
巧用 HTTP 协议,设计一个基 于B/S 架构的缓存框架!
共 8206字,需浏览 17分钟
· 2022-11-22

阅读本文大概需要 11 分钟。
来自:https://blog.csdn.net/qq_34347620/article/details/127762617
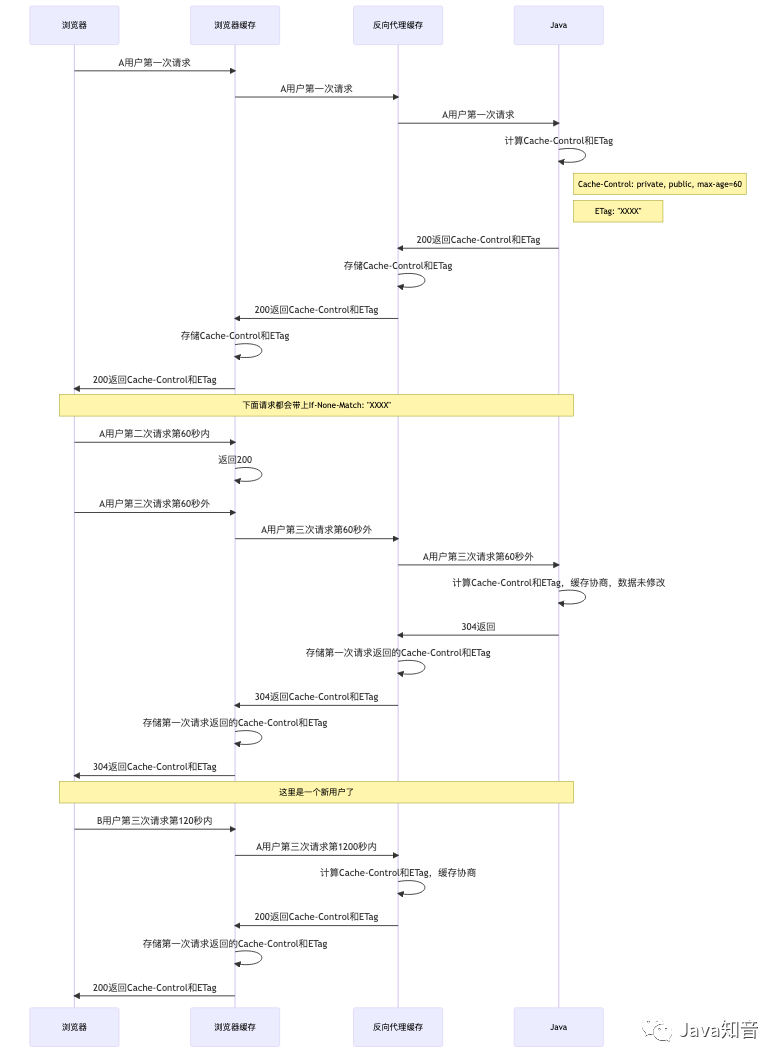
1. 基于B/S架构的HTTP协议三级缓存设计
1.1. 骚话连篇
时间问题和空间问题,但是现在本质已经变了现在的软件工程师已经不在乎软件质量以及代码质量,以增加系统复杂度的来解决并发问题,软件变成变成了PPT编程。1.2. 设计初衷
读流量,写流量甚至都达不到5%,Java工程师引用Redis将大量数据放入Redis来解决读流量其实是错误甚至是致命的,在重后端轻前端的软件开发环境下大家都是优先从后端入手去解决读流量很少从网络传输协议入手去解决问题。运维工程师对于HTT议缓存也仅仅是Nginx对静态资源设置一个Cache-Control: max-age=31536000。1.3. 解决思路
Cache-Control: max-age=31536000),后端来决定HTTP缓存的时间,其中涉及到 HTTP协议缓存失效机制、反向代理缓存、后端缓存控制。https://developer.mozilla.org/en-US/docs/Web/HTTP/Caching
https://web.dev/i18n/en/http-cache/
手撕框架说吧2. 短小精悍
说一个微服务小故事 卧槽!Nginx崩了。卧槽!系统崩了。领导:在这样子搞下去不行呀,脸上挂不住呀,把系统拆成微服务吧,整点高大上的东西进去应该就不会崩溃了吧 一个系统拆成微服务中。改造中... 注册中心来一发,PRC来一发,gateway来一发。。。卧槽!系统还是老样子崩溃了。 运维仔憋出大招喊出了:Nginx双活来一发,Spring Cloud Gateway集群搞起来,给我活,活起来。。。运维仔:卧槽!版本升级好麻烦呀,来一发docker顺带一发k8s。后端仔:卧槽!配置不能同步呀,来一发配置中心吧。后端仔:卧槽!这个接口涉及到多个服务,来一发seata吧。后端仔:卧槽!!!出bug了看日志好麻烦呀 整一发ELK吧。 客户:卧槽!!!升级微服务了好牛逼plus呀。卧槽!!!微服务化了稳定上上来了,这性能怎么这么拉胯呀。后端仔:我给你来一发zipkin做性能追踪看看。
2.1. 网关之短
Spring Cloud Gateway作为业务网关,经过两层网关之后性能网络延迟会增加5%-10%,这些损耗还没有加上一些人会往Spring Cloud Gateway之中增加一些奇特的功能(报文校验,报文加解密,token校验。。),以至于Spring Cloud Gateway的性能下降的更厉害以至于要扩充Spring Cloud Gateway集群。Spring Cloud Gateway还需要Nginx嘛,虽然Java的性能比不上C但是也没有必要用多层网关设计吧。就算上了LB,阿里云那边其实也是一台Nginx在哪里跑着,进阶版本和集群版本其实没有多大差别。