
齐活了,Grafana 发布大规模持续性能分析开源数据库 - Phlare
Grafana Phlare 是一个用于聚合 continuous profiling(持续分析)数据的开源软件项目。Grafana Phlare 可以和 Grafana 完全集成,允许你与其他可观察信号相关联。

什么是 continuous profiling?
这个概念很有价值:Profiling 可以帮助你了解程序的资源使用情况,进而帮助你优化其性能和成本。然而,向分布式云原生架构的转变使这变得更加复杂,从而产生了对持续分析的需求,其中有关资源使用情况的信息会在整个计算基础设施中定期自动收集,然后压缩并存储为时间序列数据,这使你可以可视化随时间的变化并放大与感兴趣的时间段相匹配的 profile 文件 — 例如,CPU 时间在其最高利用率期间所花费的时间。
就其带来的价值而言,持续分析被称为可观测的第四大支柱(在metrics、logging 和 tracing 之后)。
在 Grafana Labs,我们开始研究使用持续分析来了解我们用于支持 Grafana Cloud 的软件的性能,包括 Grafana Loki、Grafana Mimir、Grafana Tempo 和 Grafana。例如,如果我们对 Mimir 中的慢查询进行分页,我们可能会使用分析来了解该查询在 Mimir 代码库中的哪个位置花费的时间最多。如果我们看到 Grafana 由于内存不足错误而反复崩溃,我们将查看内存配置文件以查看崩溃前哪个对象消耗的内存最多。
虽然有用于存储和查询持续分析数据的开源项目,但经过一些调查,我们努力找到一个满足支持 Grafana Labs 所需级别的持续分析所需的可扩展性、可靠性和性能要求的项目。在全公司范围的黑客马拉松期间,一组工程师领导了该项目,该项目展示了与指标、日志和追踪连接时分析数据的价值,进一步增加了我们在所有环境中推出连续分析的渴望。
因此,我们决定着手创建一个用于持续分析遥测的数据库,基于使我们的其他开源可观察性后端 Loki、Tempo 和 Mimir 如此成功的设计原则:水平可扩展架构和对象存储的使用。
核心功能
Grafana Phlare 提供水平可扩展、高可用性、长期存储和分析数据查询。就像 Prometheus 一样,只需一个二进制文件即可轻松安装,无需其他依赖项。因为 Phlare 使用对象存储,你可以存储你需要的所有历史记录,而不会花很多钱。其原生多租户和隔离功能集可以为多个独立团队或业务部门运行一个数据库。Grafana Phlare 的核心功能如下所示:
