
【Manning新书】隐私保护的机器学习

来源:专知 本文为书籍介绍,建议阅读5分钟 您将了解不同隐私保护技术背后的核心原理,以及如何将理论应用到您自己的机器学习中。


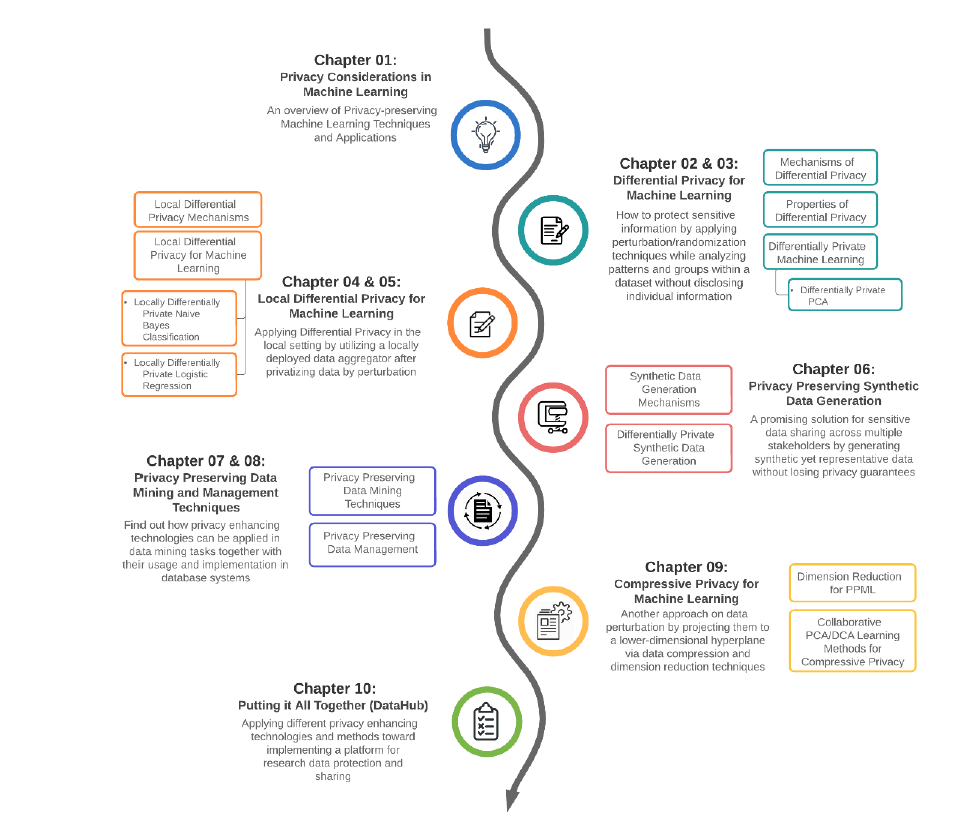
在重构攻击中,对手获得了外部知识的特征向量或用于构建ML模型的数据的优势。 重构攻击通常需要直接访问部署在服务器上的ML模型;我们称之为白盒访问。 有时,当用户提交新的测试样本和模型为给定样本生成的响应时,对手可以监听机器学习模型的传入请求,这可能导致模型反转攻击。 成员推理攻击是模型反转攻击的扩展版本,攻击者试图基于ML模型输出推断样本,以确定样本是否在训练数据集中。 即使数据集是匿名化的,对一个系统来说,可靠地保护数据隐私是一个挑战,因为攻击者可以利用后台知识推断数据,通过去匿名化或重新识别攻击。 将不同的数据库实例连接在一起,以探索个人的独特指纹,这是数据库系统中重大的隐私威胁之一。 差分隐私(DP)旨在通过在统计数据或聚合数据中添加随机噪声,保护个人的敏感信息免受针对个人统计数据或聚合数据的任何推断攻击。 本地差异隐私(LDP)是DP的本地设置,个人通过扰动将数据私有化后将数据发送到数据聚合器,因此,为个人提供了合理的推诿。 压缩隐私(CP)通过压缩和降维技术将数据投影到低维超平面,从而干扰数据。 合成数据生成是一种很有前途的数据共享解决方案,它生成和共享与原始数据格式相同的合成数据集,这为数据用户使用数据提供了更大的灵活性,而不用担心基于查询的隐私预算。 有不同的方法来实现隐私保护数据挖掘(PPDM),这些技术可以分为三大类:数据收集的隐私保护方法,数据发布,和修改数据挖掘输出。
评论