Spring Cloud Gateway的性能比不上Nginx,Java天生劣势,但是Nginx又没有微服务生态,经过一段时间的苦思冥想后已经询问众多好友后,给我了一个OpenResty让我去玩,但是OpenResty并没有接入Spring Cloud Alibaba体系之中,而且OpenResty需要写Lua,我不会Lua呀,最终22年的时候在和朋友瞎扯淡后拿到了 Apache APISIX。https://apisix.apache.org/docs/apisix/getting-started/
https://baijiahao.baidu.com/s?id=1673615010327758104&wfr=spider&for=pc
Apache APISIX后,发现Apache APISIX 可以完美替代 Spring Cloud Gateway和Nginx这种多层网关模式。Apache APISIX基于Nginx 无论如何封装 性能上都可吊打Spring Cloud Gateway。动态routes 动态Upstream 服务发现
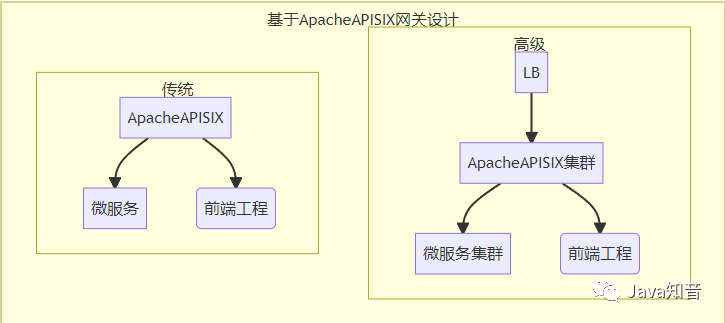
流量网关+业务网关的模式再也不存在了,现在只有一层流量网关,因为消除了Spring Cloud Gateway的存在 性能上略有提升,性能上面大概会提升2%-8%吧。2.2. 数据之小
FastJSON2)也只是从在解析速度上的提升后前端其实没有多少可以说的,HTTP协议很通用,JSON通讯格式也方便解析稍微主意一下几个问题就好了
后端不需要把null值给前端,前端仔自行处理undefined,null,NaN的问题 后端仔别一股脑 select *返回全部数据了,和前端确定好字段后定制化的返回所需要的字段JSON的key其实压缩一下,apple可以用a替代,user这个可以用u来替代, @JsonProperty这些注解之类的压缩一下key数据库字段尽可能使用小字段,少用宽表
微服务,微服务嘛看PRC框架了, Spring Cloud Open Feign或者dubbo这些都有自己的压缩算法的
response body,但是开启后CPU会上来,没有办法时间和空间问题。呃呃呃, 上面都是没有营养的东西,写偏题了(理科生啦没有办法就是文笔差劲)
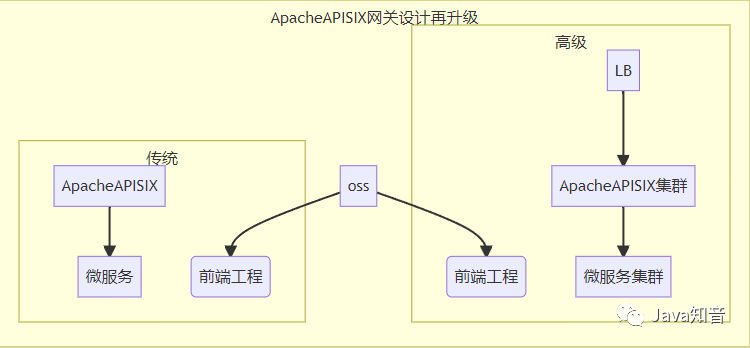
2.3. 架构之精
不谈金钱预算的架构师,架构的东西真的合理嘛。
架构真正的精髓在于如何设计出一个适合业务场景下最优的方案(最讨厌面试的时候让我去哈牛逼的面试官了,完全就不知道他的业务场景是什么,上来就说高并发如何设计那种。。。)
Elasticsearch才能加速商品检索,难道dbms就不能实现搜索引擎了嘛,当年Google都已经用dbsm实践出了dbms可以作为搜索引擎的的可能性(人家当年都上线用了好几年呐,只是数据量到了PB级别撑不住了),简单的技术+数据结构即可实现。GET github.com/goods/info
这个接口很常见吧,获取商品详情,网站一半以上的流量都是这个接口在作妖,下面来看看如何优化啦。