易于安装:使用其单体模式,只需一个二进制文件即可启动并运行 Grafana Phlare,无需其他依赖项。在 Kubernetes 上,可以使用 Helm Chart 方式进行不同模式的部署。水平可扩展性:可以在多台机器上运行 Grafana Phlare,可以轻松扩展数据库以处理工作负载生成的分析量。高可用性: Grafana Phlare复制传入的 profiles 文件,确保在机器发生故障时不会丢失数据。这意味着你可以在不中断 profiles 文件摄取和分析的情况下进行 rollout。廉价、耐用的 profile 文件存储: Grafana Phlare使用对象存储进行长期数据存储,使其能够利用这种无处不在、经济高效、高耐用性的技术。它兼容多种对象存储实现,包括 AWS S3、谷歌云存储、Azure Blob 存储、OpenStack Swift,以及任何与 S3 兼容的对象存储。原生多租户: Grafana Phlare的多租户架构使你能够将数据和查询与独立的团队或业务部门隔离开来,从而使这些组可以共享同一个数据库。
架构
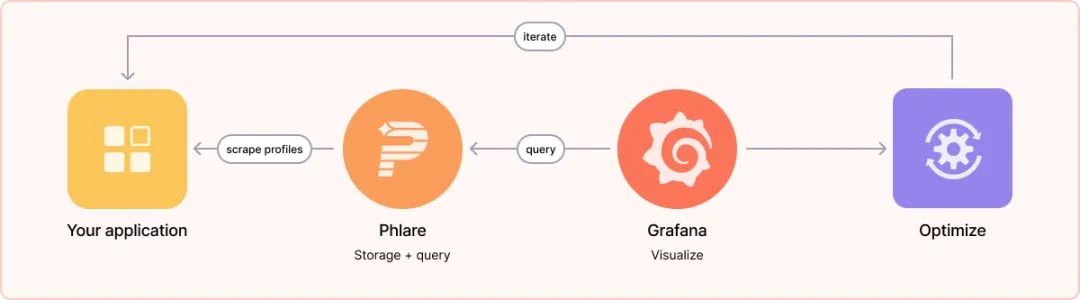
Grafana Phlare 具有基于微服务的架构,该系统具有多个可水平扩展的微服务,可以单独和并行运行。Grafana Phlare 微服务称为组件。Grafana Phlare 的设计将所有组件的代码编译为单个二进制文件。-target 参数控制单个二进制文件将作为哪些组件运行,这点和 Grafana Loki 的模式是一样的。对于想快速体验的用户来说,Grafana Phlare 同样也可以在单体模式下运行,所有组件在一个进程中同时运行。
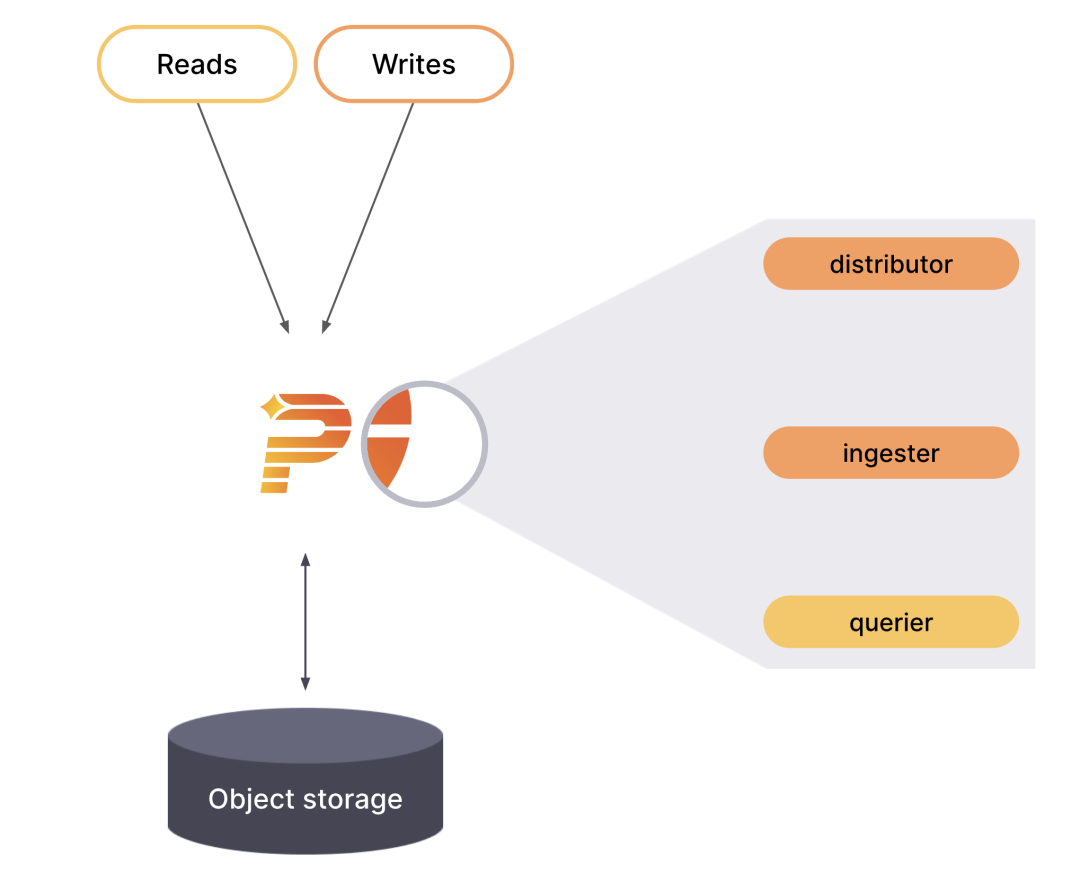
Grafana Phlare 的大多数组件是无状态的,不需要在进程重新启动之间保留任何数据。一些组件是有状态的,并依靠不容易丢失数据的存储来防止进程重启之间的数据丢失。Grafana Phlare 包括一组相互作用形成集群的组件:Distributor、Ingester、Querier。
单体模式
单体模式在单个进程中运行所有必需的组件,是默认的操作模式,你可以通过指定 -target=all 参数来设置,单体模式是部署 Grafana Phlare 的最简单方法,如果你想快速入门或想在开发环境中使用 Grafana Phlare,这将非常有用。要查看在 -target 设置为 all 时运行的组件列表,请使用 -modules 标志运行 Grafana Phlare:
