb + Word
Degree Adverb + Negator + Word
Modal + Negator + Word
Modal + Degree Adverb + Word
Degree Adverb + Modal + Word
形成的散点图如下:
b.CVAS和CVAT
下图分别显示了CVAS和CVAT中单一句子和多句子文本的散点图,两幅散点图都呈现出微笑曲线,这与CVAW和CVAP的情况一致。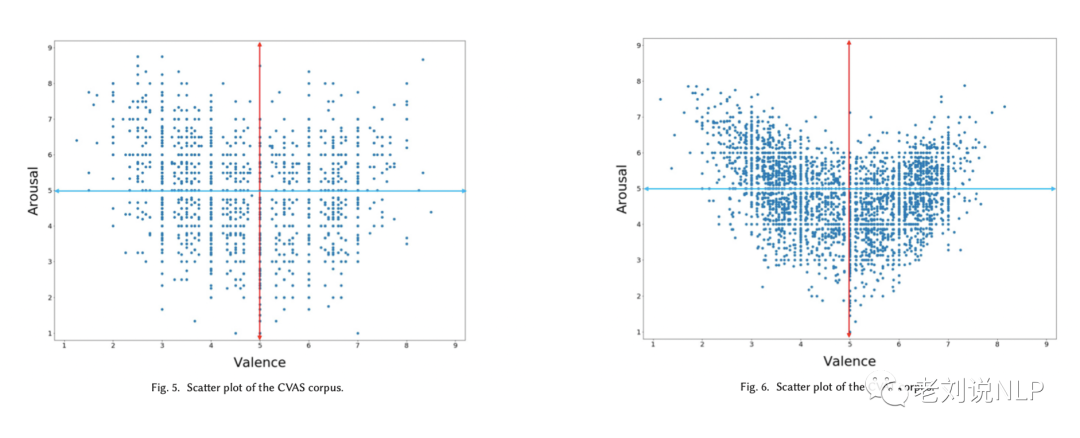
二、细粒度情感分类词库的建设解析
在聊完情感维度的强度评估问题后,我们来谈谈情感在类型分类上的工作,也就是定性方面。
实际上,到目前为止,心理学界对情感的划分还没有一个公认的标准。情感的分类有2、3、4、56乃至16余类不等,这主要是因为人类的情感复杂多变,并且人们对情感的认识还不够深入和全面导致的。
1、情感分类的维度
目前,对情感划分的研究仍在不断的进步和发展中,主要的情感分类方法有以下几种:
Ekman提出的6类:高兴,悲伤,愤怒,恐惧,厌恶和惊奇。
Plutchik在1960年提出的8种纯情感:快乐,悲伤,愤怒,恐惧,期望,惊奇,憎恨,接受。并认为其他复杂情感都是这些情感混合而成。
Yu zhang提出的12类:高兴,悲哀,恐惧,厌恶,愤怒,惊奇,喜爱,期待,焦虑,内疚,赞扬,羞。
Plutchik等提出的8大类情感:狂喜,警惕,悲痛,惊奇,狂怒,恐惧,接受,憎恨。
中国传统的“七情”大致分为:好,恶,乐,怒,哀,惧,欲。
心理学家林传鼎将情绪划分为54类:安静,喜悦,恨怒,悲痛,哀怜,忧愁,忿急,烦闷,恐惧,惊骇,恭敬,抚爱,憎恶,贪欲,嫉妒,骄慢,惭愧,耻辱。
许小颖等人将情感词汇划分为基于心理感受和基于表现力的2大类,其中将基于心理感受的词汇又细化为12类:喜,乐;爱;愁,闷;悲;慌;敬;激动;羞,疚;烦;急;傲;吃惊;怒;失望;安心;恨;嫉;蔑视;悔;委屈;谅;信;疑;其他。将基于表现力的词汇细化为态度词、品性词、声音词和其他。
仇德辉等人提出人的情感可分为对物情感、对人情感、对己情感以及对特殊事物的情感4大类,其中对特殊事物的情感又细分为对他人评价的情感、对交往活动的情感、对不确定事物的情感和对自身状态的情感4大类。
大连理工大学在参照这些分类体系的基础上,综合现有的情感词汇资源,本文将情感分为7大类、16小类,如下图所示
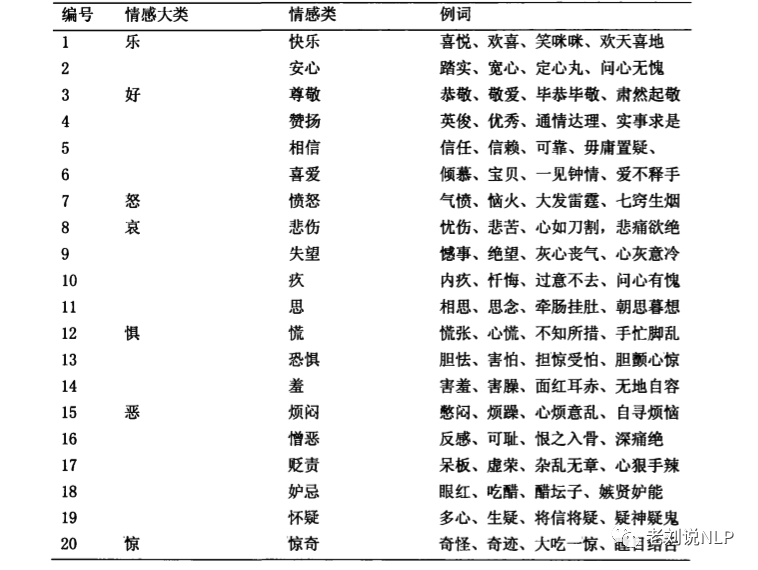
2、大连理工大学情感本体的构建方式
大连理工大学情感本体是目前具有代表性的情感本体,分析其构建方式有很强的指导性,下面对其工作进行介绍,主要来自于《陈建美.中文情感词汇本体的构建及其应用》一文。
地址:
1)基础数据来源
情感本体的基本知识主要来源于现有的一些词典、语义网络等。
其中词典包括《现代汉语分类词典》、《汉语褒贬义词语用法词典》、《汉语形容词用法词典》、《中华成语大词典》、《汉语熟语词典》、《新世纪汉语新词词典》,语义知识网络有知网和wordnet另外还加入了《汉语情感系统中情感划分的研究》中的部分词汇。
2)情感词的获取
情感词汇通过两级筛选得到,一级筛选是从各类资源中初步挑选可能与情感相关的词汇。
在一级筛选方法中,词典资源主要是利用词典中与情感相关的子类如心理、感觉、情感、性格、态度等类的词汇,但是也有一些词典没有相应的子类划分,需要整本都做人工的过滤。
例如:
知网中情感词汇的获取是先选择包含情感色彩的义原,主要有“情绪”、“态度”等几大类,然后从知网中选取包含这些义原的词汇。
WordNet是利用WordNet-Domain抽取初级的情感词汇,WordNet-Domain划分WordNet中的Synet,选择与psychlogy类型相关的Synet,然后根据它们与词汇的对应关系选择相应的词汇。