goods/info就是获取商品详情嘛,里面的数据除了商品数量,其他的数据一年半载基本上都是不会变化的,所以 数据动静分离一下
第一步呐:我们保留原有接口,但是 goods/info 这个加缓存
GET github.com/goods/info
第二步呐:增加一个接口,这个接口获取商品数量,加不加缓存都可以,加了缓存就做好缓存协商
GET github.com/goods/quantity
搞定,这样子info接口都是走缓存了,都是大字段现在都已经放在了缓存中基本上都不需要走服务端了,浏览器缓存和网关缓存基本上就拦截住了。
quantity接口因为变化速度太快了,也不知道什么时候变化,但是都是小字段,传输和数据库检索基本上没有什么压力。
对了,数据库也可以这样子拆分一下, goods表弄成两张,加一张quantity表和goods表做关联,完事了世界就是你的了
静态化,这个没有专门研究过,针对app和小程序无效只能用在web网页上面。2.4. 性能之悍
2.5. 短板效应
3. 手撕http缓存框架
https://github.com/galaxy-sea/heifer/tree/main/heifer/heifer-common/heifer-common-http
https://github.com/galaxy-sea/heifer/tree/main/heifer/heifer-examples/heifer-common-http-example
@GetMapping("cache/{id}")
@HttpCacheControl(key = "#id", maxAge = 10)
public String getCache(@PathVariable String id) {
return ResponseEntity.ok()
.body( new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date())
}})
;
}
@HttpCacheControl 会在 Response Header 上返回 Cache-Control: max-age=10 和 Etag: "403710060904730625"@PostMapping("cache/{id}")
@HttpETag(key = "#id")
public ResponseEntity<Map<String, String>> modify(@PathVariable String id) {
cacheService.modify(id);
return ResponseEntity.ok()
.body(new LinkedHashMap<String, String>() {{
put("data", "modify: " + id);
}})
;
}
@HttpETag主要用于刷新Etag标签4. 终章
推荐阅读:
互联网初中高级大厂面试题(9个G) 内容包含Java基础、JavaWeb、MySQL性能优化、JVM、锁、百万并发、消息队列、高性能缓存、反射、Spring全家桶原理、微服务、Zookeeper......等技术栈!
⬇戳阅读原文领取! 朕已阅