./phlare -modules
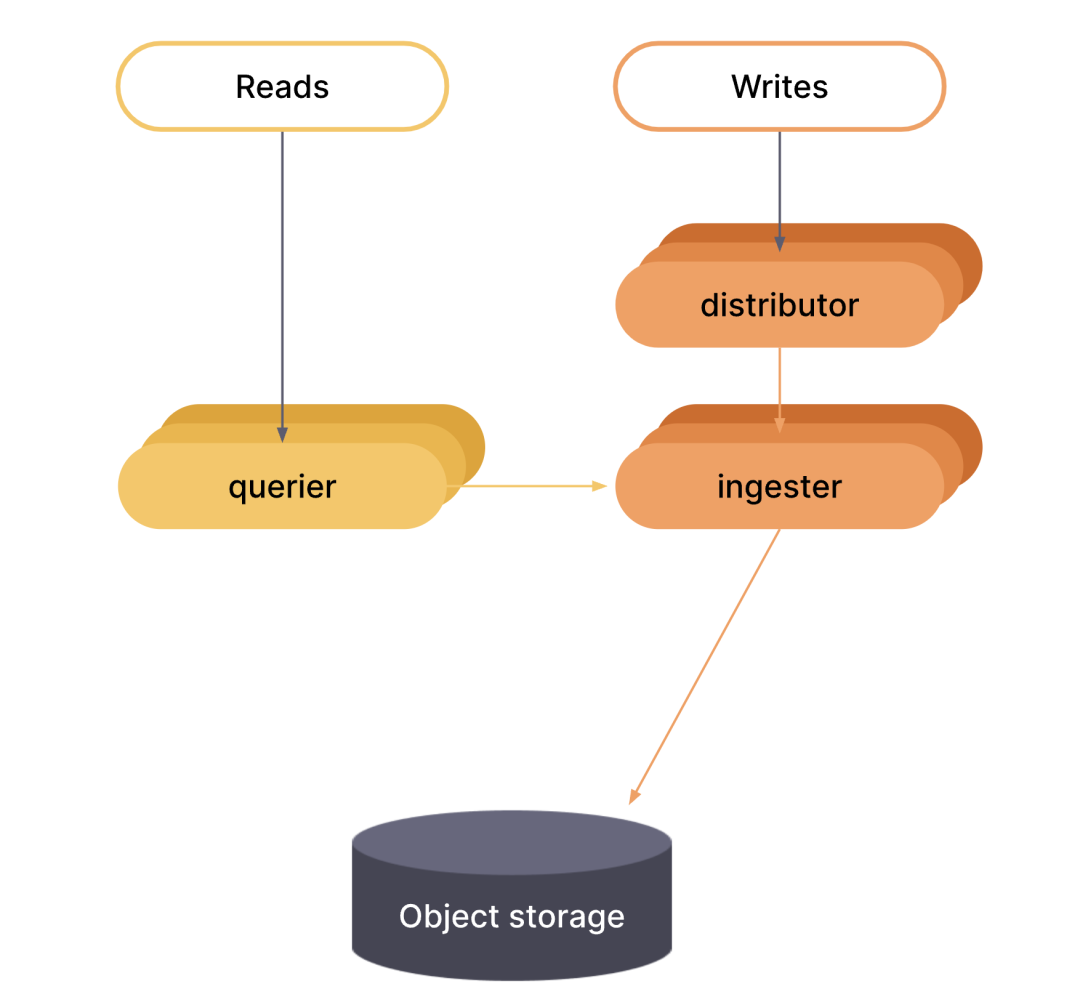
微服务模式
在微服务模式下,组件部署在不同的进程中。扩展是按组件进行的,这允许在扩展和更细化的故障域方面具有更大的灵活性。微服务模式是生产部署的首选方法,但也是最复杂的。
在微服务模式下,调用每个 Grafana Phlare 进程,并将其 -target 参数设置为特定的 Grafana Phlare 组件(例如,-target=ingester 或 -target=distributor)。要获得一个正常工作的 Grafana Phlare 实例,必须部署每个必需的组件。如果你想使用微服务模式部署 Grafana Phlare,那么非常建议使用 Kubernetes。
部署
我们这里还是以 Helm Chart 的方式部署在 Kubernetes 集群中,当然前提是有一个可用的 Kubernetes 集群,并且配置好了 kubectl 和 helm。
首先我们创建一个名为 phlare-test 的命名空间,将整个应用都部署在该命名空间之内:
☸ ➜ kubectl create namespace phlare-test
然后添加 Phlare 的 Helm Chart 仓库:
☸ ➜ helm repo add grafana https://grafana.github.io/helm-charts
☸ ➜ helm repo update
然后我们就可以使用 Helm 来进行安装了。
如果你想以单体默认进行安装,只需要执行下面的命令即可一键安装:
☸ ➜ helm -n phlare-test install phlare grafana/phlare
如果想以微服务模式安装 Grafana Phlare,可以首先获取官方提供的默认 values 配置文件:
# 收集微服务的默认配置
☸ ➜ curl -LO values-micro-services.yaml https://raw.githubusercontent.com/grafana/phlare/main/operations/phlare/helm/phlare/values-micro-services.yaml
☸ ➜ cat values-micro-services.yaml
# Default values for phlare.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
phlare:
components:
querier:
kind: Deployment
replicaCount: 3
resources:
limits:
memory: 1Gi
requests:
memory: 256Mi
cpu: 100m
distributor:
kind: Deployment
replicaCount: 2
resources:
limits:
memory: 1Gi
requests:
memory: 256Mi
cpu: 500m
agent:
kind: Deployment
replicaCount: 1
resources:
limits:
memory: 512Mi
requests:
memory: 128Mi
cpu: 50m
ingester:
kind: StatefulSet
replicaCount: 3
resources:
limits:
memory: 12Gi
requests:
memory: 6Gi
cpu: 1
minio:
enabled: true
我们需要使用上面的 values 文件来安装 Grafana Phlare,也可以根据自己的集群实际情况调整配置,比如 ingester 配置的资源请求的 memory: 6Gi,cpu: 1,我这里集群资源不足,可以将其降低一些,将副本数都暂时设置成1(仅供测试),不然没办法调度成功。
然后使用下面的命令即可开始安装:
☸ ➜ helm -n phlare-test upgrade --install phlare grafana/phlare -f values-micro-services.yaml
Release "phlare" does not exist. Installing it now.
NAME: phlare
LAST DEPLOYED: Thu Nov 3 14:37:38 2022
NAMESPACE: phlare-test
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Thanks for deploying Grafana Phlare.
In order to configure Grafana to use the Phlare datasource, you need to add the Phlare datasource to your Grafana instance.