二级筛选是采用手工分类的方法,人工从一级筛选的词汇中选择有情感色彩的词汇,并划分情感类别,即指出词汇包含哪几种情感。
3)情感强度的获取
在情感强度的获取上,先为每种情感类别的每个强度等级确定一定量的标准词汇,然后通过在大规模的语料库中查找待定词汇和标准词汇的互信息,从而将待定词汇的强度确定为与之互信息最高的标准词汇的强度,然后再对不合理的进行人工调整。
点互信息PMI的计算公式如下:
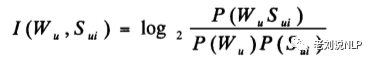
其中:其中Wu表示包含u类情感的词汇,Sui表示u类情感的第i个标准词。计算W与所有u类情感的标准词汇之间的互信息,选择互信息最大的那个标准词的强度作为词汇W在u类情感上的强度。
另外,语料是从网上下载的与情感相关的文章,从风格上看包括寓言、散文、戏剧、小说、杂文、新闻等多种文体,从时间和空间上涉及国内和国外不同时代的多个作家(去噪后大约150MB),以解决语料数量较少或涉及词汇的范围较窄情况下,可能导致的数据稀疏的问题,不能正确反映词汇的强度。
总结
本文主要介绍了多维度Aalence-Arousal(VA)情感分类词典以及细粒度情感分类词典的建设工作,情感分析在不同维度上、细粒度上的一些代表性工作。
从中可以观看出,情感分析相关词典的构造,包括强度的设计标准,很大程度上都需要使用到人工,用人工设定标准词或者进行众包标注,以确定最终结果,但后续也出现了不少基于统计,如sopmi以及CRF方法的情感词扩充方案。
最后,感谢以上相关贡献的工作,期待有更多好的资源出现。
参考文献
1、Lung-Hao Lee, Jian-Hong Li and Liang-Chih Yu, "Chinese EmoBank: Building Valence-Arousal Resources for Dimensional Sentiment Analysis," ACM Trans. Asian and Low-Resource Language Information Processing, vol. 21, no. 4, article 65, 2022.
2、Liang-Chih Yu, Lung-Hao Lee, Shuai Hao, Jin Wang, Yunchao He, Jun Hu, K. Robert Lai, and Xuejie Zhang. 2016. "Building Chinese affective resources in valence-arousal dimensions. In Proceedings of NAACL/HLT-16, pages 540-545.
3、陈建美. 中文情感词汇本体的构建及其应用[D].大连理工大学,2009.
4、Bradley,M.M.&P.J.Lang.1999.Affective Norms for English Words(ANEW):Instruction Manual andAffective Ratings[M].Technical Report C-1.
关于我们
精选文章
27G数据集 | 使用Python对27G招股说明书进行文本分析
PNAS | 使用语义距离测量一个人的创新力(发散思维)得分
FinBERT | 金融文本BERT模型,可情感分析、识别ESG和FLS类型
安装python包出现报错:Microsoft Visual 14.0 or greater is required. 怎么办?
R语言 | 使用posterdown包制作学术会议海报 R语言 | 使用ggsci包绘制sci风格图表 R语言 | 使用word2vec词向量模型
R语言 | 将多个txt汇总到一个csv文件中