The in-cluster query URL is:
http://phlare-querier.phlare-test.svc.cluster.local.:4100
To forward the query API to your localhost you can use:
kubectl --namespace phlare-test port-forward svc/phlare-querier 4100:4100
部署完成后查看 Pod 状态是否正常:
☸ ➜ kubectl get pods -n phlare-test
NAME READY STATUS RESTARTS AGE
phlare-agent-56986dd4b9-4s6z6 1/1 Running 0 3m23s
phlare-distributor-7447b4c6c5-f4rjw 1/1 Running 0 3m23s
phlare-ingester-0 1/1 Running 0 3m23s
phlare-minio-0 1/1 Running 0 3m23s
phlare-querier-8cdf986c-hhn29 1/1 Running 0 3m23s
等到所有 Pod 的状态变为 Running 或 Completed 表示部署完成了。
使用
然后接下来我们可以配置 Grafana 来查询 profiles 数据,这里我们在安装 Phlare 的同一个 Kubernetes 集群中安装 Grafana,同样使用下面的命令一键安装即可:
☸ ➜ helm template -n phlare-test grafana grafana/grafana \
--set image.repository=aocenas/grafana \
--set image.tag=profiling-ds-2 \
--set env.GF_FEATURE_TOGGLES_ENABLE=flameGraph \
--set env.GF_AUTH_ANONYMOUS_ENABLED=true \
--set env.GF_AUTH_ANONYMOUS_ORG_ROLE=Admin \
--set env.GF_DIAGNOSTICS_PROFILING_ENABLED=true \
--set env.GF_DIAGNOSTICS_PROFILING_ADDR=0.0.0.0 \
--set env.GF_DIAGNOSTICS_PROFILING_PORT=6060 \
--set-string 'podAnnotations.phlare\.grafana\.com/scrape=true' \
--set-string 'podAnnotations.phlare\.grafana\.com/port=6060' > grafana.yaml
☸ ➜ kubectl apply -f grafana.yaml
部署完成后整个 phlare-test 命名空间的 Pod 列表如下所示:
☸ ➜ kubectl get pods -n phlare-test
NAME READY STATUS RESTARTS AGE
grafana-5ff87bdfd-whmkm 1/1 Running 0 85s
phlare-agent-56986dd4b9-4s6z6 1/1 Running 0 9m17s
phlare-distributor-7447b4c6c5-f4rjw 1/1 Running 0 9m17s
phlare-ingester-0 1/1 Running 0 9m17s
phlare-minio-0 1/1 Running 0 9m17s
phlare-querier-8cdf986c-hhn29 1/1 Running 0 9m17s
我们可以使用下面的命令在本地转发 Grafana 服务:
☸ ➜ kubectl port-forward -n phlare-test service/grafana 3000:80
然后在浏览器中打开 http://localhost:3000 即可访问 Grafana 服务了。
在页面左侧点击配置 -> 数据源来添加 profiles 的数据源,选择 phlare 类型的数据源。

设置数据源的 URL 为 http://phlare-querier.phlare-test.svc.cluster.local.:4100/。
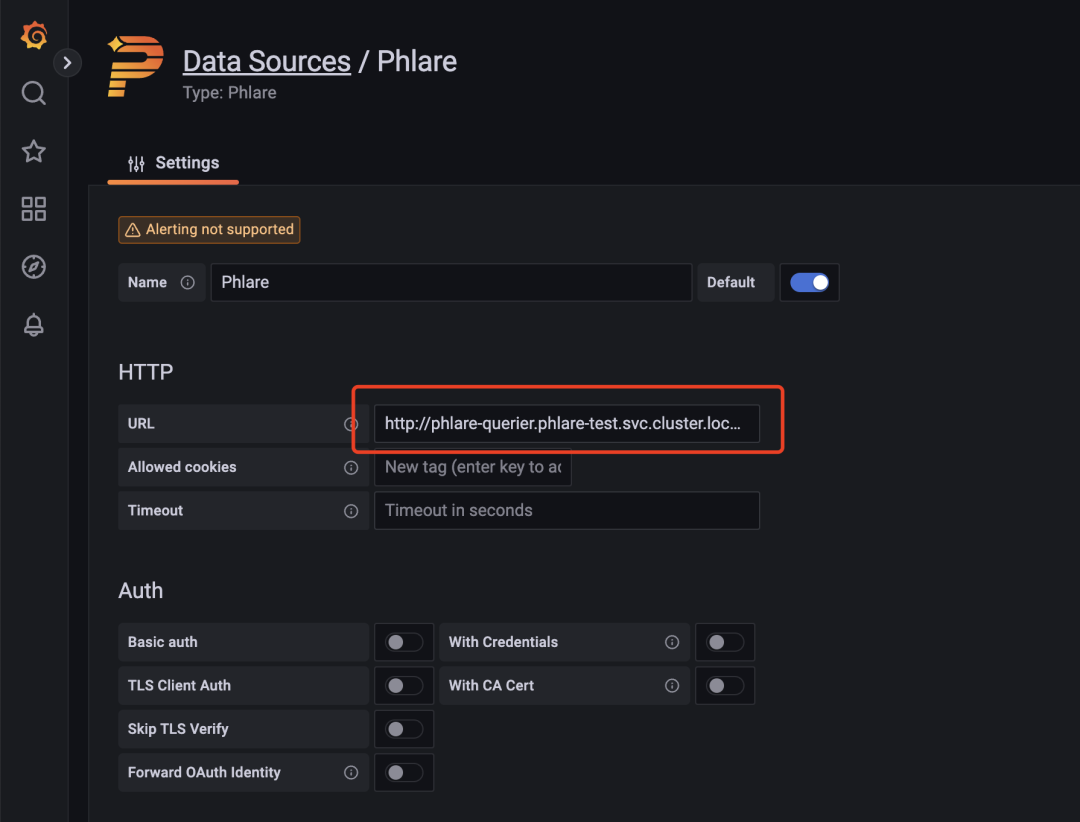
点击 Save & Test 即可保存。数据源添加完成后应该能够在 Grafana Explore 中查询到 profiles 文件,使用方法和 Loki 以及 Prometheus 几乎一样,如下所示我们可以查询 Grafana 应用的 CPU 的情况。
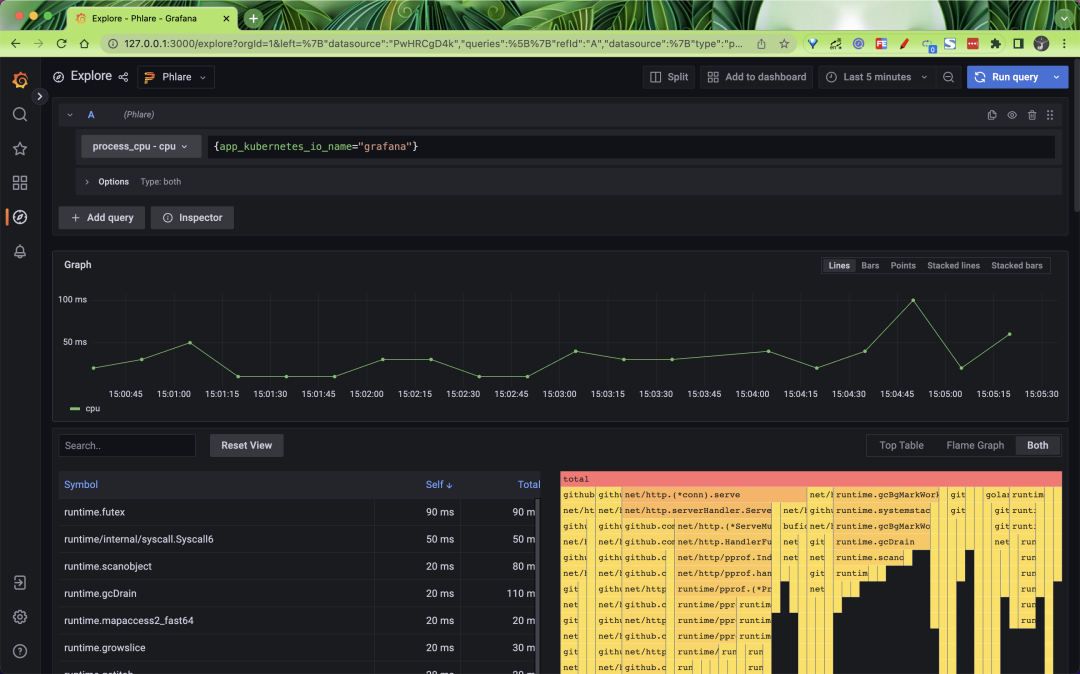
Phlare 与 Grafana 原生集成,使你可以将 profiles 数据与 metrics、logging 和 tracing 一起可视化,并全面了解整个堆栈。我们还在 Grafana 中添加了一个火焰图面板,它允许你构建仪表板,在 Grafana 中可视化的数百个不同数据源的数据旁边显示分析数据。
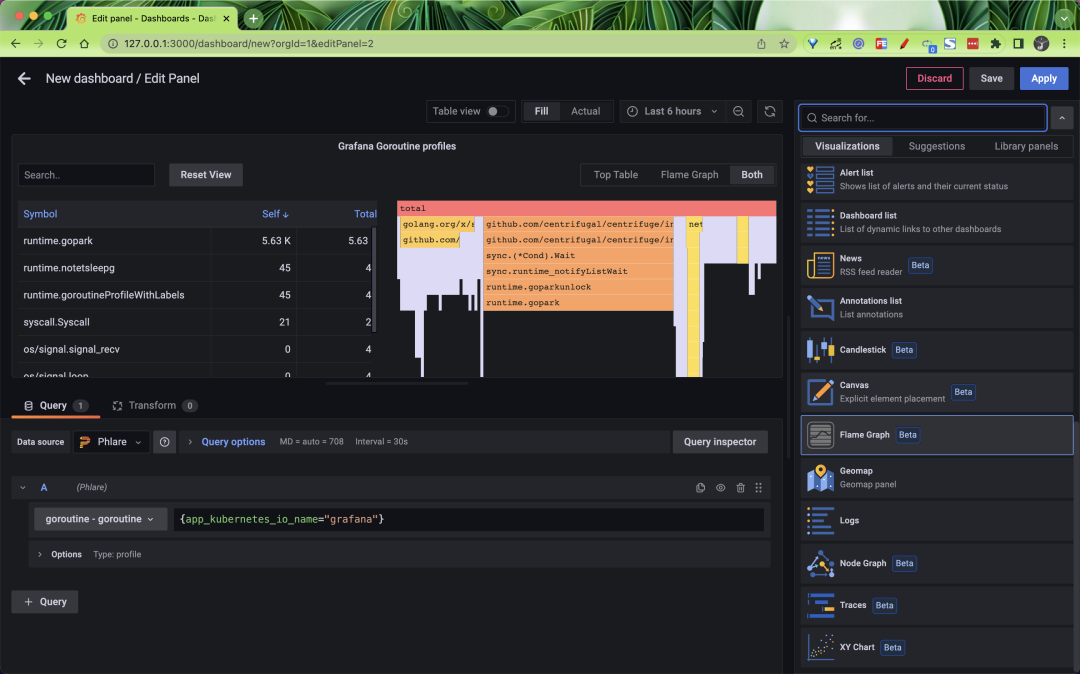
Phare 的 Helm Chart 使用默认配置,只要它们有正确的注解,它的代理就会抓取 Pod,该功能使用可能与 Prometheus 或 Grafna Agent 配置相似的 relabel_config 和 kubernetes_sd_config。
为了让 Phlare 抓取 pod,你必须在 pod 中添加以下注解:
metadata:
annotations:
phlare.grafana.com/scrape: "true"
phlare.grafana.com/port: "8080"
其中 phlare.grafana.com/port 应该设置为你的 pod 为 /debug/pprof/ 端点提供服务的端口。请注意,phlare.grafana.io/scrape 和 phlare.grafana.io/port 的值必须用双引号括起来,以确保它表示为字符串。
上面我们在安装 Grafana 的时候就配置了这两个注解,所以我们就可以使用 Phlare 来不断的抓取 Grafana 应用的 profiles 数据了,这也是为什么上面我们可以去过滤 Grafana 的 profiles 数据的原因。
参考链接
https://github.com/grafana/phlare https://grafana.com/blog/2022/11/02/announcing-grafana-phlare-oss-continuous-profiling-database/
▲ 点击上方卡片关注K8s技术圈,掌握前沿云原生技术